本文主要是介绍前复权、后复权,技术分析看哪个?价值投资呢?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
先说结论,
前复权可以实现技术指标的连续性,适合技术分析,
后复权可以实现股价走势的连续性,适合价值投资者

从头来说,一家公司盈利后,可以选择用盈利购买新的生产设备或者拓展生产,但是如果商业模式已经比较固定或者市场已经接近饱和,短期没有好的再投资机会,这时候公司选择“分红”。
这会导致在分红的时间点前后,同样一股的股票所对应的资产价值突然变化比较大(有点像函数不连续)。同样的股票价值突然变化,在股票分红或者股票拆分的时候也会出现。
举个例子,比如10送10,上市公司在送股后,股票的数量变多,但是股票价值不变,股价变低,在K线图上出现一个缺口,这个缺口叫【除权】。除权后,股价发生了变化,但实际成本没变,如果我们要想知道股票的真实价格就需要对股票进行【复权】。
复权就是对股价和成交量进行权息修复,按照股票的实际涨跌绘制股价走势图,并把成交量调整为相同的股本口径,然后用相同成本进行比较。复权可以消除由于除权除息造成的价格走势畸变,保持股价走势的连续性。
所谓不复权,就是除权后,不人工填补股价走势图上的巨大空隙,任由断层存在。
以花园生物(300401)为例,根据年初的高送转方案,每10股均送转15股,5月4日实施后,股价从50元跌至20.35元。下图一是不复权的走势图,在5月4日股价呈现断崖式下跌。
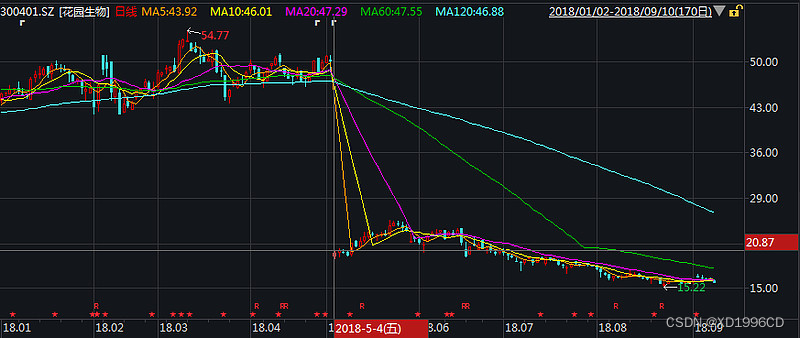
【图一:花园生物5月4日除权后不复权
前复权是把除权前的价格按现在的价格换算过来,复权后现在价格不变,以前的价格减少。
【图二:花园生物前复权走势】

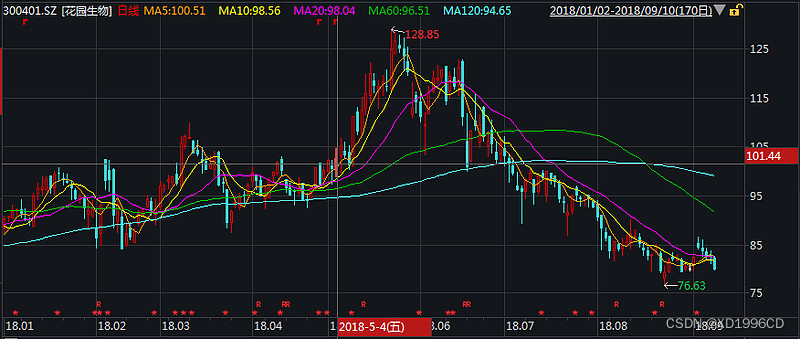
后复权是把除权后的价格按以前的价格换算过来,复权后以前的价格不变,现在的价格增加。通过后复权我们可以看出该股上市以来累计涨幅,如果当时买入,参与全部配送、分红,一直持有到目前的价位。
【图三:花园生物后复权走势】
这里多说一句定点复权,是指以某一天价格点位为参照物,进行的前复权或后复权。
二、不复权、前复权、后复权的用途
不复权的话,K线图能真实反应股价历史的除权信息,缺点是会留有大缺口,均线系统被打乱。
前复权以目前价为基准复权,可以很清楚的看到成本分布情况,如相对最高、最低价,成本密集区域,以及目前股价所处的位置是高还是低。如果进行技术分析,最好用前复权,这样当前的价格是最新的实际价格,且K线均线的走势是连续性的,不影响看盘。
后复权保持上市第一天的价格不变,根据分红配股数据处理之后的价格,这会导致最后一天的价格显示出来不是实际成交价,但可以看出股票真实价值的增加及持股者的真实收益率。如果进行价值投资,建议采用后复权,这样计算的收益率是相对正确的,查询也比较直观。
三、总结
综上所述,前复权可以实现技术指标的连续性,后复权可以实现股价走势的连续性,不复权则可以直观显示出股价除权除息后是填权还是贴权的走势。
多说一句,填权主要指在除权除息后的一段时间里,如果多数人对该股看好,该只股票交易市价高于除权(除息)基准价,这种行情称为填权。贴权是指在除权除息后的一段时间里,交易市价低于除权(除息)基准价,即股价比除权除息日的收盘价有所下降。本文选取的花园生物案例在除权后走出的是填权行情
这篇关于前复权、后复权,技术分析看哪个?价值投资呢?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







