本文主要是介绍推荐系统三十六式学习笔记:原理篇.内容推荐06|超越标签的内容推荐系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 为什么要做好内容推荐?
- 内容源
- 内容分析和用户分析
- 内容推荐算法
- 总结:
基于内容的推荐系统,有个误区,衡量其性能优劣,评判标准是标签数量够不够。其实标签只是很小一部分。而且即便是标签,衡量质量的方式也不是数目够不够;所以,今天我要讲的内容,就是脱离标签定式思维的内容推荐;
为什么要做好内容推荐?
通常一个复杂的推荐系统很可能是从基于内容推荐成长起来的。可以说基于内容的推荐系统是一个推荐系统的孩童时代,我们就来讲一讲如何养成一个基于内容的推荐系统;
为什么基于内容的推荐系统那么重要呢?因为内容数据非常易得,用心找的话总能找到一些可以使用的内容,不需要有用户行为数据就能够做出推荐系统的第一版;内容数据尤其是文本,只要深入挖掘,就可以挖掘出一些很有用的信息供推荐系统使用。
内容推荐的方式还有它的必要性。推荐系统总是需要接入新的物品,这些新的物品在一开始没有任何展示机会,显然就没有用户反馈,这时候只有内容能帮它。基于内容的推荐能把这些新物品找机会推荐出去,从而获得一些展示机会,积累用户反馈,走上巅峰、占据热门排行榜。
要把基于内容的推荐做好,需要做好“抓、洗、挖、算”四门功课。它们分别对应了下面的内容。
1、抓:做好一个基于内容的推荐系统抓取数据补充内容源,增加分析的维度,必不可收。
2、洗:抓取的数据需过滤冗余的数据,垃圾数据,政治色情等敏感数据;
3、挖:不是是抓来的数据,还是自己的数据,要深入挖掘。很多推荐系统提升效果并不是用了更复杂的推荐算法,而是对内容的挖掘做的更深入。
4、算:匹配用户的兴趣和物品的属性,计算出更合理的相关性,这是推荐系统本身的使命,不仅仅是基于内容的推荐才要做的
那么,这四门课到底如何分布在基于基于内容的推荐系统中呢?
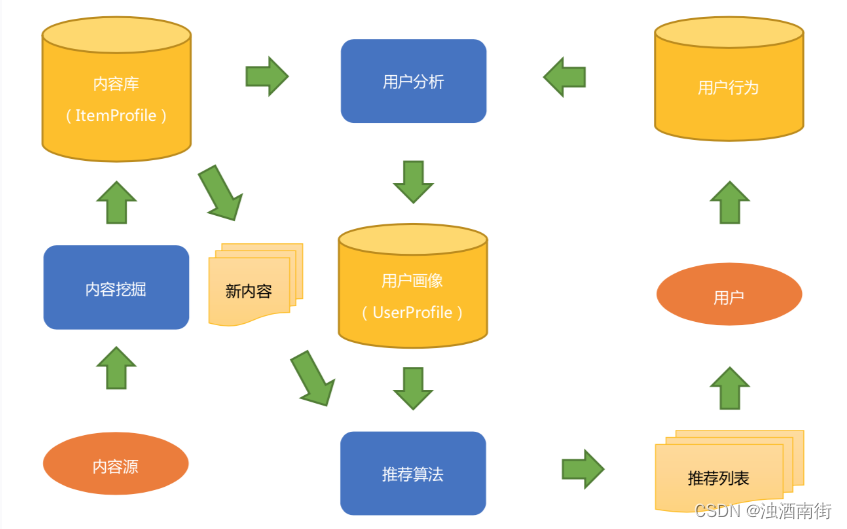
简要介绍一下这张图的流程和基本元素。
内容这一端:内容源经过内容分析,得到结构化的内容库和内容模型,也就是物品画像。用户这一端:用户看过推荐列表后,会产生用户行为数据,结合物品画像,经过用户分析得到用户画像。
对于那些没有给用户推荐过的新内容,经过相同的内容分析过程后就可以经过推荐算法匹配,计算得到新的推荐列表给用户。如此周而复始,永不停息。
内容源
在互联网中,抓数据是一件可做不可说的事。只有当内容有多样性了,一个推荐系统才有存在的合法性。
爬虫技术本身非常复杂,非常有学问,这里就不展开了。
不论是爬过来的数据还是自己的数据,都少不了内容的清洗,主要是去重并过滤垃圾信息及政治、暴力、色情等敏感信息。
内容分析和用户分析
基于内容的推荐,最重要的不是推荐算法,而是内容挖掘与分析。
如果推荐物品是短视频,我们分几种情况看:
1、如果短视频本身没有任何结构化信息,如果不挖掘内容,那么除了强推或者随机小流量,没有别的合理曝光逻辑了;
2、如果对视频的文本描述,比如标题等能够有内容分类,比如是娱乐类,那么对于喜欢娱乐的用户来说就很合理;
3、如果能够进一步分析文本的主题,那么对于类似主题感兴趣的用户就可能得到展示。
4、如果还能识别出内容中主角是沈腾,那就更精准锁定一部分用户了;
5、如果再对内容本身做到嵌入分析,那么潜藏的语义信息也全部抓走了,更能表达内容了。
结构化的内容库,最重要的用途是结合用户反馈行为去学习用户画像,具体的方法上一篇中已经介绍了。容易被忽略的是第二个用途,
在内容分析过程中得到的模型:比如说
1、分类器模型
2、主题模型
3、实体识别模型
4、嵌入模型
这些模型主要用在:当新的物品刚刚进入时,需要实时地被推荐出去,这时候对内容的实时分析,提取结构化内容,再用于用户画像匹配。
内容推荐算法
对于基于内容的推荐系统,最简单的推荐算法当然是计算相似性即可,用户的画像内容就表示为稀疏的向量,同时内容端也有相应的稀疏向量,两者之间计算余弦相似度,根据相似度对推荐物品排序;如果你内容分析做的深入的话,通常效果还是蛮不错的,这种基于内容的推荐天然一个优点:可解释性非常强。
如果再进一步,要更好的利用内容中的结构化信息,因为一个直观的认识是:不同的字段重要性不同。比如说,一篇新闻,标题和正文分析出同一个人物名,评论里面涉及一些其他人物名,可以用于推荐。直观上新闻的正文和标题中的更重要。我们可以借鉴信息检索中的相关性计算方法来做推荐匹配计算:BM25F算法;
前面提到的两种办法可以做到快速实现、快速上线,但都不属于机器学习方法,那么,按照机器学习思路该怎么做呢?
一种最典型的场景:提高某种行为的转化率,如点击、收藏、转发。那么标准的做法是:收集这类行为的日志数据,转换成训练样本,训练预估模型。
每一条样本由两部分构成:一部分是特征,包含用户端的画像内容,物品端的结构化内容,可选的还有日志记录时一些上下文场景信息,如时间、地理位置、设备等等,另一部分就是用户行为,作为标注信息,包含有反馈和无反馈两类。
用这样的样本训练一个二分类器,常用模型是逻辑回归(Logistic Regression)和梯度提绳树(GBDT)或者两者的结合。在推荐匹配时,预估用户行为发生的概率,按找概率排序。这样更合理更科学,而且这一条路可以一直迭代优化下去。
总结:
基于内容的推荐一般是推荐系统的起步阶段,而且会持续存在。它的重要性不可取代。因为:
1、内容数据始终存在并且蕴含丰富的信息量,不好好利用属实可惜。
2、产品冷启动阶段,没有用户行为,别无选择。
3、新的物品要被推荐出去,首选内容推荐。
基于内容的整体框架也是比较清晰的,其中对内容的分析最为重要,推荐算法这一款可以考虑先使用相似度计算,也可以采用机器学习思路训练预估模型,当然这必须得有大量的用户行为做保证;
这篇关于推荐系统三十六式学习笔记:原理篇.内容推荐06|超越标签的内容推荐系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






