本文主要是介绍Spark安装、解压、配置环境变量、WordCount,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Spark
小白的spark学习笔记 2024/5/30 10:14
文章目录
- Spark
- 安装
- 解压
- 改名
- 配置spark-env.sh
- 重命名,配置slaves
- 启动
- 查看
- 配置环境变量
- 工作流程
- maven
- 创建maven项目
- 配置maven
- 更改pom.xml
- WordCount
- 按照用户求消费额
- 上传到spark集群上运行
安装
上传,直接拖拽
解压
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /usr/local/
改名
cd /usr/local
mv spark-2.1.1-bin-hadoop2.7/ sparkcd spark/conf
mv spark-env.sh.template spark-env.sh
配置spark-env.sh
vi spark-env.sh
在该配置文件中添加如下配置
export JAVA_HOME=/usr/local/jdk
export SPARK_MASTER_IP=centos1
export SPARK_MASTER_PORT=7077 master work通信用
保存退出

上面三条分别是
jdk的位置
主机名(查询主机名hostname)
端口
重命名,配置slaves
mv slaves.template slaves
vi slaves
在该文件中添加子节点所在的位置(Worker节点)
将配置好的Spark拷贝到其他节点上
启动
命令也是start-all.sh,跟Hadoop的启动命令冲突,所以改一下名
在/usr/local/spark/sbin下
mv start-all.sh start_all.sh
mv stop-all.sh stop_all.sh
查看
启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://centos1:8080/
配置环境变量
vim /etc/profile
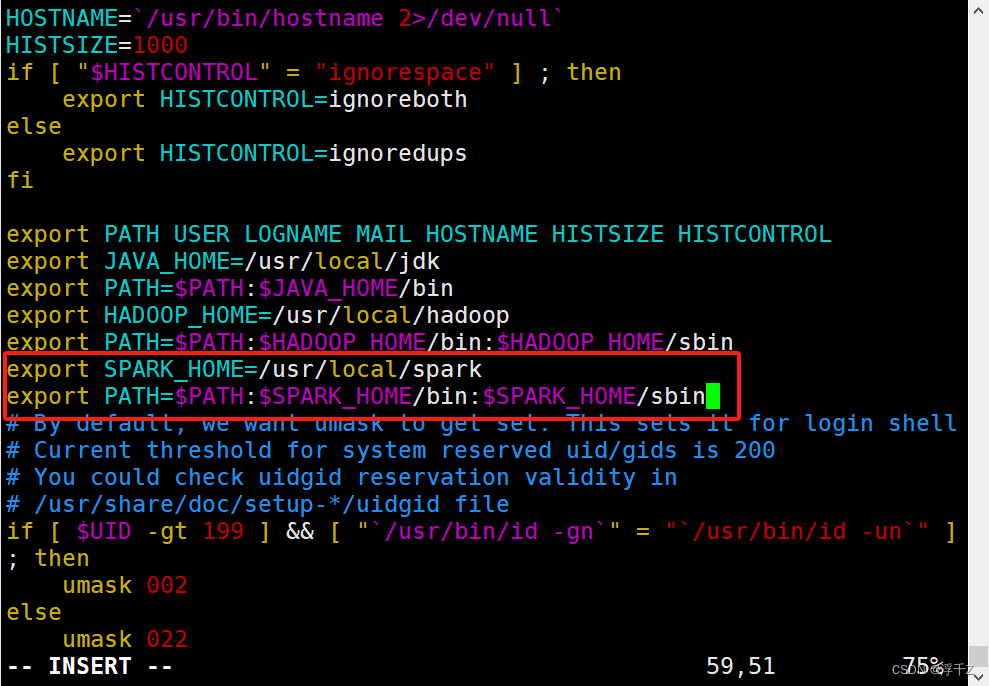
source /etc/profile
工作流程
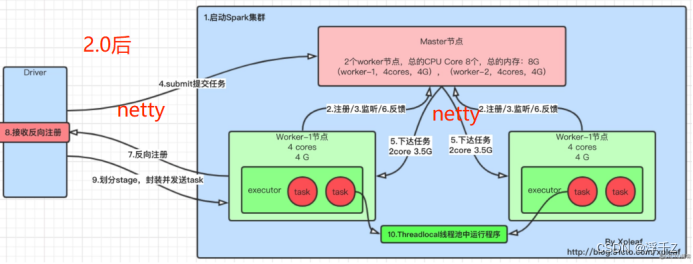
maven
下载jar,根据groupid,artifactld,version
创建maven项目
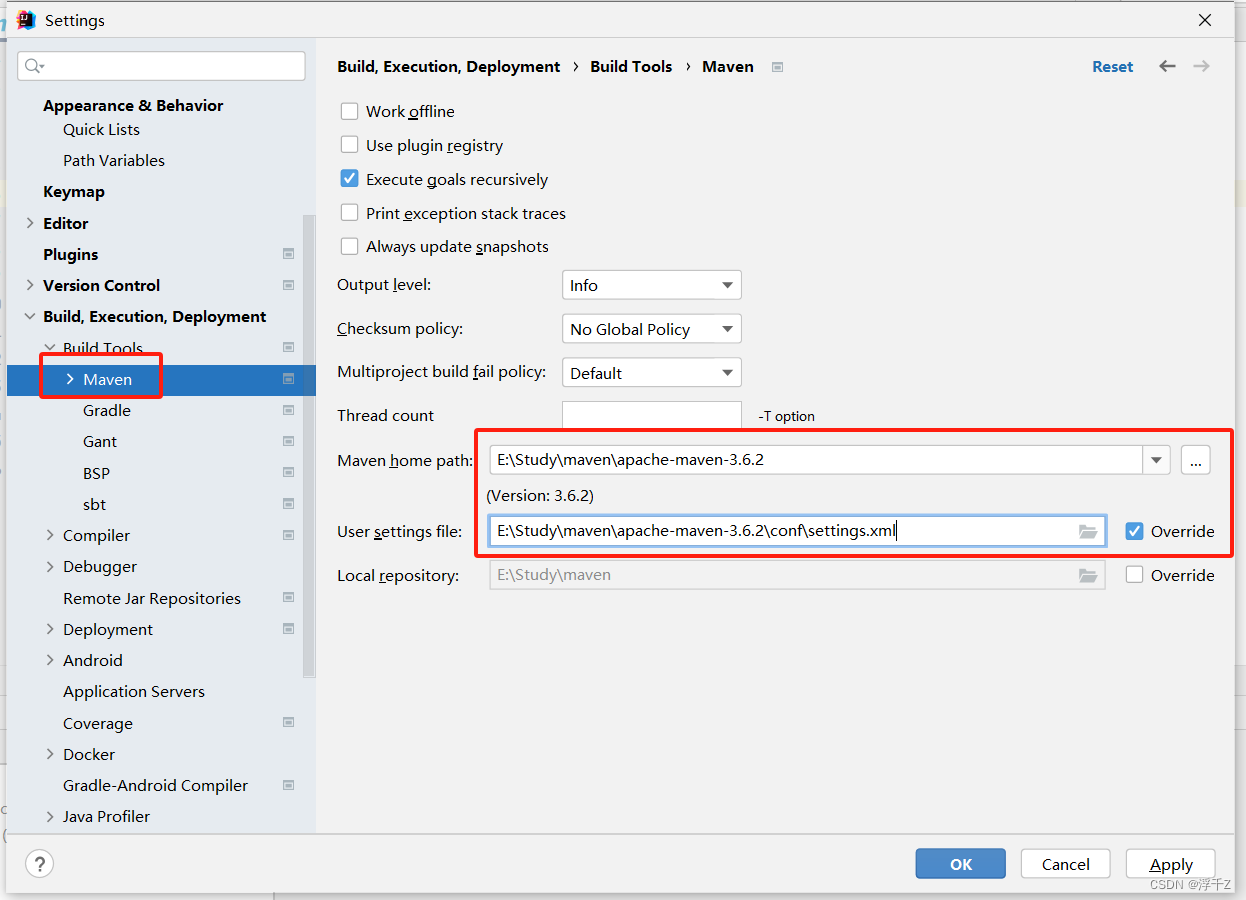
配置maven
更改pom.xml
WordCount
求单词出现次数
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSessionobject HelloWorld {def main(args: Array[String]): Unit = {val config=new SparkConf()//是用来创建spark上下文driverval spark=SparkSession.builder().master("local[*]").config(config).appName("hello").getOrCreate()val rddLine: RDD[String] = spark.sparkContext.textFile("D:\\Study\\Hadoop\\input\\word.txt")//求单词出现的次数//1.
// rddLine.flatMap(x=>x.split(" ")).map(x=>(x,1)).groupByKey().map(x=>(x._1,x._2.sum)).foreach(x=>println(x))
// rddLine.flatMap(x=>x.split(" ")).map(x=>(x,1)).groupByKey().foreach(x=>println(x+"-----bkbk"))
// //这个groupByKey方法直接按照key来分组,后面的集合是key对应的值的集合
// //(ss,CompactBuffer(1, 1))-----bkbk//2.用reduce直接做rddLine.flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).foreach(x=>println(x))}
}
按照用户求消费额
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
//数据如下
//1,2020-12-12,10
//1,2020-12-13,16
//2,2020-12-12,89
//2,2020-12-13,22
object SumByUser {def main(args: Array[String]): Unit = {val conf=new SparkConf()val spark=SparkSession.builder().master("local[*]").config(conf).appName("hello").getOrCreate()//创建spark上下文driverval rddLine: RDD[String] = spark.sparkContext.textFile("D:\\Study\\Hadoop\\input\\sumbyuser.txt")//文件读入地址//按","分割,取第一列和第三列,reducebykeyrddLine.map(x=>x.split(",")).map(x=>(x(0),x(2).toInt)).reduceByKey((x,y)=>x+y).foreach(x=>println(x))}
}上传到spark集群上运行
代码中去掉master,改一下文件读入路径
打包
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
//数据如下
//1,2020-12-12,10
//1,2020-12-13,16
//2,2020-12-12,89
//2,2020-12-13,22
object SumByUser {def main(args: Array[String]): Unit = {val conf=new SparkConf()//如果提交到spark集群上运行,就不需要master,文件地址也要改val spark=SparkSession.builder().config(conf).appName("hello").getOrCreate()//创建spark上下文driverval rddLine: RDD[String] = spark.sparkContext.textFile(args(0))//文件读入地址//按","分割,取第一列和第三列,reducebykeyrddLine.map(x=>x.split(",")).map(x=>(x(0),x(2).toInt)).reduceByKey((x,y)=>x+y).foreach(x=>println(x))}
}
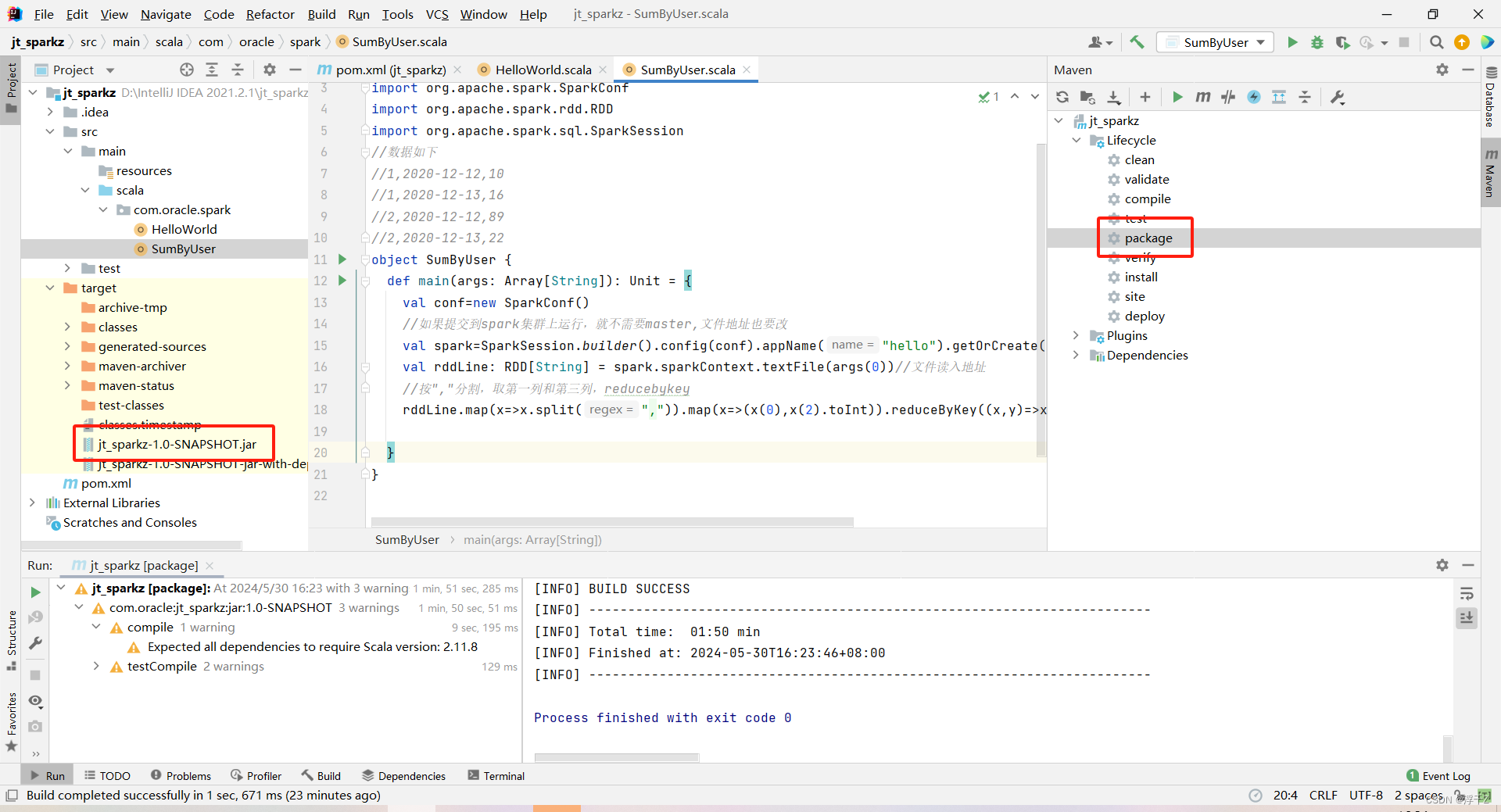
把jar和数据传到虚拟机上
执行
类名、master、内存大小、核的个数、jar的名、数据的名
spark-submit --class com.oracle.spark.SumByUser --master spark://centos1:7077 --executor-memory 500M --total-executor-cores 2 jt_sparkz-1.0-SNAPSHOT-jar-with-dependencies.jar sumbyuser.txt
类名
这篇关于Spark安装、解压、配置环境变量、WordCount的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







