本文主要是介绍Spring Boot 系统学习第四天:Spring循环依赖案例分析 备份,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 概述
在前面介绍三种不同的依赖注入类型时,引出了使用Spring IoC容器时一个常见问题,即循环依赖。同时也明确了在单例作用域下,Setter方法注入能够解决循环依赖问题,而构造器注入则不能。对于单例作用域来说,Spring容器在整个生命周期内,有且只有一个Bean对象,所以很容易想到这个对象应该存在于缓存中。Spring为了解决单例Bean的循环依赖问题,使用了三级缓存。这是Spring在设计和实现上的一大特色。
2 三级缓存结构
所谓三级缓存,在Spring中表现为三个Map对象,这三个对象定义在DefaultSingletoBeanRegister类中,该类时DefaultListableBeanFactory的父类。以下源码为DefaultSingletonBeanRegister中的三级缓存Map定义代码。
//单例对象的缓存private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);//单例对象工厂的缓存private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);//提前暴露的单例对象的缓存private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);请注意,这里的singletonObjects变量就是第一级缓存,用来持有完成的Bean实例。而earlySingletonObjects中存在的那些提前暴露的对象,也就是已经创建但还没有完成属性注入的对象,属于第二级缓存。最后的singletonFactory存放用来创建earlySingletonObject的工厂对象,属于第三级缓存。
那么,三级缓存是如何发挥作用的呢?让我们来分析获取Bean的代码流程。
protected Object getSingleton(String beanName, boolean allowEarlyReference) {//首先从一级缓存singletonObjects中获取Object singletonObject = this.singletonObjects.get(beanName);//如果获取不到,就从二级缓存earlySingletonObjects中获取if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null && allowEarlyReference) {synchronized (this.singletonObjects) {// 如果还获取不到,就从三级缓存singletonFactory中获取singletonObject = this.singletonObjects.get(beanName);if (singletonObject == null) {singletonObject = this.earlySingletonObjects.get(beanName);if (singletonObject == null) {ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {//一旦获取成功,就把对象从三级缓存移动到第二级缓存中singletonObject = singletonFactory.getObject();this.earlySingletonObjects.put(beanName, singletonObject);this.singletonFactories.remove(beanName);}}}}}}return singletonObject;}看了这段代码,不难理解对三级缓存的一次访问过程,但可能还是不理解Spring为什么要这样设计。事实上,解决循环依赖的关键还是要围绕Bean的生命周期。在前面介绍Bean的实例化时,我们知道它包含三个核心步骤,而在第一步和第二部之间,存在一个addSingletonFactory()方法,源码如下:AbstractAutowireCapableBeanFactory类的doCreateBean方法
//1 初始化Bean,通过构造器创建Bean
instanceWrapper = createBeanInstance(beanName, mbd, args);
//针对循环依赖问题暴露单例工厂类
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
//2.初始化Bean实例,完成Bean实例的完整创建
populateBean(beanName, mbd, instanceWrapper);Spring解决循环依赖的诀窍就在于singletonFactories这个第三级缓存,上面的addSingletonFactory方法用于初始化这个第三级缓存中的数据,代码如下:
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {Assert.notNull(singletonFactory, "Singleton factory must not be null");synchronized (this.singletonObjects) {if (!this.singletonObjects.containsKey(beanName)) {//添加到Bean到第三级缓存this.singletonFactories.put(beanName, singletonFactory);this.earlySingletonObjects.remove(beanName);this.registeredSingletons.add(beanName);}}}请注意,这段代码的执行时机是在已经通过构造函数创建Bean,但还没有完成对Bean中完成属性的注入的时候。换句话说,Bean已经可以被暴露出来进行识别了,但还不能正常使用。接下来我们就来分析一下为什么通过这种机制就能解决循环依赖问题。
3 循环依赖解决方案
让我们回顾前面分析的Setter方法注入的循环依赖场景,代码如下:
public class ClassA {private ClassB classB;@Autowiredpublic void setClassB(ClassB classB){this.classB = classB;}
}
public class ClassB {private ClassA classA;@Autowiredpublic void setClassA(ClassA classA){this.classA = classA;}
}现在假设我们先初始化ClassA。ClassA首先通过createBeanInstance()方法创建了实例,并且将这个实例提前暴漏到第三级缓存singletonFactories中。然后,ClassA尝试通过populateBean()方法注入属性,发现自己依赖ClassB这个属性,就会尝试去获取ClassB的实例。
显示,这时候ClassB还没有被创建,所以要走创建流程。ClassB在初始化第一步的时候发现自己依赖ClassA,就会尝试从第一级缓存singletonObjects中去获取ClassA的实例。因此ClassA这时候还没有被创建完毕,所以它在第一级缓存和第二级缓存中都不存在。当尝试访问第三级缓存时,因为ClassA已经提前暴露,所以ClassB能通过SingletonFactories拿到ClassA对象并顺利完成所有初始化流程。
ClassB对象创建完成之后就会被放到第一级缓存中,这时候ClassA就能从第一级缓存中获取ClassB的实例,进而完成ClassA的所有初始化流程。这样ClassA和ClassB都能够成功创建完成,整个流程如下图:

讲到这里,就理解为什么构造器注入无法解决循环依赖问题。这是因为构造器注入过程是发生在Bean初始化的第一个步骤createBeanInstance()中,而这个步骤还没有调用addSingletonFactory()方法完成第三级缓存的构建,自然也就无法从该缓存中获取目标对象。
4 消除循环依赖案例分析
本节将基于日常开发需求,通过一个具体的案例来介绍组件之间循环依赖的产生过程以及解决方案。
这个案例描述了医疗健康类系统中一个常见场景,每个用户都有一份健康档案,存储着代表用户当前健康状况的健康登记以及一系列的健康任务。用户每天可以通过完成医生所指定的任务来获取一定的健康积分,而这个积分的计算过程取决于该用户当前的健康等级。也就是说,不同的健康等级下完成同一个任务所能获取的积分也不一样。反过来,等级的计算也取决于该用户当前需要完成的任务数量,任务越多说明用户越不健康,其健康等级也就越低。健康档案和健康任务之间的关联如下图:
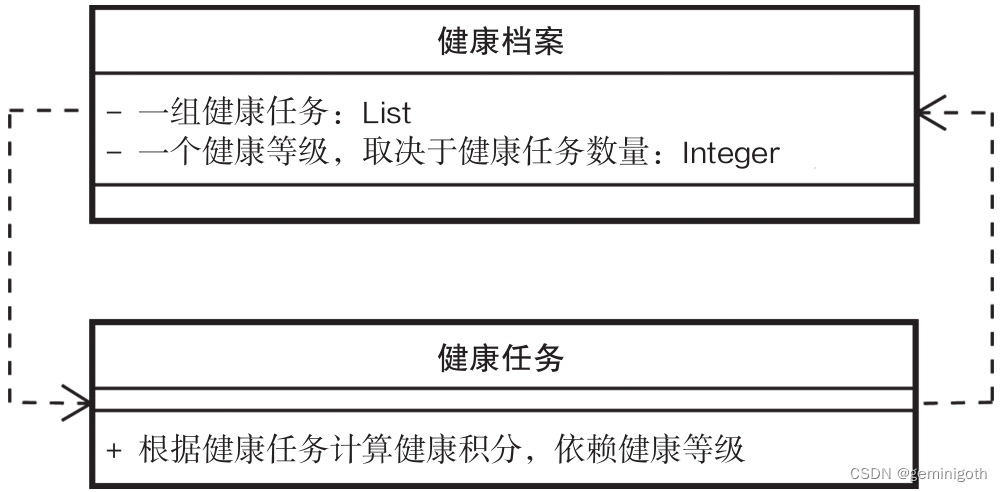
针对这个场景,可以抽象出两个类,一个代表健康档案的HealthRecord类,一个代表健康任务的HealthTask类。先看HealthRecord类,这个类包含一个HealthTask列表以及添加HealthTask的方法,同样也包含一个获取健康等级的方法,这个方法根据任务数量来判断健康等级,代码如下:
public class HealthRecord {private List<HealthTask> tasks = new ArrayList<>();public Integer getHealthLevel(){//根据健康任务数量来判断健康等级//任务越多说明越不健康,健康登记就越低if(tasks.size() > 5){return 1;}if(tasks.size() < 2){return 3;}return 2;}public void addTask(String taskName,Integer initialHealPoint){HealthTask task = new HealthTask(this, taskName, initialHealPoint);tasks.add(task);}public List<HealthTask> getTasks(){return tasks;}
}对应的HealthTask中显然也应该包括对HealthRecord的引用,同时也实现了一个方法来计算该任务所能获取的积分,这时候就需要使用到HealthRecord中的等级信息,代码如下:
public class HealthTask {private HealthRecord record;private String taskName;private Integer initialHealPoint;public HealthTask(HealthRecord record, String taskName, Integer initialHealPoint) {this.record = record;this.taskName = taskName;this.initialHealPoint = initialHealPoint;}public Integer calculateHealthPointForTask(){//计算该任务所能获取的积分,需要健康等级信息。健康登记越低积分越高,以鼓励用户多做任务Integer healthPointFromHealthLevel = 12 / record.getHealthLevel();//最终积分为初始积分 + 与健康等级相关的几人return initialHealPoint + healthPointFromHealthLevel;}public HealthRecord getRecord() {return record;}public void setRecord(HealthRecord record) {this.record = record;}public String getTaskName() {return taskName;}public void setTaskName(String taskName) {this.taskName = taskName;}public Integer getInitialHealPoint() {return initialHealPoint;}public void setInitialHealPoint(Integer initialHealPoint) {this.initialHealPoint = initialHealPoint;}
}从代码中可以看出,HealthRecord和HealthTask之间存在明显的相互依赖关系。
那么如何消除循环依赖呢?有一句很经典的话,即当我们碰到问题无从下手时,不妨考虑一下是否可以通过加一层的方法进行解决。消除循环依赖的基本思路也是这样,就是通过在两个相互依赖的组件之间添加中间层,变循环依赖为间接依赖。有三种方法可以做到这一点,分别是提取中介者、转移业务逻辑和引入回调。
4.1 提取中介者
提取中介者的核心思想是把两个相互依赖的组件中的交互部分抽象出来形成一个新的组件,而新组件同时包括着对原来两个组件的引用,这样就把循环依赖关系剥离出来并提取到一个专门的中介者组件中,关系如下图:

这个中介者组件的实现也非常简单,通过提供一个计算积分的方法来对循环依赖进行剥离,该方法同时依赖于HealthRecord和HealthTask对象,并实现了原有HealthTask中根据HealthRecord的等级信息进行积分计算的业务逻辑。中介者HealthPointMediator类的源码如下:
public class HealthPointMediator {private HealthRecord record;public HealthPointMediator(HealthRecord record) {this.record = record;}public Integer calculateHealthPointForTask(HealthTask task){Integer healthLevel = record.getHealthLevel();Integer initialHealPoint = task.getInitialHealPoint();Integer healthPoint = 12 / healthLevel + initialHealPoint;return healthPoint;}
}
测试类:HealthPointTest.java
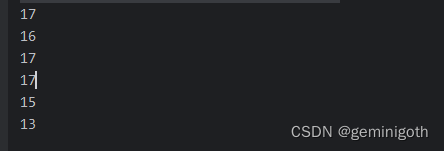
public class HealthPointTest {public static void main(String[] args) {HealthRecord healthRecord = new HealthRecord();healthRecord.addTask("忌烟酒",5);healthRecord.addTask("每周慢跑三次",4);healthRecord.addTask("一天喝两升水",5);healthRecord.addTask("做够1个小时起来活动5分钟",5);healthRecord.addTask("晚上10点按时睡觉",3);healthRecord.addTask("晚上8点之后不在饮食",1);HealthPointMediator healthPointMediator = new HealthPointMediator(healthRecord);List<HealthTask> tasks = healthRecord.getTasks();for(HealthTask task : tasks){Integer healthPoint = healthPointMediator.calculateHealthPointForTask(task);System.out.println(healthPoint);}}
}运行结果:
4.2 引入回调
继续介绍第二种消除循环依赖的方法,是采用回调接口。所谓回调,本质上是一种双向调用模式,也就是说,被调用方在被调用的同时也会调用对方。在实现上,可以提取一个用户计算健康等级的业务接口,然后让HealthRecord去实现这个接口。可以把接口命名为HealthLevelHandler,其中包含一个计算健康等级的方法定义。这样,HealthTask在计算积分时只需要依赖这个业务接口,而不关心这个接口的具体实现类,如下图:
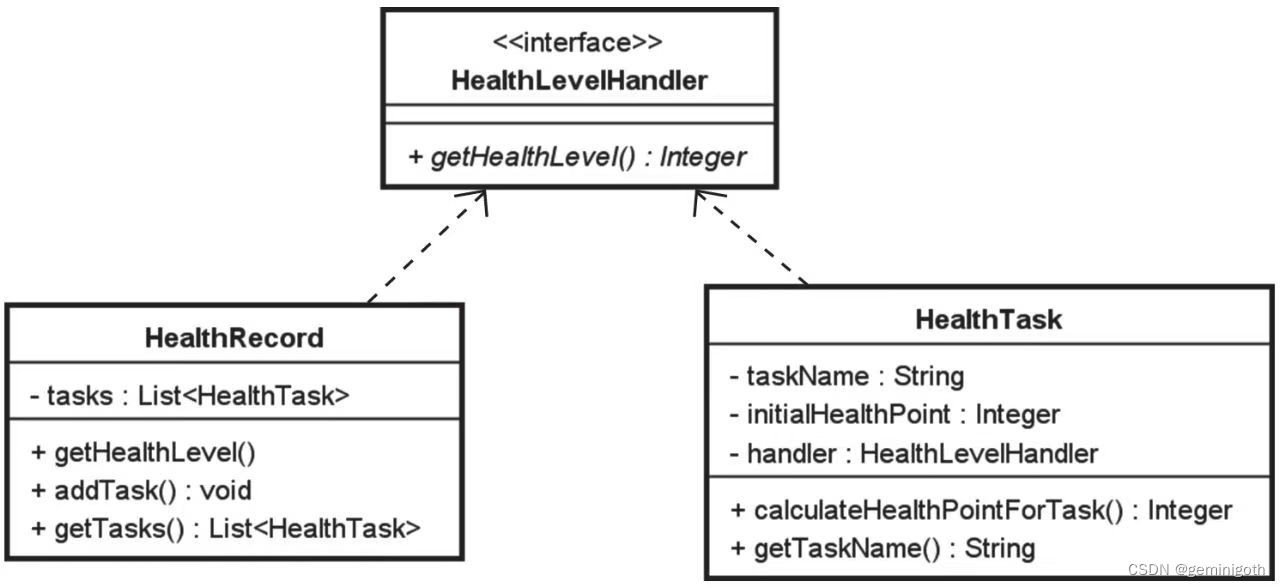
public interface HealthLevelHandler {Integer getHealthLevel();
}public class HealthRecord implements HealthLevelHandler{private List<HealthTask> tasks = new ArrayList<>();@Overridepublic Integer getHealthLevel(){//根据健康任务数量来判断健康等级//任务越多说明越不健康,健康登记就越低if(tasks.size() > 5){return 1;}if(tasks.size() < 2){return 3;}return 2;}public void addTask(String taskName,Integer initialHealPoint){HealthTask task = new HealthTask(this, taskName, initialHealPoint);tasks.add(task);}public List<HealthTask> getTasks(){return tasks;}
}4.3 转移业务逻辑
最后一种消除循环依赖的方法就是转移业务逻辑。 这种方法的实现思路在于提取一个专门的业务组件来完成对等级的计算过程。这样,HealthTask原本对HealthRecord的依赖就转移到了对这个业务组件的依赖,而这个业务组件本身不需要依赖任何对象。如下图:
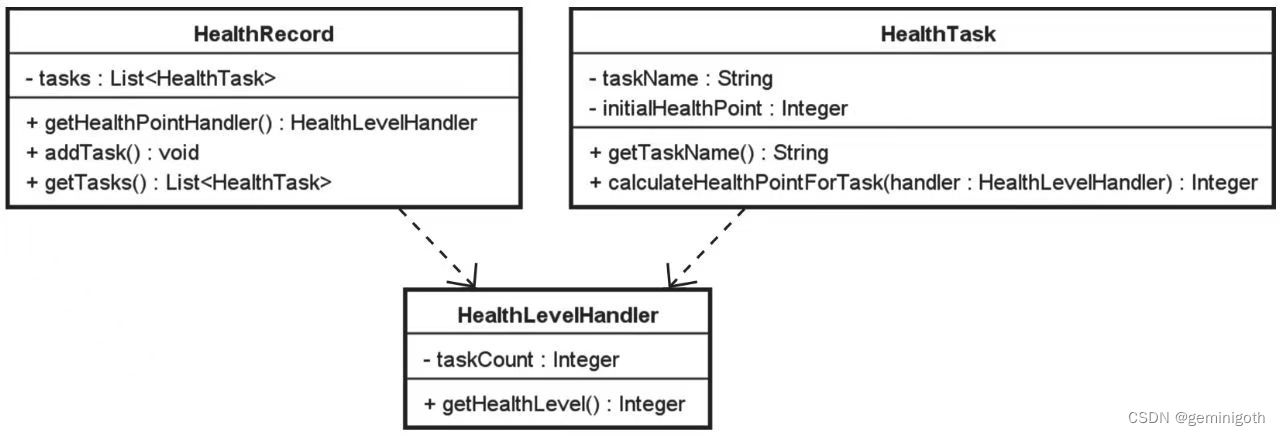
上图中专门负责处理业务逻辑的HealthLevelHandler类的实现代码也很简单。
public class HealthLevelHandler {private Integer taskCount;public HealthLevelHandler(Integer taskCount) {this.taskCount = taskCount;}public Integer getHealthLevel(){if(taskCount > 5){return 1;}if(taskCount < 2){return 3;}return 2;}
}public class HealthRecord {private List<HealthTask> tasks = new ArrayList<>();public void addTask(String taskName,Integer initialHealPoint){HealthTask task = new HealthTask( taskName, initialHealPoint);tasks.add(task);}public HealthLevelHandler getHealthPointHandler(){return new HealthLevelHandler(new Integer(tasks.size()));}public List<HealthTask> getTasks(){return tasks;}
}public class HealthTask {private String taskName;private Integer initialHealPoint;public HealthTask( String taskName, Integer initialHealPoint) {this.taskName = taskName;this.initialHealPoint = initialHealPoint;}public Integer calculateHealthPointForTask(HealthLevelHandler handler){//计算该任务所能获取的积分,需要健康等级信息。健康登记越低积分越高,以鼓励用户多做任务Integer healthPointFromHealthLevel = 12 / handler.getHealthLevel();//最终积分为初始积分 + 与健康等级相关的几人return initialHealPoint + healthPointFromHealthLevel;}}public class HealthPointTest {public static void main(String[] args) {HealthRecord healthRecord = new HealthRecord();healthRecord.addTask("忌烟酒",5);healthRecord.addTask("每周慢跑三次",4);healthRecord.addTask("一天喝两升水",5);healthRecord.addTask("做够1个小时起来活动5分钟",5);healthRecord.addTask("晚上10点按时睡觉",3);healthRecord.addTask("晚上8点之后不在饮食",1);HealthLevelHandler handler = healthRecord.getHealthPointHandler();List<HealthTask> tasks = healthRecord.getTasks();for(HealthTask task : tasks){Integer healthPoint = task.calculateHealthPointForTask(handler);System.out.println(healthPoint);}}
}这篇关于Spring Boot 系统学习第四天:Spring循环依赖案例分析 备份的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






