本文主要是介绍TensorBoard在pytorch训练过程中如何使用,及数据读取问题解决方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TensorBoard
- 模块导入
- 日志记录文件的创建
- 训练中如何写入数据
- 如何提取保存的数据调用TensorBoard面板
- 可能会遇到的问题
模块导入
首先从torch中导入tensorboard的SummaryWriter日志记录模块
from torch.utils.tensorboard import SummaryWriter
然后导入要用到的os库,当然你们也要导入自己模型训练需要用到的库
import os
日志记录文件的创建
import oslog_dir = 'runs/EfficientNet_B3_experiment2'# 检查目录是否存在
if os.path.exists(log_dir):# 如果目录存在,获取目录下的所有文件和子目录列表files = os.listdir(log_dir)# 遍历目录下的文件和子目录for file in files:# 拼接文件的完整路径file_path = os.path.join(log_dir, file)# 判断是否为文件if os.path.isfile(file_path):# 如果是文件,删除该文件os.remove(file_path)elif os.path.isdir(file_path):# 如果是目录,递归地删除目录及其下的所有文件和子目录for root, dirs, files in os.walk(file_path, topdown=False):for name in files:os.remove(os.path.join(root, name))for name in dirs:os.rmdir(os.path.join(root, name))os.rmdir(file_path)# 创建新的SummaryWriter
writer = SummaryWriter(log_dir)
这个代码会自动创建并更新日志文件目录,请谨慎使用,记得改
log_dir = 'runs/EfficientNet_B3_experiment2'路径名字小心把之前保存好的数据删除了
之后模型训练的数据将会写入到log_dir这个路径文件中,在由TensorBoard张量板调用显示数据
训练中如何写入数据
for epoch in range(num_epochs):model.train()running_loss = 0.0correct = 0total = 0start_time = time.time()for images, labels in train_loader:images, labels = images.to(device), labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 记录学习率current_lr = optimizer.param_groups[0]['lr']writer.add_scalar('Learning Rate', current_lr, epoch)# 记录梯度范数total_norm = 0for p in model.parameters():param_norm = p.grad.data.norm(2)total_norm += param_norm.item() ** 2total_norm = total_norm ** 0.5writer.add_scalar('Gradient Norm', total_norm, epoch)running_loss += loss.item()_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()train_loss = running_loss / len(train_loader)train_accuracy = 100 * correct / total# 记录训练损失和准确率writer.add_scalar('Training Loss', train_loss, epoch)writer.add_scalar('Training Accuracy', train_accuracy, epoch)# 记录模型参数的直方图for name, param in model.named_parameters():writer.add_histogram(name, param, epoch)# 记录网络结构(通常只需要记录一次)if epoch == 0:writer.add_graph(model, images.to(device))# 记录输入图片img_grid = torchvision.utils.make_grid(images)writer.add_image('train_images', img_grid, epoch)# 使用matplotlib记录渲染的图片fig, ax = plt.subplots()ax.plot(np.arange(len(labels)), labels.cpu().numpy(), 'b', label='True')ax.plot(np.arange(len(predicted)), predicted.cpu().numpy(), 'r', label='Predicted')ax.legend()writer.add_figure('predictions vs. actuals', fig, epoch)# 验证模型model.eval()val_loss = 0.0correct = 0total = 0all_preds = []all_labels = []with torch.no_grad():for images, labels in test_loader:images, labels = images.to(device), labels.to(device)outputs = model(images)loss = criterion(outputs, labels)val_loss += loss.item()_, predicted = torch.max(outputs.data, 1)all_preds.extend(predicted.cpu().numpy())all_labels.extend(labels.cpu().numpy())total += labels.size(0)correct += (predicted == labels).sum().item()val_loss /= len(test_loader)val_accuracy = 100 * correct / totalif val_accuracy > best_val_accuracy:# 当新的最佳验证准确率出现时,保存模型状态字典best_val_accuracy = val_accuracybest_model_state_dict = model.state_dict()# 记录验证损失和准确率writer.add_scalar('Validation Loss', val_loss, epoch)writer.add_scalar('Validation Accuracy', val_accuracy, epoch)# 记录多条曲线writer.add_scalars('Loss', {'train': train_loss, 'val': val_loss}, epoch)writer.add_scalars('Accuracy', {'train': train_accuracy, 'val': val_accuracy}, epoch)# 打印每个epoch的训练和验证结果print(f'Epoch [{epoch+1}/{num_epochs}], 'f'Train Loss: {train_loss:.4f}, Train Accuracy: {train_accuracy:.2f}%, 'f'Validation Loss: {val_loss:.4f}, Validation Accuracy: {val_accuracy:.2f}%, 'f'Time: {time.time() - start_time:.2f}s')
以上代码分别记录了
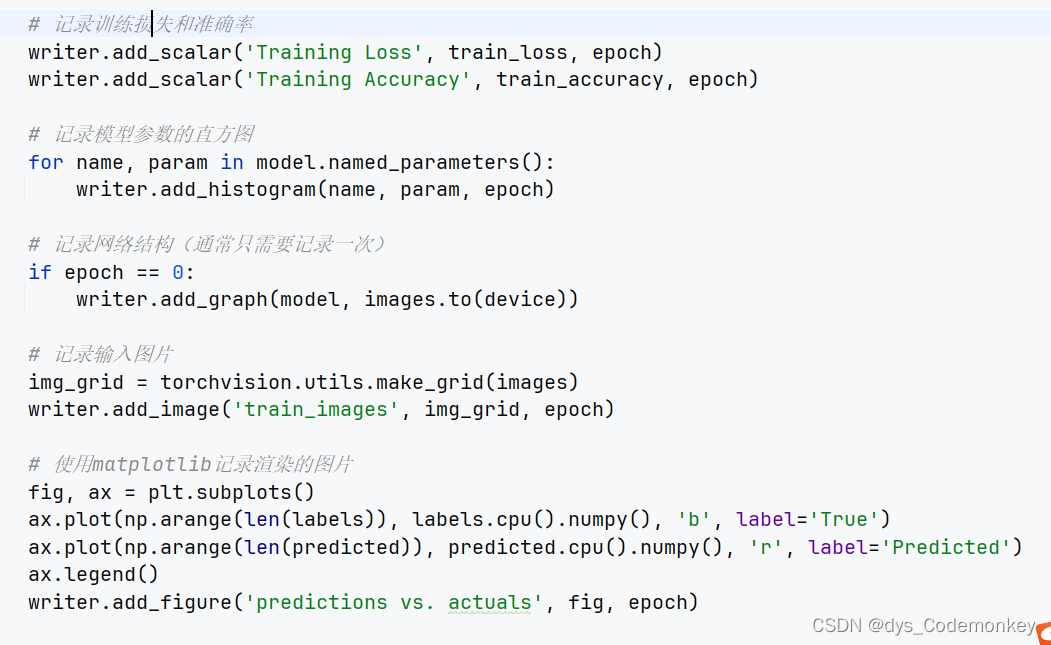

如何提取保存的数据调用TensorBoard面板
在终端输入以下代码
tensorboard --logdir='修改为自己的log_dir路径'
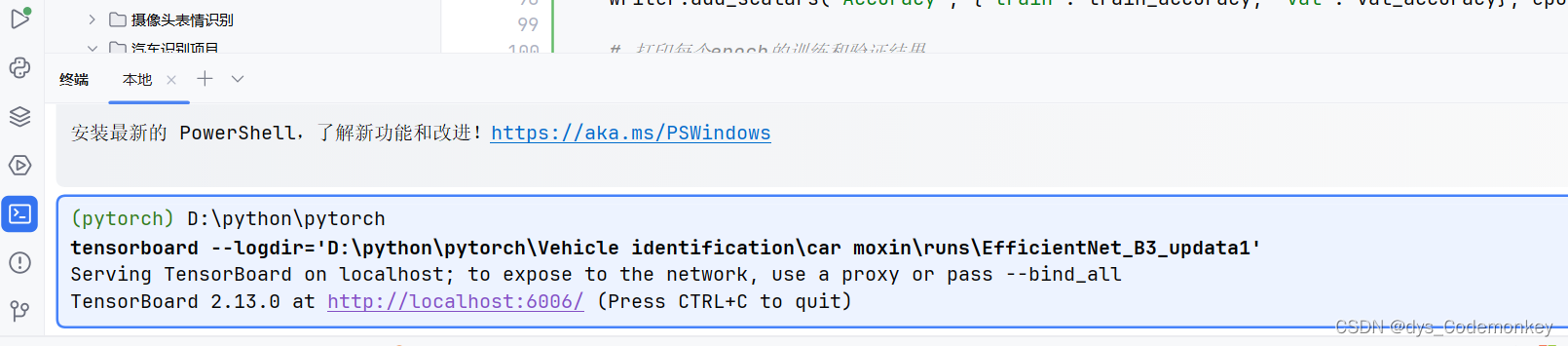
然后点击 http://localhost:6006/就可以成功加载面板了
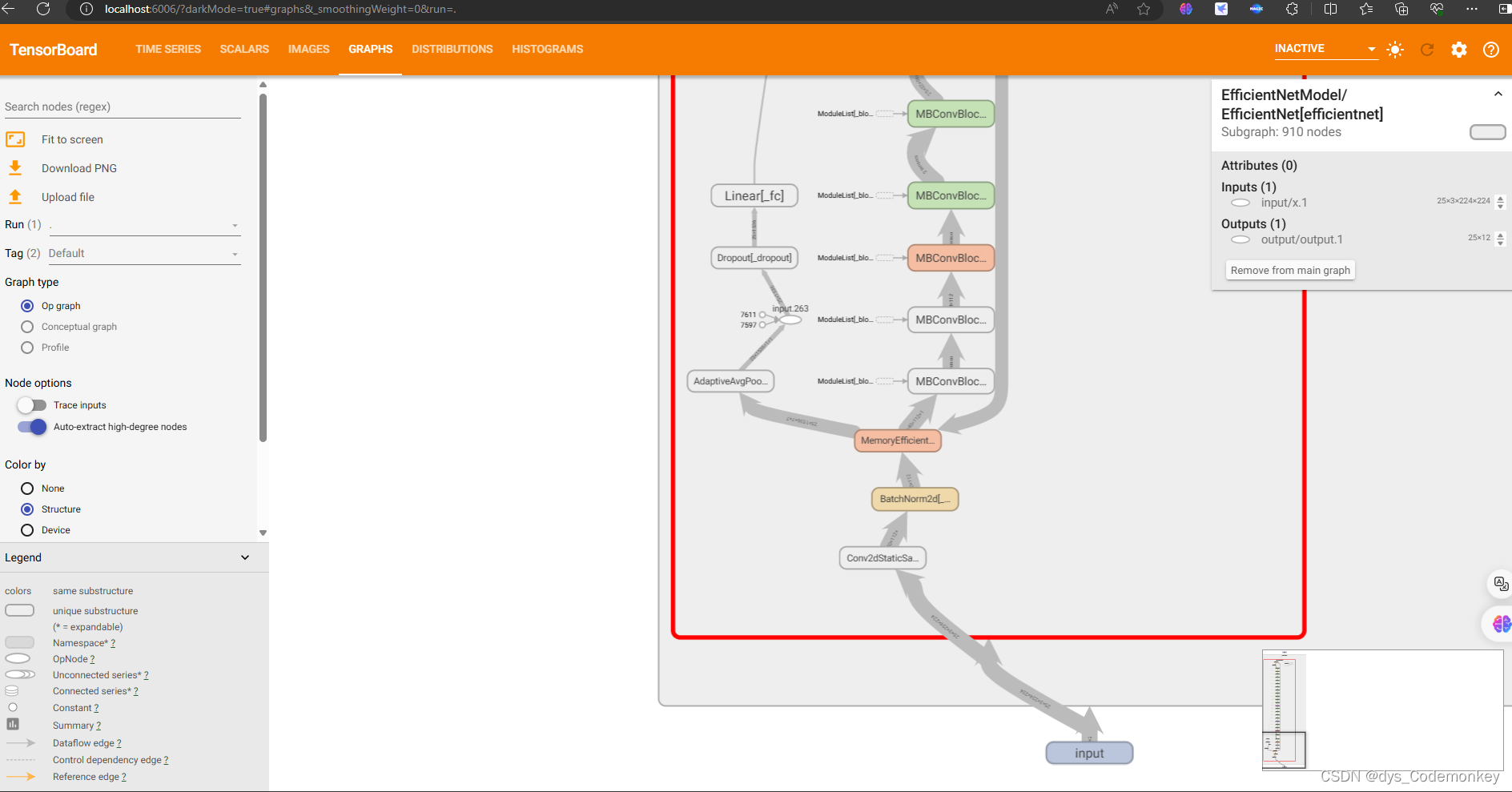
可能会遇到的问题
如果数据读取失败那么请检查数据路径是否正确
注意数据文件中不能有任何中文
这篇关于TensorBoard在pytorch训练过程中如何使用,及数据读取问题解决方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



