本文主要是介绍dm8 什么时候视图中统计的内存会超过OS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
v$bufferpool和v$mem_pool视图记录着DMSERVER各组件的内存占用量。理论上跟OS看到的保持一致。但实际大多数场景下,OS中看到的数据远大于视图中的统计。这里面可能有内存泄漏的原因。不过也有的时候视图中的统计数据超过OS。下面就是这种情况:
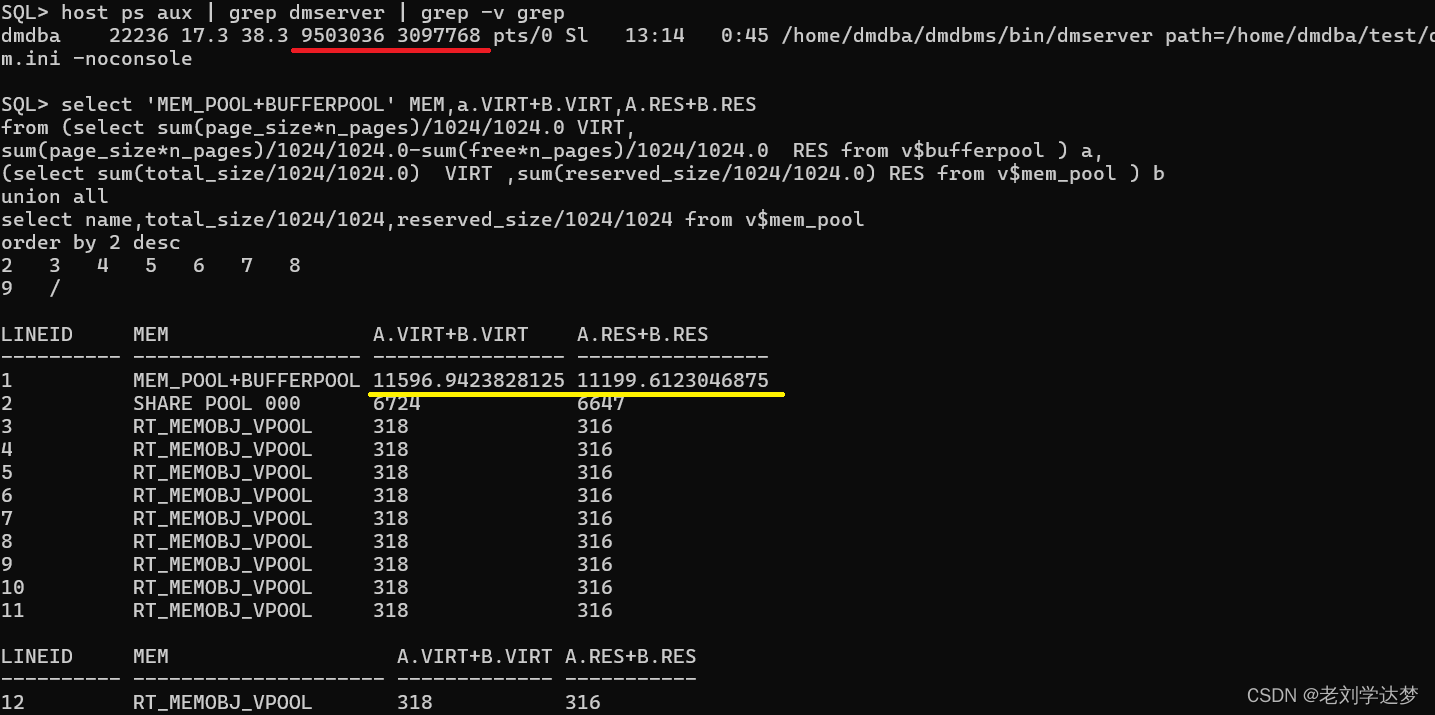
上图中红线是OS中看到的内存占用量,单位K。黄线是数据库中统计的数据,单位M。远远大于OS。原因是系统正在一组排序操作。
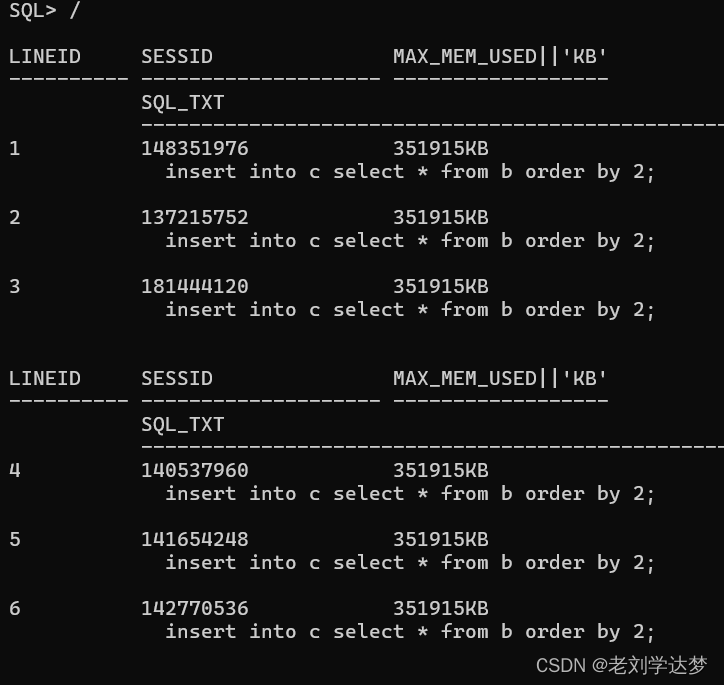
系统为每一个执行排序操作的会话分配了300M左右内存(RT_MEMOBJ_VPOOL)。
语句执行完毕后恢复正常
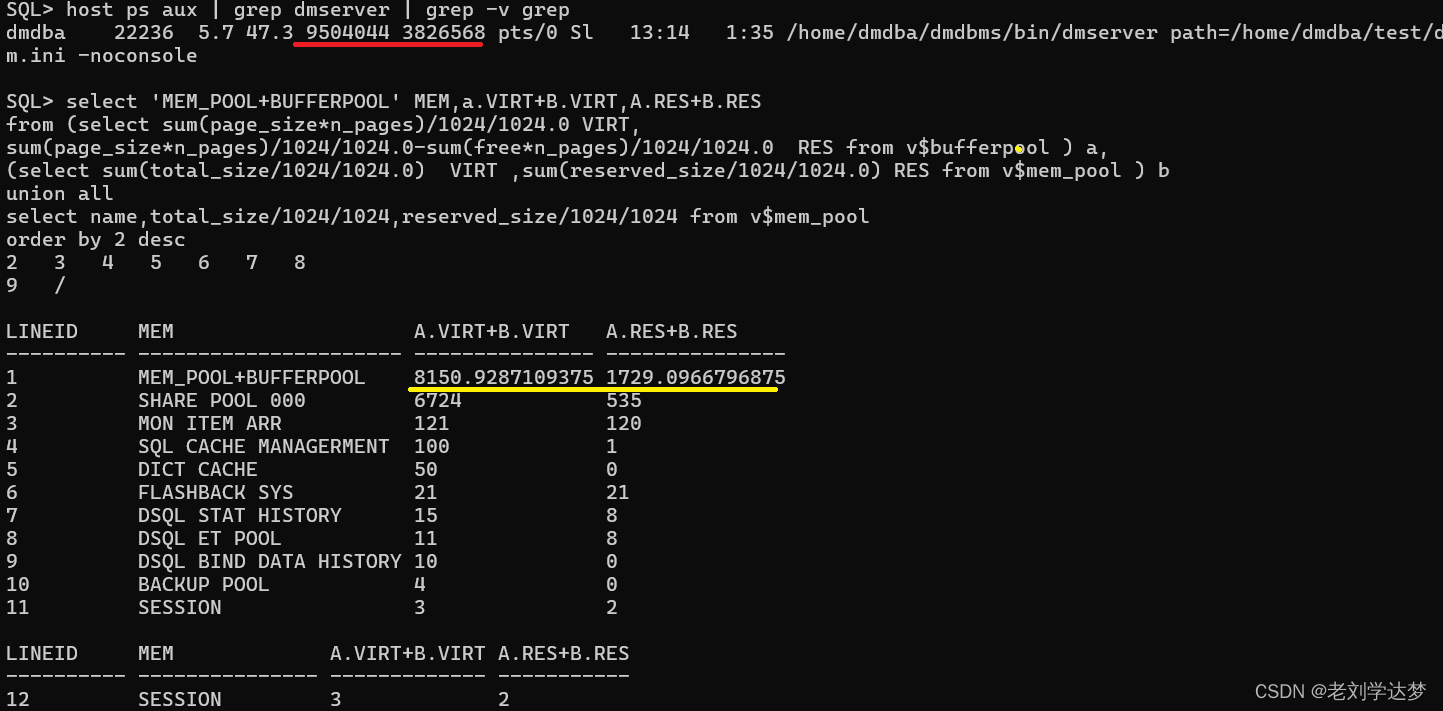
那为什么这部分内存在OS中没有得到体现呢?原因是DMSERVER为每一个涉及排序的会话分配了固定的内存量(SORT_BUF_SIZE参数定义),但本例中的这些SQL排序需要的内存量其实很少。大部分内存没有使用。
达梦的新排序机制可以消除以上现象。将SORT_FLAG参数设置为1。系统将根据实际需要为每个会话分配排序内存,总尺寸不超过SORT_BUF_GLOBAL_SIZE。但新排序机制在某些版本还待完善,比如本例的03134283938-20221019-172201-20018版本。虽然SORT_FLAG参数设置为1后使用新排序排序机制,但系统依旧为每个会话额外分配SORT_BUF_SIZE内存。为减少干扰,我们将SORT_BUF_SIZE参数设置为1。测试如下:
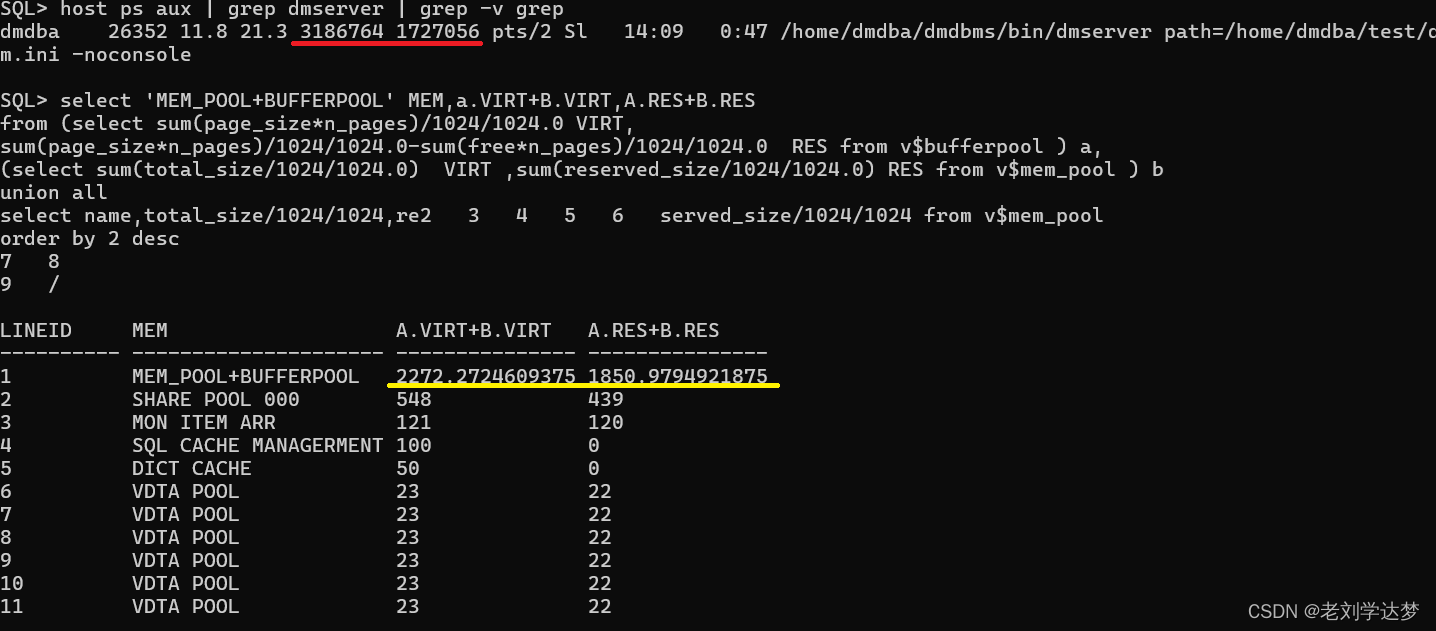
从视图中统计的数字明显下降。
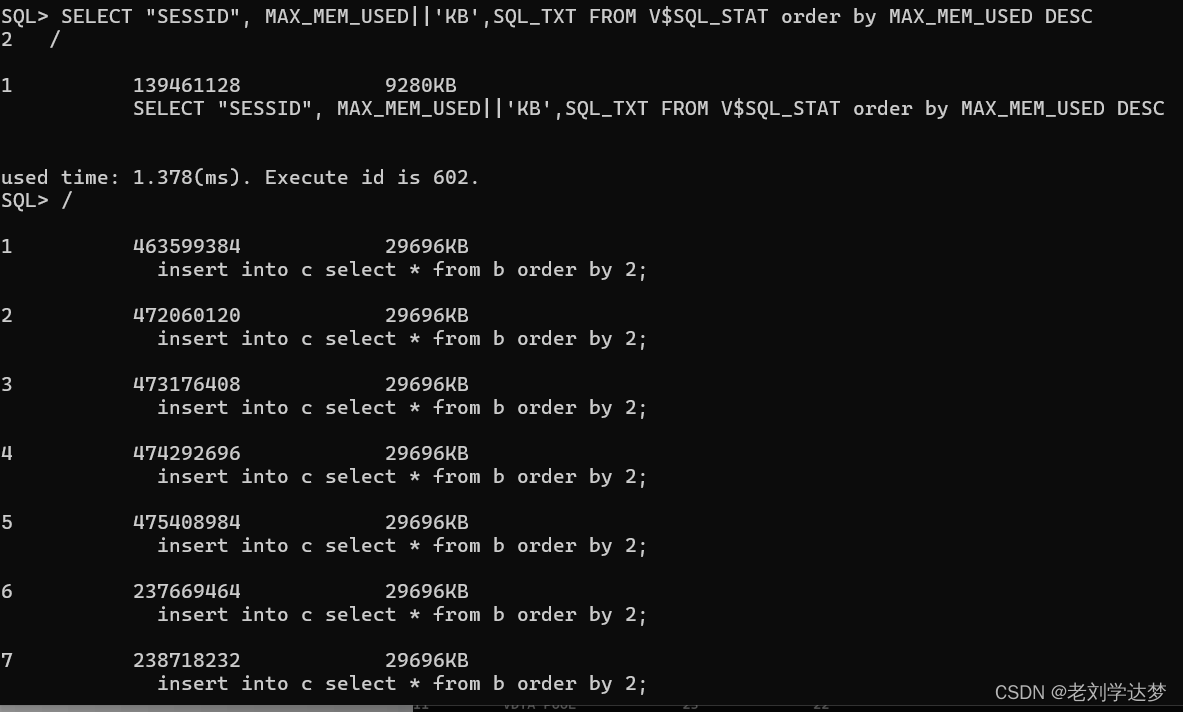
每个会话占用29696KB,其中主要成分是23M VDTA POOL。
注:VDTA POOL是新机制下的排序区,RT_MEMOBJ_VPOOL是老机制时的排序区。
附件:
视图统计各组件内存占用量及总和
select 'MEM_POOL+BUFFERPOOL' MEM,a.VIRT+B.VIRT,A.RES+B.RES
from (select sum(page_size*n_pages)/1024/1024.0 VIRT,
sum(page_size*n_pages)/1024/1024.0-sum(free*n_pages)/1024/1024.0 RES from v$bufferpool ) a,
(select sum(total_size/1024/1024.0) VIRT ,sum(reserved_size/1024/1024.0) RES from v$mem_pool ) b
union all
select name,total_size/1024/1024,reserved_size/1024/1024 from v$mem_pool
order by 2 desc
统计每个会话的内存占用量
SELECT "SESSID", MAX_MEM_USED||'KB',SQL_TXT FROM V$SQL_STAT order by MAX_MEM_USED DESC统计每个会话内存占用量明细
SELECT
A.CREATOR , a.name,B.SQL_TEXT ,
A.TOTAL_SIZE/1024.0/1024.0 TOTAL_M, --当前总量(包括扩展)
A.DATA_SIZE /1024.0/1024.0 DATA_SIZE_M --实际使用量
FROM
V$MEM_POOL A, V$SESSIONS B
WHERE
A.CREATOR = B.THRD_ID
ORDER BY
TOTAL_M DESC;这篇关于dm8 什么时候视图中统计的内存会超过OS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




