本文主要是介绍前嗅教你大数据:采集孔夫子旧书网,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
l 采集网站
【场景描述】采集孔夫子旧书网数据。
【源网站介绍】孔夫子旧书网是国内专业的古旧书交易平台,汇集全国各地13000家网上书店,50000家书摊,展示多达9000万种书籍;大量极具收藏价值的古旧珍本(明清、民国古籍善本,珍品期刊,名人墨迹,民国珍本,绝版书等)在孔网展示与交易,吸引了大量的学者、研究人员和藏书人长时间在线关注并参与。
【使用工具】前嗅ForeSpider数据采集系统,免费下载:
ForeSpider免费版本下载地址
【入口网址】https://book.kongfz.com/Cxianzhuang/cat_8002/
【采集内容】
采集孔夫子旧书网中书籍的标题、作者、价格、介绍详情等基本信息。

【采集效果】
如下图所示:
l 思路分析
配置思路概览:

l 配置步骤
1. 新建采集任务
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。

2.获取翻页链接
抽取翻页链接方法有三种,具体如下所示:
①智能过滤法:
打开前几个翻页链接,观察链接规律,
第二页:文学_线装古籍_孔夫子旧书网
第三页:文学_线装古籍_孔夫子旧书网
第四页:文学_线装古籍_孔夫子旧书网
根据规律输入过滤规则:https://book.kongfz.com/Cxianzhuang/cat_\dw\d/
(其中\d表示数字串)

配置后,点击采集预览,发现翻页链接已经都采集到了。

②方法二:定位取值法按住ctrl+鼠标单击任意一个翻页,然后按住shift+鼠标单击任意一个未选中翻页扩大选区,直至选中所有翻页,然后确认选区后保存。

采集预览,发现所有翻页都被抽取出来了。

③方法三:地址/标题过滤
类似智能过滤,先观察翻页链接规律(步骤可参考方法一),找到规律后,使用地址过滤的方法进行过滤保存,如下图所示:

④关联模板,将翻页链接抽取,关联模板01。

3.抽取列表链接
①新建一个链接抽取,改名为【列表链接】,将翻页链接抽取改名为【翻页链接】。

②使用链接过滤的方法来获取列表链接,先采集预览,打开列表链接预览结果,发现图书的链接规律为:
https://book.kongfz.com/数字串/数字串/
所以设置地址过滤,过滤出包含该规律的链接,如下图所示,其中\d表示数字串。
![]()
③采集预览查看是否抽取成功。

4.抽取数据
①新建一个抽取模板,在其下新建一个数据抽取,具体操作如下所示:

②数据建表,按照下图所示建数据表。(注意字段属性等应严格按照下图进行设置)

③将新建好的数据表,关联到模板中去,如下图所示:

④填写示例数据,采集预览,复制任意一条新闻链接。

⑤将链接粘贴到本模板示例地址中,并双击内置浏览器空白部分,加载本链接。

⑥关联模板

⑦数据取值
使用定位取值的方法,title字段如下所示:

author字段如下所示:

其他字段也按照同样的方法进行定位取值。
⑧采集预览

l 采集步骤
模板配置完成,采集预览没有问题后,可以进行数据采集。
1.建立数据表单
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为【kongfuzi】(注意命名不能用数字和特殊符号),点击【确定】。创建完成,勾选数据表,并点击右上角保存按钮。

2.开始采集
选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。

3.导出数据
采集结束后,可以在【数据浏览】中,选择数据表查看采集数据,并可以导出数据。


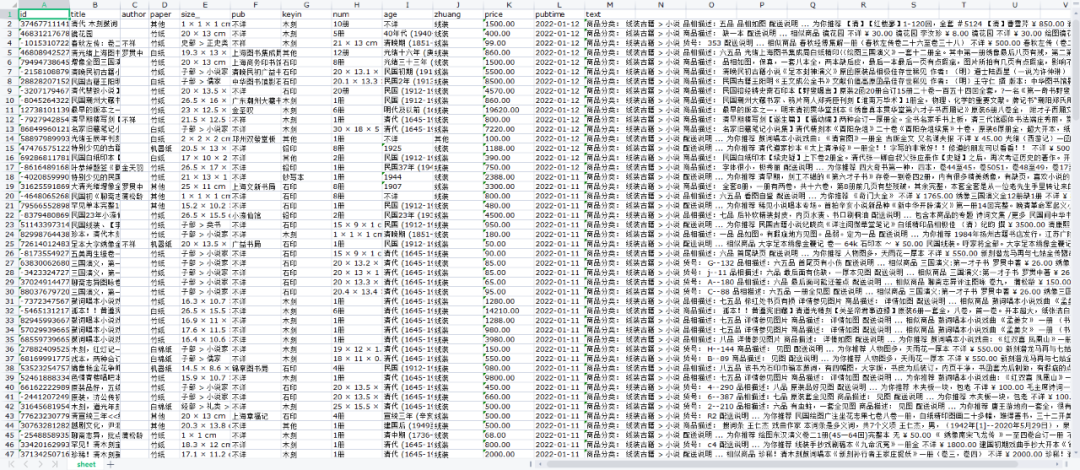
4.导出的文件打开如下图所示:
本教程仅供教学使用,严禁用于商业用途!
l 前嗅简介
前嗅大数据,国内领先的研发型大数据专家,多年来致力于为大数据技术的研究与开发,自主研发了一整套从数据采集、分析、处理、管理到应用、营销的大数据产品。前嗅致力于打造国内第一家深度大数据平台!
这篇关于前嗅教你大数据:采集孔夫子旧书网的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



