本文主要是介绍python实现描述统计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据基础情况
import numpy as np
import pandas as pd
import matplotlib.pyplot as pyplot
pd.options.display.max_rows = 10##最多输出10行数据
data_url= 'https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-ST0151EN-SkillsNetwork/labs/teachingratings.csv'
data=pd.read_csv(data_url)
# 打印行数和列数
data.shape
#(463, 19)# 打印数据的个数
data.size
#8797# 该数据集的维度
data.ndim
#2# 该数据集的长度
len(data)
#463# 各个列的值的个数
data.count()
'''
minority 463
age 463
gender 463
credits 463
beauty 463...
female 463
single_credit 463
upper_division 463
English_speaker 463
tenured_prof 463
Length: 19, dtype: int64
''''''count()函数是一种非常常用的方法,用于统计某个元素在列表、元组或字符串中出现的次数。它的使用非常简单,只需要传入要统计的元素作为参数即可;基本语法:count(element, start, end);其中,element是要统计的元素;start:(可选,整型)开始的索引,默认0;end :(可选,整型)结束的索引,默认最后一个位置count()函数返回的是指定元素在列表、元组或字符串中出现的次数。如果元素不存在,则返回0。1)字符串:string.count( str, start, end )2)字节串:bytes.count( str, start, end ) 3)字节数组:bytearray.count( str, start, end ) 4)列表:list.count( element )5)元组:tuple.count( element ) 6)等差数列:range.count( element )fruits = ['apple', 'banana', 'orange', 'apple', 'grape', 'apple']
count = fruits.count('apple')
print(count)
#>>3text = "Python is a powerful programming language. Python is widely used in web development, data analysis, and artificial intelligence."
count = text.count('Python')
print(count)
#>>2numbers = [1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
count = numbers.count([1, 2])
print(count)
#>>2'''# 各列的最小值
data.min()
'''
Rank 1
Title (500) Days of Summer
Genre Action
Description "21" is the fact-based story about six MIT stu......
Rating 1.9
Votes 61
Revenue (Millions) 0
Metascore 11
Length: 12, dtype: object
'''# 描述信息
df.describe()
'''float_col int_col
count 5.000000 5.000000
mean 0.500000 3.000000
std 0.395285 1.581139
min 0.000000 1.000000
25% 0.250000 2.000000
50% 0.500000 3.000000
75% 0.750000 4.000000
max 1.000000 5.000000
'''
'''
查看某个列的数据的统计特征值(eg:平均值、中位数、最小值、最大值)
平均值:.mean();中位数.median();最小值:.min();最大值:.max()
'''#描述组内数据的基本统计量
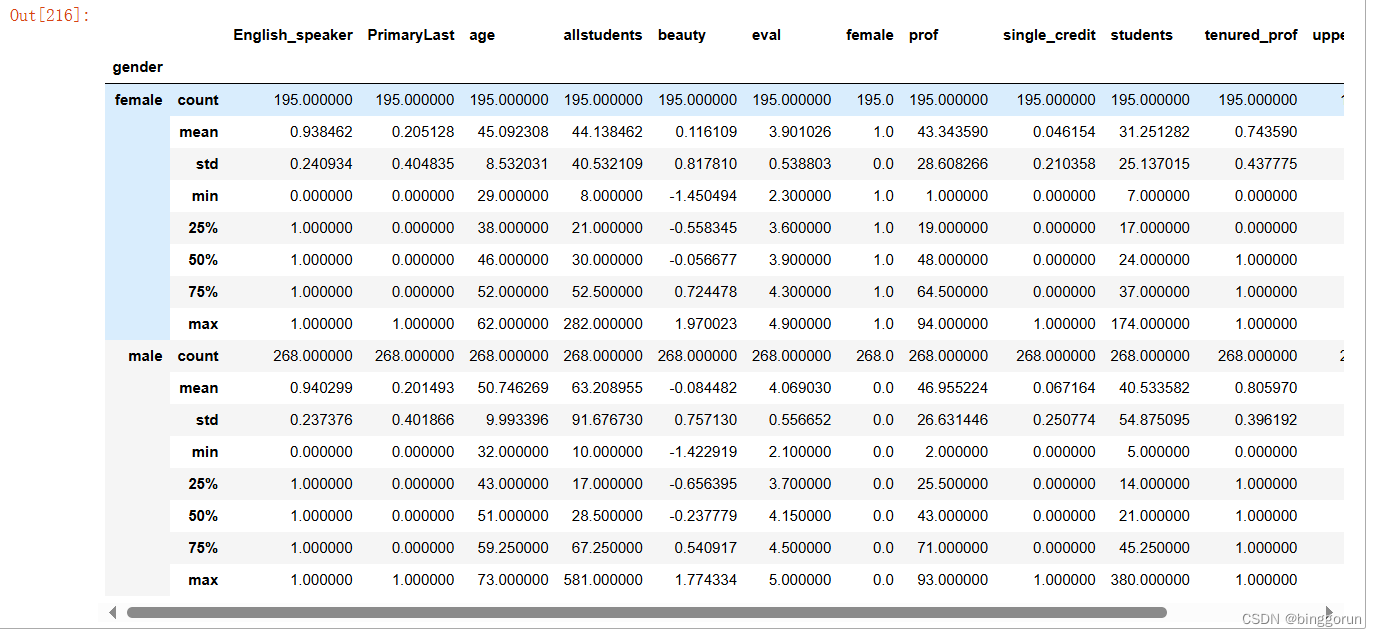
data.groupby('gender').describe().stack()#unstack():从行到列取消堆叠,stack():从列到行堆叠
分布图
绘制某列数据的分布直方图
import matplotlib.pyplot as pyplot
pyplot.hist(data['beauty'])

分类统计分析
groupby()方法
通过对DataFrame对象调用groupby()函数返回的结果是一个DataFrameGroupBy对象,而不是一个DataFrame或者Series对象
分组时,可指定多个列名
调用get_group()函数可以返回一个按照分组得到的DataFrame对象
也可调用max()、count()、std()等,返回一个DataFrame对象
可与聚合函数aggregate/agg一起使用
可对组内的数据绘制概率密度分布
grouped = df.groupby('Gender')
print(type(grouped))
print(grouped)
'''
<class 'pandas.core.groupby.groupby.DataFrameGroupBy'>
'''##分组时,不仅仅可以指定一个列名,也可以指定多个列名:
grouped = df.groupby('Gender')
grouped_muti = df.groupby(['Gender', 'Age'])
print(grouped.size())
'''
Gender
Female 3
Male 5
dtype: int64
'''print(grouped_muti.size())
'''
Gender Age
Female 17 118 122 1
Male 18 119 120 221 1
dtype: int64
'''##get_group()函数可以返回一个按照分组得到的DataFrame对象
df = grouped.get_group('Female').reset_index()
print(df)
'''index Name Gender Age Score
0 2 Cidy Female 18 93
1 4 Ellen Female 17 96
2 7 Hebe Female 22 98
'''
调用max()、count()、std()等,返回的结果是一个DataFrame对象。
grouped.max()[['age', 'allstudents']]
'''age allstudents
gender
female 62 282
male 73 581
'''df.groupby('Sex')['salary'].mean()##求得分组平均数, 得到的是一个Series, 每一行对应了每一组的mean, 除此之外你还可以换成std, median, min, max, sum 这些基本的统计数据
'''
Sex
female 2500
male 6750
Name: salary, dtype: int64
'''
grouped.mean()[['age', 'allstudents']]
'''age allstudents
gender
female 45.092308 44.138462
male 50.746269 63.208955
'''grouped.count()

也可以选择使用聚合函数aggregate,传递numpy或者自定义的函数,前提是返回一个聚合值
def getSum(data):total = 0for d in data:total+=dreturn totalprint(grouped.aggregate({'age':np.median, 'allstudents':np.sum}))
'''age allstudents
gender
female 46 8607
male 51 16940
'''
print(grouped.aggregate({'age':getSum}))
'''age
gender
female 8793
male 13600
'''
print(grouped.aggregate(np.median))

aggregate函数不同于apply,前者是对所有的数值进行一个聚合的操作,而后者则是对每个数值进行单独的一个操作
df.groupby('Sex').agg({'salary':np.sum,'age':np.median})
'''salary age
Sex
female 5000 33.0
male 27000 35.0
'''df.groupby('Sex')['age'].agg([np.sum,np.mean,np.max,np.min])
'''sum mean amax amin
Sex
female 66.0 33.00 36.0 30.0
male 135.0 33.75 40.0 25.0
'''
可视化操作
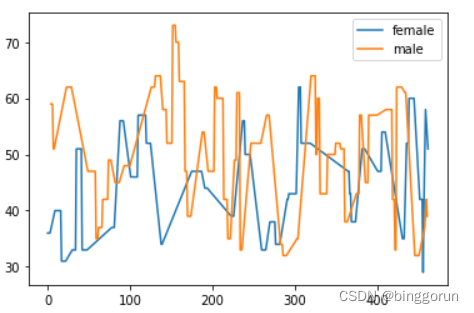
grouped['age'].plot(kind='line', legend=True)
plt.show()
df.groupby('Sex')['area'].value_counts().unstack().plot(kind = 'bar',figsize = (15,5))
df.groupby('area')['age'].sum().plot(kind = 'bar',figsize = (15,5))
这篇关于python实现描述统计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



