本文主要是介绍SQL查询太慢?实战讲解YashanDB SQL调优思路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文是 Meetup 第十期 “调优实战专场” 的第二篇技术文章,上一篇《高效查询秘诀,解码 YashanDB 优化器分组查询优化手段》中,我们揭秘了 YashanDB 分组查询优化秘诀,本文将通过一个案例,助你快速上手 YashanDB 慢日志功能,精准定位 “慢 SQL” 后进行优化。

前言
说起 SQL 调优,不少人认为是个高难度的事情,让人望而却步。但其实在日常的运维过程中,慢 SQL 却是一个常见的问题,这时大家或多或少会用到一些常用的调优手段,比如加索引、调整执行计划等。
接下来,我们将通过三大环节详细讲解如何发现、分析和优化 “慢 SQL”,具体包括利用慢日志定位问题、分析执行计划并可通过 hint 手段人为调整优化、以及有效搜集统计信息优化执行计划等。这个通用思路可以在遇到性能问题时,提供一种可行的解决方案,帮助大家尝试着手解决问题。
如何找到慢 SQL
首先,SQL 调优最重要的是如何找到慢 SQL。
从业务层的表现来看,比如应用反应慢、接口获取数据超时、应用夯住等等。但若业务反馈说某条 SQL 很慢,能帮忙优化一下吗?我们该怎么确定这条 SQL 一定就是那条 “慢 SQL” 呢?
在 YashanDB 中,有多种方式可以辅助我们准确定位慢 SQL,以下是一些常用方式:
- YCM 监控平台
- AWR 报告
- 系统性能视图,比如 V S Q L , V SQL,V SQL,VSESSION 等
- 慢日志 slow.log
本次主要介绍怎么使用慢日志功能来找到符合条件的慢 SQL。
01 slow log 的配置
主要通过两个基本参数控制,可以找到慢 SQL。
- ENABLE_SLOW_LOG:是否开启慢日志,默认关闭。(即时生效,不建议长期开启,用于复现性能问题时抓取识别慢 SQL。)
- SLOW_LOG_TIME_THRESHOLD :时间阈值,单位毫秒。(代表超过这个时间阈值的 SQL,认为是慢 SQL,会记录在 slow.log 里面
执行下列命令开启慢日志:
ALTER SYSTEM SET ENABLE_SLOW_LOG = TRUE;

慢日志相关的参数介绍如下:
- SLOW_LOG_FILE_NAME:慢日志文件名,使用默认即可。
- SLOW_LOG_FILE_PATH:慢日志文件路径,使用默认即可。
- SLOW_LOG_OUTPUT:慢日志输出方式,默认是 FILE,也可以设置成 TABLE,慢 SQL 信息会输出到系统表 SYS.SLOW_LOG$,建议使用默认的 FILE 即可。
- SLOW_LOG_SQL_MAX_LEN:慢 SQL 打印的 SQL 长度,最长也是 2000,使用默认即可。
按照如上配置设置完成之后,执行时间超过 1s 的 SQL 就会被记录在 slow log 中。
测试完成之后,需要将 slow log 关闭:
ALTER SYSTEM SET ENABLE_SLOW_LOG = FALSE;
既然找到了慢 SQL,接下来需要针对该 SQL 进行优化,一般会去查看该 SQL 的执行计划情况。
执行计划的生成和调整
01 如何查看执行计划
查看执行计划通常有两种手段,通过 explain+SQL 或是通过 autotrace。
方式 1_:_通过 explain + SQL
比如:
explain select object_name from test limit 10;
方式 2_:_autotrace
各操作类别如下:
- set autotrace on explain:输出语句的执行结果和执行计划
- set autotrace on statistics:输出语句的执行结果和 SQL 执行统计信息
- set autotrace traceonly:只输出语句的执行计划和执行统计信息
- set autotrace on:输出语句的执行结果、执行计划和执行统计信息
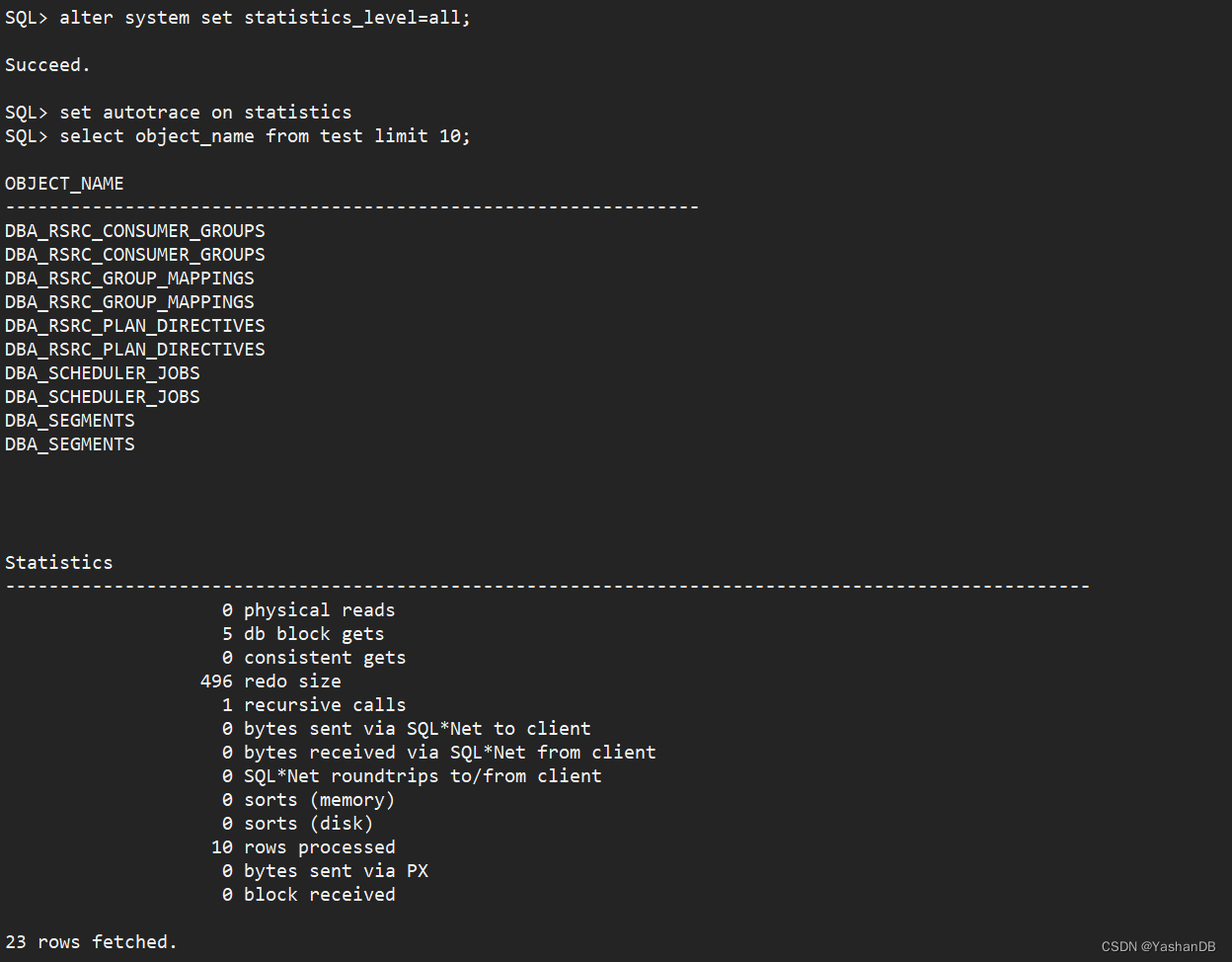
注:输出统计信息需要设置参数 statistics_level=all(alter system set statistics_level=all;)
通过表格对比各个操作类别,更能直观感受其区别:

以下通过一个完整的测试用例,查看 explain 和 autotrace 各类别打印出来的具体信息。
- 创建测试表和索引
# 创建测试表
create table test as select * from dba_objects;# 创建索引,为后面测试hint修改执行计划做准备
create index idx_obj_name on test (object_name);
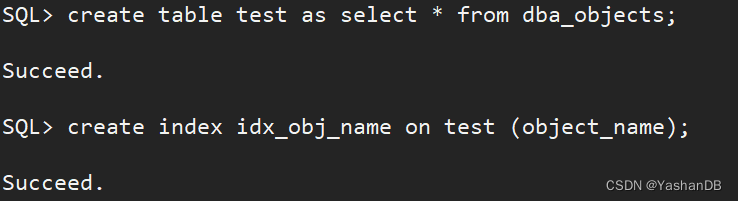
- 使用方式 1 explain 查看执行计划
explain select object_name from test limit 10;
explain 的执行计划可以看到输出的表格信息,这个表格所展示的就是 SQL 的执行计划,后面会进行解读。
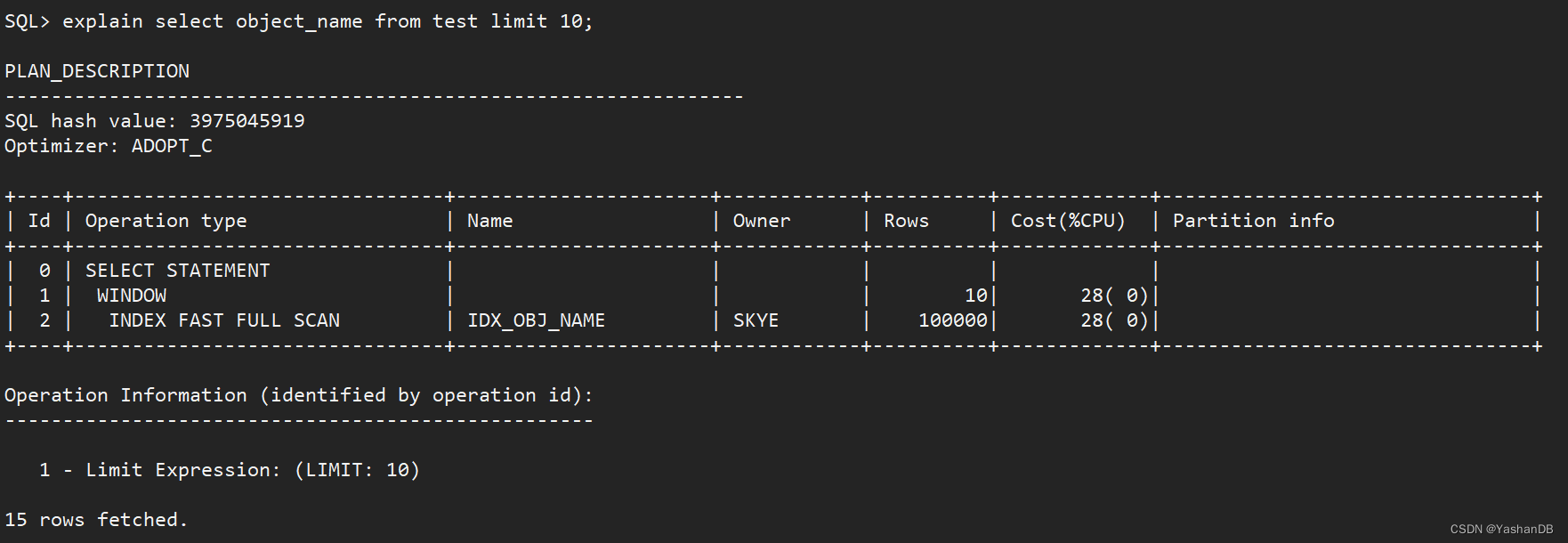
- 使用方式 2 的 set autotrace on explain
set autotrace on explain
select object_name from test limit 10;
可以看到输出了执行结果和执行计划:
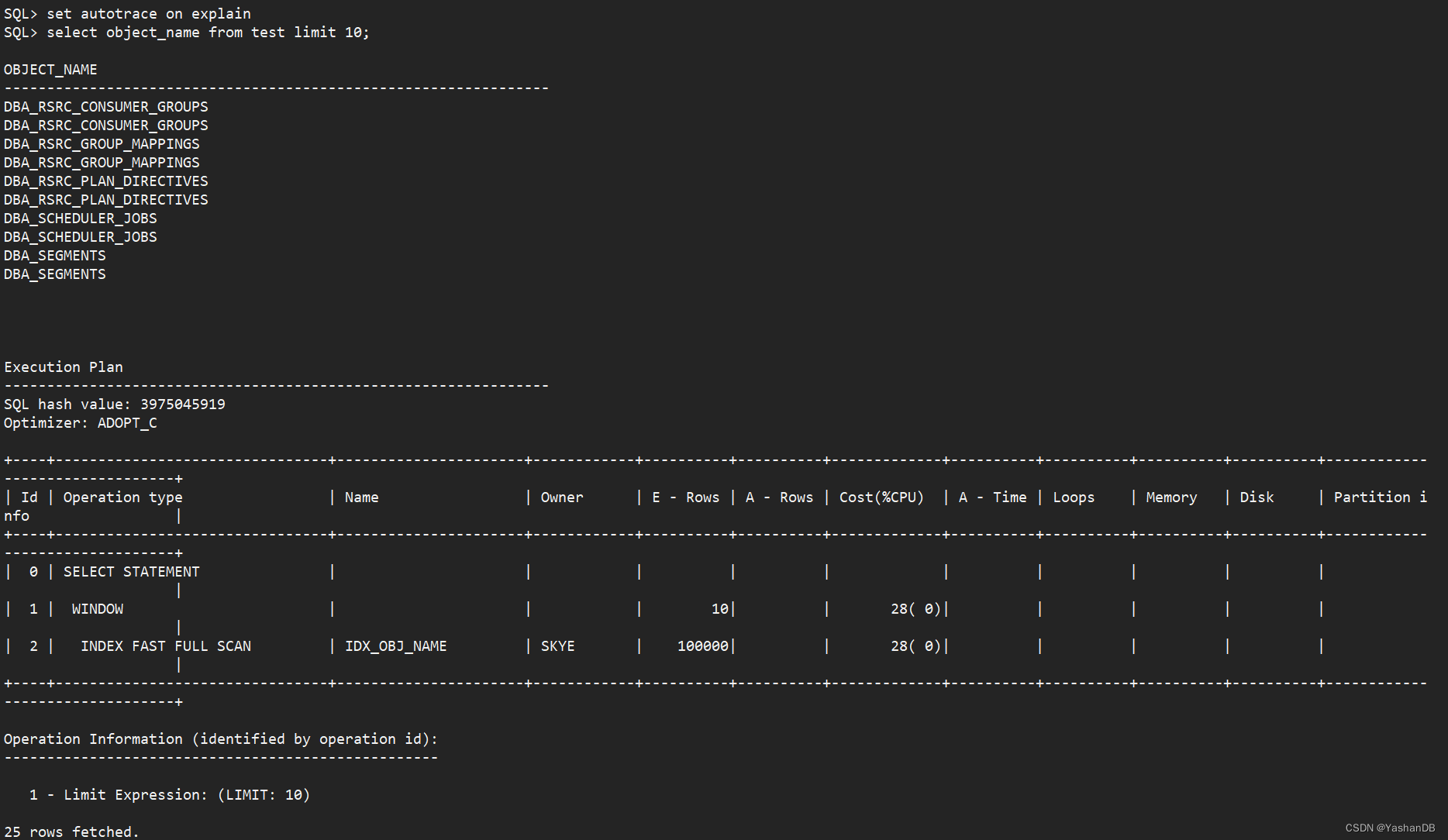
- 使用方式 2 的 set autotrace on statistics
(alter system set statistics_level=all;)
set autotrace on statistics
select object_name from test limit 10;
可以看到输出了执行结果和统计信息:
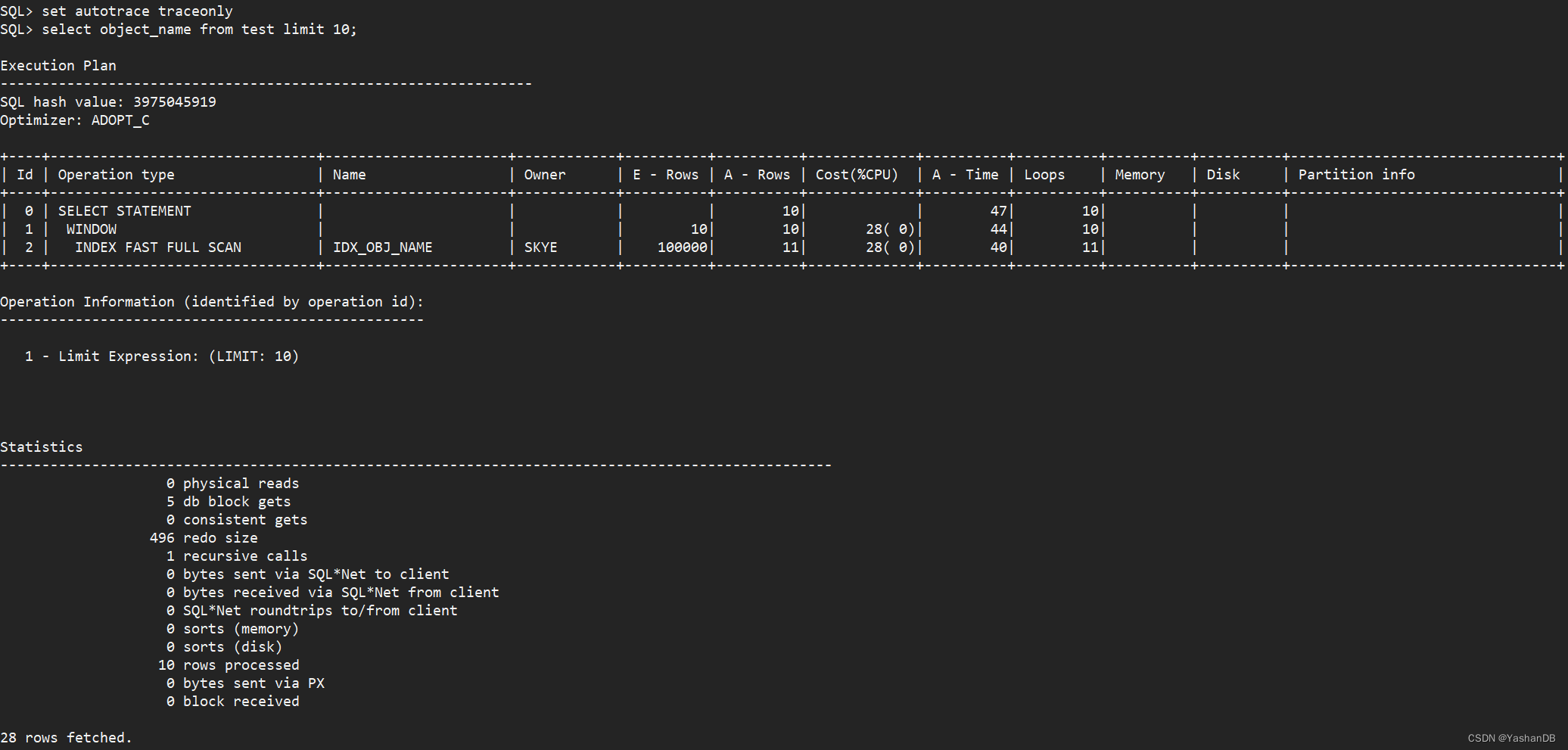
5. 使用方式 2 的 set autotrace traceonly
set autotrace traceonly
select object_name from test limit 10;
可以看到输出了执行计划和统计信息:
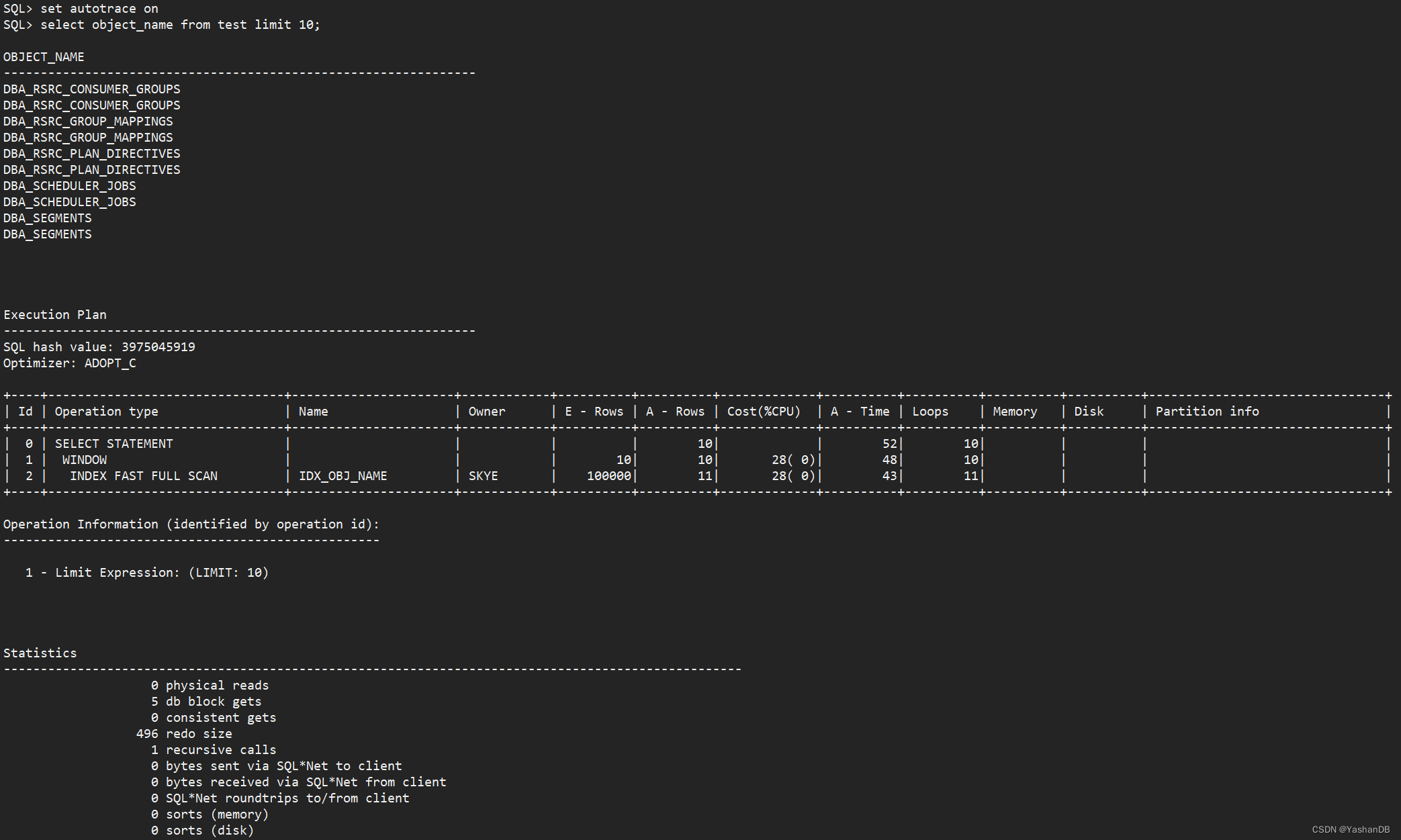
- 使用方式 2 的 set autotrace on
set autotrace on
select object_name from test limit 10;
可以看到输出了执行结果、执行计划以及统计信息:
7. 关闭 autotrace 和调整 statistics_level
当测试完毕后,需要将相关设置还原。
#关闭autotrace
set autotrace off测试完成,调整statistics_level为默认的typical
alter system set statistics_level=typical;
通过上面这个例子,相信大家对 explain 和 autotrace 的使用有了一个全面的了解。不同的使用方式会有不同的效果,大家根据实际情况选择合适的方法使用即可。
02 执行计划解读
还是上面这个例子,我们来看看执行计划里都有哪些信息,各代表什么含义。
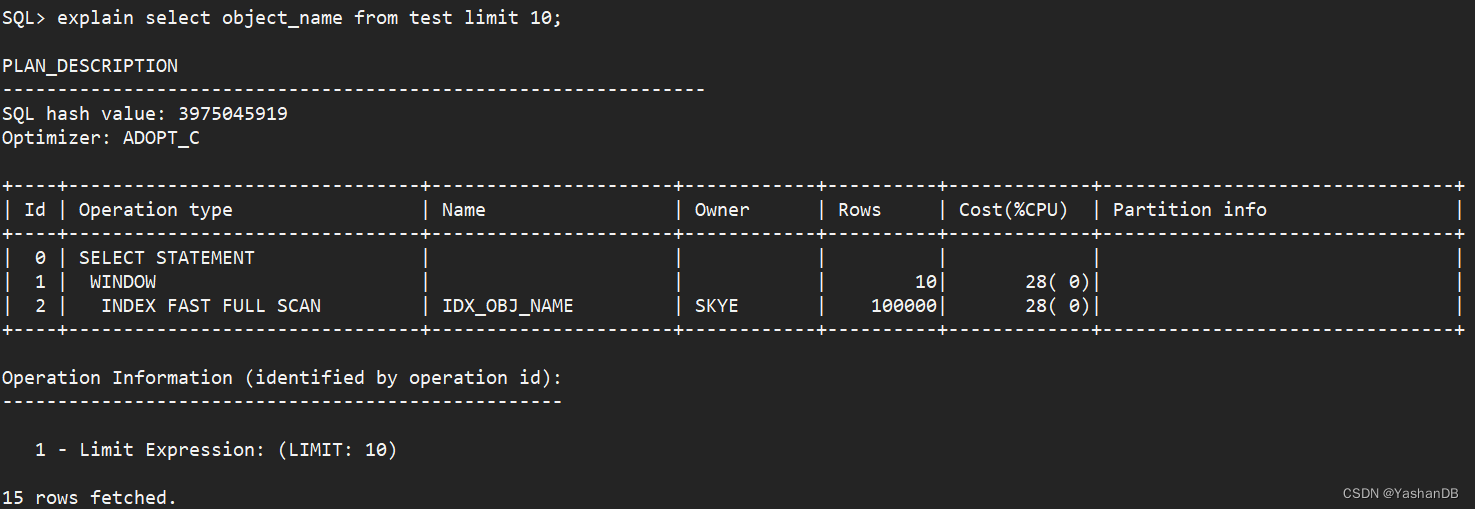
执行计划中各信息介绍如下:
- Id:执行步骤的唯一标识,并不是执行顺序。
- Operation type:执行算子,前面的空格标示计划的层次关系。
- INDEX FAST FULL SCAN:代表扫描方式是索引快速全扫描
- WINDOW:limit
- SELECT STATEMENT:代表是 SELECT 查询
- Name:对象名
- Owner:对象所属用户
- Rows:优化器根据统计信息和特定算法计算出来的行数预估值。图中显示的 100000 行其实不是真实的数据行数,为什么呢?咱们先留个悬念。
- Cost (% CPU):优化器根据算子和硬件等信息,算出的一个参考值,Cost 值越大,表示该层计划占用的资源越大。
- Partition info:分区相关信息,因为这张表未分区,所以没有该部分相关信息。
如果在某些极端场景导致优化器生成的执行计划并不是最优的,YashanDB 也提供可以手动修改执行计划的手段。
03 通过 hint 调整执行计划
一般情况下,优化器是可以做出最优的执行效果。如果我们的统计信息未收集或者收集失效,这时候优化器可能无法根据错误的统计信息做出最优的执行计划,需要我们手动调整。这时可以选择通过 hint 去调整执行计划。
hint 是一种特殊的注释,其格式和位置固定,作用是影响优化器对执行计划的选择,但非强制。
通过 hint 填写的内容可以分为以下三种:
- leading:改变表的 join 顺序;
- use_nl/use_hash/use_merge 等:改变表的连接类型;
- index/full 等:改变访问路径。
通过添加 hint /+full(test)/ 调整 SQL 使用全表扫描
explain select /*+full(test)*/ object_name from test limit 10;
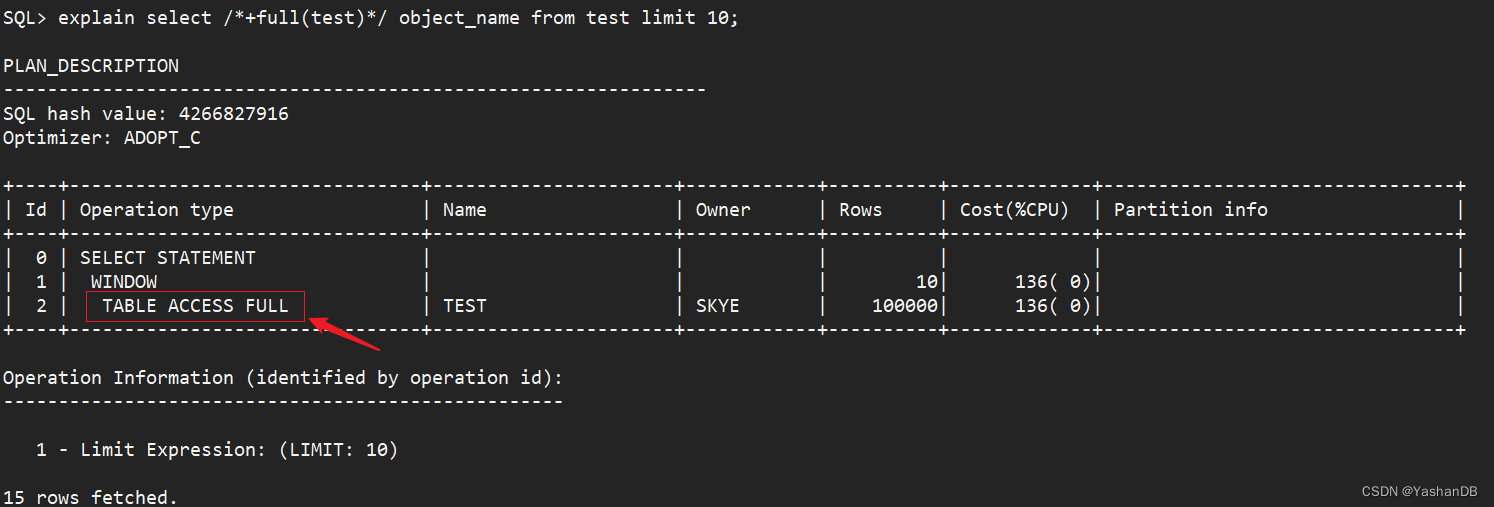
可以看到,通过 hint,将原本的索引快速全扫描(INDEX FAST FULL SCAN)调整为了全表扫描(TABLE ACCESS FULL)。
注:这里只是为了验证 hint 确实可以改变执行计划。在此用例中,全表扫描并不是最优的。*
统计信息的收集
在前面执行计划的解读中,TEST 表的预估行数是 100000,这其实是因为没有收集统计信息,系统给的默认值为 100000 行。下面我们来看看怎么收集统计信息。
01 查看统计信息是否有效
统计信息相关参数介绍如下:
- DBA_TAB_STATISTICS:表统计信息
- DBA_TAB_COL_STATISTICS:列统计信息
- DBA_IND_STATISTICS:索引的统计信息
- DBA_PART_COL_STATISTICS:分区列的统计信息
比如前面所使用的 test 表,并未收集过统计信息,通过视图查出来信息如下:
select table_name,last_analyzed,stale_stats from dba_tab_statistics where owner='SKYE' and table_name='TEST';# SKYE 是 TEST表的所属用户

LAST_ANALYZED 是指上一次该对象统计信息的收集时间,为空代表从未收集过。
02 统计信息收集方式
在 YashanDB 中,可以从全库、按用户、按表,3 个维度进行统计信息收集,来应对不同的场景。
情况 1:全库收集
exec DBMS_STATS.GATHER_DATABASE_STATS('GATHER', 1, 48, 'FOR ALL COLUMNS SIZE AUTO', 'ALL', TRUE, FALSE);
情况 2:按用户收集
exec DBMS_STATS.GATHER_SCHEMA_STATS('SKYE',1,TRUE,'FOR ALL COLUMNS SIZE AUTO',48,'ALL',TRUE);
情况 3:按表收集
exec DBMS_STATS.GATHER_TABLE_STATS('SKYE', 'TEST','', 1, FALSE, 'FOR ALL COLUMNS SIZE AUTO', 32, 'AUTO', TRUE);
注:一般大库、大表建议使用按表收集统计信息,因为收集统计信息也会消耗系统性能。这里的 1 代表采样率为 1,表数据量比较大的情况下可以使用 0.2 即可。这里的 32 代表并行度,如果系统 CPU 等资源充足,可以适当调大该值加快统计信息速度。
收集完 test 表统计信息之后,视图查询如下:
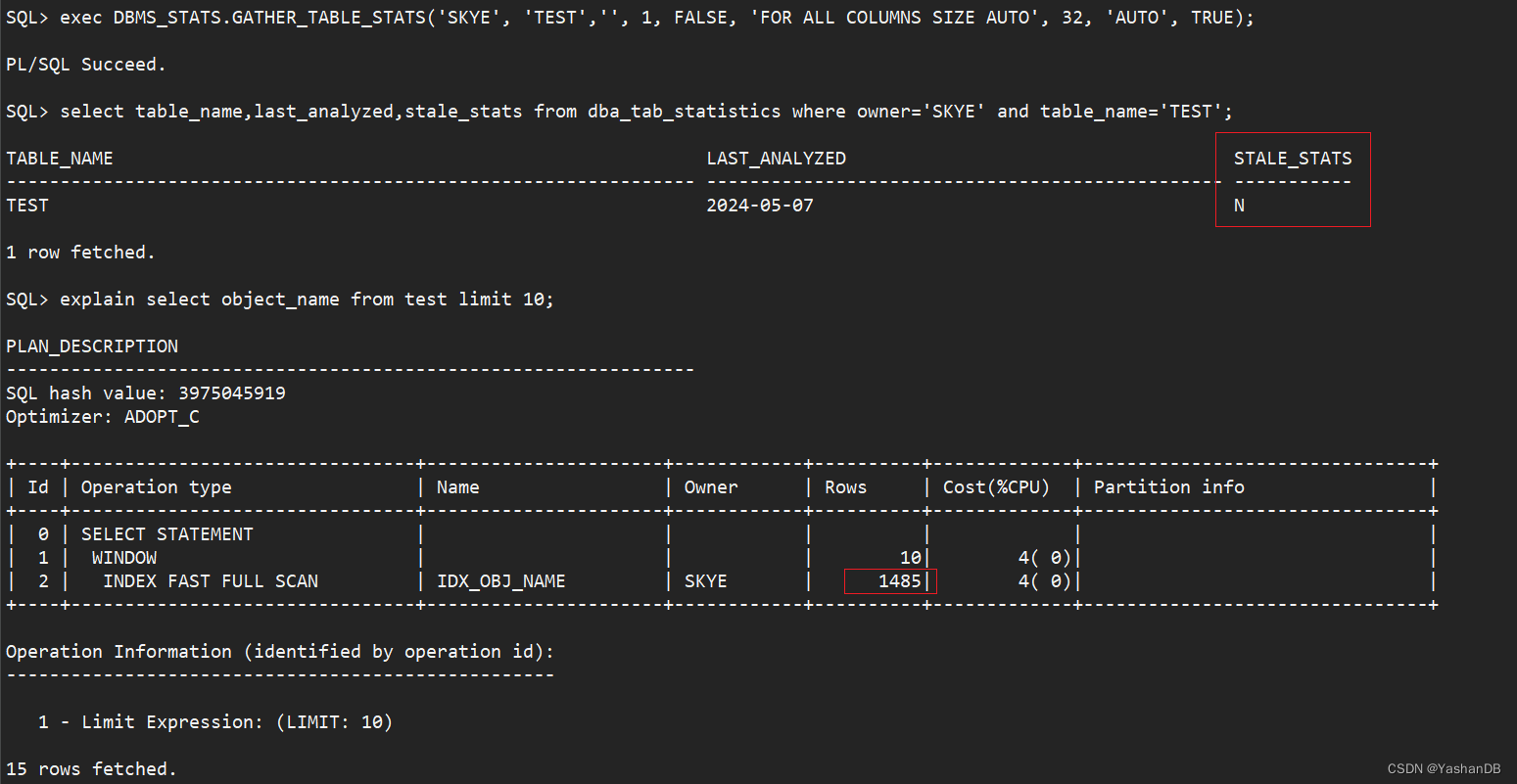
可以看到,统计信息收集完成之后,视图会记录该对象的收集情况,在执行计划的 Rows 估算中,能更加真实的预估行数,Cost 也会随之降低。
总结
很多时候 SQL 突然变慢,可能是执行计划改变了;而执行计划突然改变很可能是统计信息失效了,导致优化器不能根据真实的统计信息选择出最优的执行计划。从以往经验来看,可以先查看涉及到的表、分区和索引相关的统计信息是否是正常有效的。
工欲善其事,必先利其器。不论是 AWR、系统视图还是 slow log 工具,大家能够找到适合自己的某一种方法,熟练掌握即可。本文主要介绍的是通过慢日志功能进行 SQL 调优,感兴趣的同学也可以到 YashanDB 官网的文档中心参考官方文档,试试通过 AWR、系统视图等方式,找到慢 SQL 进行分析。
这篇关于SQL查询太慢?实战讲解YashanDB SQL调优思路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






