本文主要是介绍⌈ 传知代码 ⌋ 语音预训练模型wav2vec,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
- 💡本章重点
- 🍞一. 概述
- 🍞二. 基本原理
- 🍞三. 未来应用与挑战
- 🍞四. 参考案例
- 🍞五.部署文档
- 🫓总结
💡本章重点
- 语音预训练模型wav2vec
🍞一. 概述
论文:wav2vec: Unsupervised Pre-training for Speech Recognition
Wav2Vec(Waveform-to-Vector)是一种在语音处理领域中具有重要意义的技术。它的由来可以追溯到Facebook AI Research(FAIR)在2019年提出的一篇论文,旨在解决语音识别中的数据标记问题。传统的语音识别系统通常需要大量标记好的语音数据进行训练,但这一过程非常耗时且昂贵。Wav2Vec的目标是通过自监督学习的方法,从未标记的语音数据中学习有用的语音表示,从而减少对标记数据的依赖。
Wav2Vec在语音处理领域具有重要的应用前景。语音是一种丰富的信息形式,但传统的语音处理技术往往受限于标记数据的稀缺性和高成本,限制了语音处理技术的发展。Wav2Vec的出现为解决这个问题提供了一种新的思路,它使我们能够更有效地使用未标记的语音数据,提高语音处理任务的性能和可扩展性。因此,Wav2Vec在语音识别、语音合成、语音情感分析等领域有广泛的应用前景。
🍞二. 基本原理
文章提出一种无监督的语音预训练模型 wav2vec,可迁移到语音下游任务。模型预训练一个简单的多层卷积神经网络,并提出了一种噪声对比学习二分类任务(noise contrastive binary classification task),从而使得wav2vec可以在大量未标注的数据上进行训练。实验结果表明wav2vec预训练得到的speech representation超越了帧级别的音素分类任务并且可以显著提升ASR模型的表现,同时,完全卷积架构与使用的递归模型相比,可以在硬件上并行计算。
模型结构如下图,首先将原始音频x编码为潜在空间z的 encoder network(5层卷积),再将潜在空间z转换为contextualized representation(9层卷积),最终特征维度为512x帧数。目标是在特征层面使用当前帧预测未来帧。
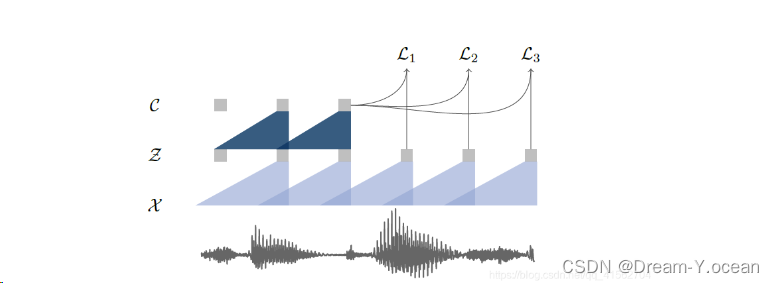
模型将原始音频信号 x 作为输入,基于历史信息和当前输入的信息预测未来的某些采样点,这里使用了两个编码器进行计算。
- 编码器网络f(encoder network) 将音频信号嵌入到特征空间(latent space) 中将每个xi映射为一个特征向量zi, 类似于language model模型那样获得一个编码向量, 再基于此预测某个zi, 这里j>i;
- 上下文网络g(context network) 结合了多个时间步长编码器以获得上下文表示(contextualized representations) 如图1。将多个zi转化为context representation C.这里有 $ c_ {i} $ =g( $ z_ {i} $ , $ z_ {i-1} $ $ \cdots $ $ z_ {v} $ )。这里的v为感受野(receptive field size)
然后, 两个网络的输出Z, C都用于损失函数(loss function) 的计算。作者在实验中使用了两种不同的感受野模型, 一种为普通规模, 用来在一般数据集上训练, 另一种则是大规模(wav2vec larqe) 用来在大数据集上训练。在这两种模型中的感受野分别对应210ms和810ms.
模型的loss中自然要包含预测未来某个z的损失。然而仅仅有正例是不够的, 因此作者利用了负采样技术, 作者从一个概率分布 $ p_ {n} $ 中采样出负样本z,最终模型的loss为区分正例和反例的contrastive loss [1]:
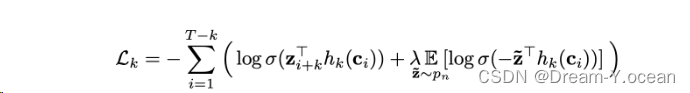
于正样本,损失函数的第一项是负对数似然损失。它衡量了模型预测下一个上下文的编码的准确性。具体地说,对于每个上下文 Ci,模型使用当前上下文的编码作为输入,然后预测下一个上下文的编码。通过比较预测的编码和实际编码,我们可以计算出负对数似然损失。模型使用当前上下文的编码作为输入,然后预测下一个上下文的编码。通过比较预测的编码和实际编码,我们可以计算出负对数似然损失。
通过将这两个项相加,我们得到了wav2vec模型的总损失函数。这个损失函数的目标是最小化正样本的负对数似然损失,同时确保负样本的正则化项尽可能小。这样,模型可以学习到一个有效的编码器,将语音信号映射到有用的表示空间中,以便后续的语音识别任务。
🍞三. 未来应用与挑战
Wav2Vec在语音处理领域有多种应用。它在语音识别中具有重要的作用。通过学习有用的语音表示,Wav2Vec可以显著改善传统的基于标记数据的语音识别系统。其次,Wav2Vec也可以用于语音合成,即将文本转化为语音。通过学习语音表示,Wav2Vec可以生成自然流畅的语音输出。此外,Wav2Vec还可以应用于语音情感分析,帮助识别和理解说话者的情感状态。
然而,Wav2Vec也面临一些挑战。训练一个高质量的Wav2Vec模型通常需要大量的计算资源和时间。模型的训练过程可能需要在大规模的语音数据上进行,并且可能需要使用分布式计算平台。其次,Wav2Vec在处理长时间的语音数据时可能存在一些限制,因为较长的语音片段可能导致内存和计算资源的限制。此外,Wav2Vec对于噪声和低质量语音数据的鲁棒性还有待改进。vq-wav2vec、wav2vec2 进行了相关的改进,感兴趣可以进一步学习。
🍞四. 参考案例
如果有开源的实现可用,可以使用相应的库和工具来简化这些步骤。例如,Facebook fairseq 源码库提供了Wav2Vec相关的模型和工具,可以方便地训练和使用Wav2Vec模型。以下是一个使用Hugging Face库的代码:
import torch
import fairseqcp_path = 'wav2vec_large.pt'
model, cfg, task = fairseq.checkpoint_utils.load_model_ensemble_and_task([cp_path])
model = model[0]
model.eval()wav_input_16khz = torch.randn(1,10000)
z = model.feature_extractor(wav_input_16khz)
c = model.feature_aggregator(z)
🍞五.部署文档
-
源码库地址 GitHub(FAIR):https://github.com/pytorch/fairseq
-
文档地址: https://github.com/facebookresearch/fairseq/blob/main/examples/wav2vec/README.md
-
源码系列: https://paperswithcode.com/paper/unsupervised-speech-recognition#code
🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】

这篇关于⌈ 传知代码 ⌋ 语音预训练模型wav2vec的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




