本文主要是介绍【Text2SQL 论文】T5-SR:使用 T5 生成中间表示来得到 SQL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:T5-SR: A Unified Seq-to-Seq Decoding Strategy for Semantic Parsing
⭐⭐⭐
北大 & 中科大,arXiv:2306.08368
文章目录
- 一、论文速读
- 二、中间表示:SSQL
- 三、Score Re-estimator
- 四、总结
一、论文速读
本文设计了一个 NL 和 SQL 的中间表示 SSQL,然后使用 seq2seq 模型,输入 NL 和 table schema,输出 SSQL,然后再基于 SSQL 构建出 SQL。
论文提出了使用 seq2seq 来做 Text2SQL 的两个挑战:
- seq2seq 能否产生模式上正确的 SQL?论文发现,seq2seq 模型能够产生合法的 SQL skeleton,但细节上的 schematic info prediction 容易出错。因此,本文引入 SSQL 作为 seq2seq 的中间表示,SSQL 目标是保留 NL 的语义信息,但去除掉 user query 没有表达的 database-schema-related 信息。
- seq2seq 能否产生语义一致的 SQL?论文指出,由于 seq2seq 的单向解码的机制,产生整个语义一致的 sequences 是难以保证的,QA 场景也许有较大容错性,但这在生成 SQL 上会产生灾难性失败。此外,论文发现 seq2seq 模型在使用 beam search 时是能够预测出正确的 SQL,但可能会给他们较低的 scores。为此,这里引入一个 score re-estimator 来重排所有 candidate predictions。
二、中间表示:SSQL
Semantic-SQL(SSQL)的设计目标是去除掉标准 SQL 表达式中不必要的 schema-related 信息。主要基于原来的 SQL 语法做了如下改动:
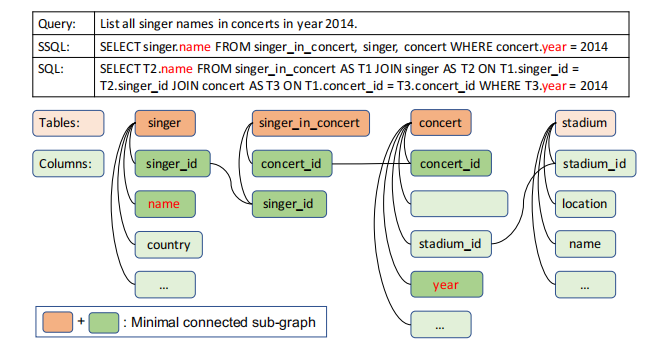
- 通过消除掉 JOIN 子句来简化 FROM 语句。SSQL 只预测出需要哪些表,但不需要指明如何 JOIN 起来,后序会使用 Steiner Tree Algorithm 来将使用的 tables JOIN 起来,从而生成 SQL。
- 将 TABLE 和 COLUMN 结合为一个 string。标准 SQL 是 column 名和 table 名分开的,这里将输入的 schema 中将 TABLE 和 COLUMN 连接在一起,那输出中也就自然在一起了。
下面是一个 SSQL 的示例以及 JOIN 子句的预测:
三、Score Re-estimator
由于 seq2seq 在使用 beam search 时,可能会给 correct prediction 赋予较低的 scores,因此这里引入额外的 score re-estimator 来重新排序所有的 candidate predictions。score re-estimator 就是根据 candidate SQL 和 NL query 之间的语义一致性来计算一个得分。
score re-estimator 的实现图示如下:
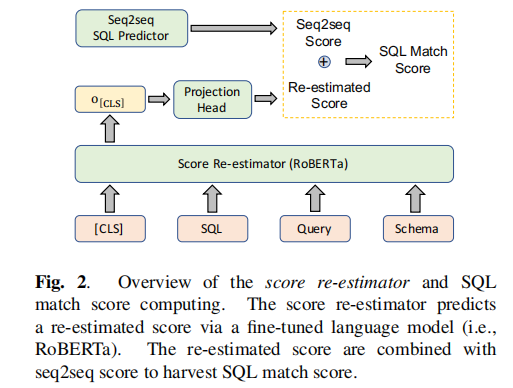
它通过 [CLS] 得到一个分数,并将其与 seq2seq score 进行加权组合来得到最终的 score:

seq2seq score 是在生成 token 时,根据 seq2seq 生成 token 的概率值来计算得到的,这个 score 可以看作是生成该序列的 log-likelihood,即模型认为这个序列是正确输出的相对可能性。在 beam-search 策略中,会选择概率最高的序列作为最终生成的序列。
训练 score re-estimator 的方法,就是期待它能给正确的 NL-SQL pair 以更高的概率分,在做监督训练时,论文还采用了一个 trick:使用 soft logits 作为监督信号,原论文解释如下:

这样能更加对 beam search 中排名最高的候选者保持怀疑的态度。
四、总结
本文模型是通过引入中间表示并使用 seq2seq(T5)来解决 Text2SQL 任务,同时论文中也指出了使用 seq2seq 在 Text2SQL 任务下的难点。
该工作还引入了 SSQL 这样的中间表示,它比 SemQL、RAT-SQL IR 等中间表示要简单不少。
这篇关于【Text2SQL 论文】T5-SR:使用 T5 生成中间表示来得到 SQL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





