本文主要是介绍【Python安全攻防】【网络安全】一、常见被动信息搜集手段,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、IP查询
原理:通过目标URL查询目标的IP地址。
所需库:socket
Python代码示例:
import socketip = socket.gethostbyname('www.163.com')
print(ip)
上述代码中,使用gethostbyname函数。该函数位于Python内置的socket库中,其原型如下:
def gethostbyname(host): # real signature unknown; restored from __doc__"""gethostbyname(host) -> addressReturn the IP address (a string of the form '255.255.255.255') for a host."""pass
参数host为目标的URL,返回对应的ip地址。
示例代码输出:
125.39.47.211Process finished with exit code 0
二、Whois查询
原理:用来查询域名是否已经被注册,以及注册域名的详细信息。
所需库:whois
安装whois模块:
pip install python-whois

记录
执行上述命令后,导入会报错(找不到Whois模块)(在PyCharm中,IDLE则未出现此问题),需要在报错处再次执行安装命令。另一个方法是在终端中直接执行安装命令,并在IDLE中运行代码:


Python代码示例:
from whois import whois
data = whois("www.163.com")print(data)
示例代码输出(含注释说明):
{"domain_name": [ # 域名:163.com"163.COM","163.com"],"registrar": "MarkMonitor Information Technology (Shanghai) Co., Ltd.", # 注册公司"whois_server": "whois.markmonitor.com", # whois服务器地址"referral_url": null,"updated_date": [ # 更新日期和时间"2023-09-22 06:35:34","2024-04-29 01:59:31+00:00"],"creation_date": [ # 创建日期和时间"1997-09-15 04:00:00","1997-09-15 04:00:00+00:00"],"expiration_date": [ # 过期日期和时间"2027-09-14 04:00:00","2027-09-14 04:00:00+00:00"],"name_servers": [ # DNS解析服务器地址"NS1.NEASE.NET","NS2.166.COM","NS3.NEASE.NET","NS4.NEASE.NET","NS5.NEASE.NET","NS6.NEASE.NET","NS8.166.COM","ns4.nease.net","ns2.166.com","ns1.nease.net","ns6.nease.net","ns5.nease.net","ns8.166.com","ns3.nease.net"],"status": [ # 服务器状态"clientDeleteProhibited https://icann.org/epp#clientDeleteProhibited","clientTransferProhibited https://icann.org/epp#clientTransferProhibited","clientUpdateProhibited https://icann.org/epp#clientUpdateProhibited","serverDeleteProhibited https://icann.org/epp#serverDeleteProhibited","serverTransferProhibited https://icann.org/epp#serverTransferProhibited","serverUpdateProhibited https://icann.org/epp#serverUpdateProhibited","clientUpdateProhibited (https://www.icann.org/epp#clientUpdateProhibited)","clientTransferProhibited (https://www.icann.org/epp#clientTransferProhibited)","clientDeleteProhibited (https://www.icann.org/epp#clientDeleteProhibited)"],"emails": [ # 联络邮箱"abusecomplaints@markmonitor.com","whoisrequest@markmonitor.com"],"dnssec": "unsigned","name": null,"org": "\u5e7f\u5dde\u7f51\u6613\u8ba1\u7b97\u673a\u7cfb\u7edf\u6709\u9650\u516c\u53f8","address": null,"city": null,"state": "Guang Dong", # 城市(对应美国的“州”):广东"registrant_postal_code": null, # 注册者邮编(无)"country": "CN" # 国家码
}
三、子域名挖掘
通过必应(必应搜索引擎)进行子域名搜集:
首先确保安装有requests库、bs4库、urllib库,安装这些库的命令和过程如下:
Python代码示例:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse
import sysdef bing_search(site, pages):Subdomain = []headers = {"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0","Accept": "text/html,application/xhtml+xml, application/xml;q=0.9,*/*;q=0.8","Referer": "https://cn.bing.com"}for i in range(1, int(pages)+1):url = "https://cn.bing.com/search?q=site%3a"+site+"&go=Search&qs=ds&first="+ str((int(i)-1) * 10) + "&FROM=PERE"html = requests.get(url, headers=headers)soup = BeautifulSoup(html.content, 'html.parser')job_bt = soup.findAll('h2')for i in job_bt:link = i.a.get('href')domain = str(urlparse(link).scheme + "://" + urlparse(link).netloc)if domain in Subdomain:passelse:Subdomain.append(domain)print(domain)if __name__ == '__main__':if len(sys.argv) == 3:site = sys.argv[1] # 参数1:网址page = sys.argv[2] # 参数2:获取搜索引擎页数else:print("usage: %s baidu.com 10" % sys.argv[0])sys.exit(-1)Subdomain = bing_search(site,page)
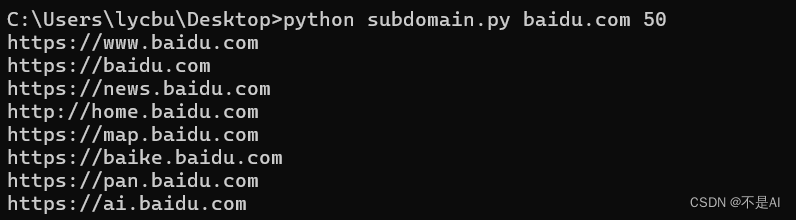
对域名baidu.com进行子域名收集,获取50页搜索结果:
参考书目
《Python安全攻防——渗透测试实战指南》,MS08067安全实验室 编著,北京,机械工业出版社,2021年10月第1版。
这篇关于【Python安全攻防】【网络安全】一、常见被动信息搜集手段的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





