本文主要是介绍[7] CUDA之常量内存与纹理内存,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CUDA之常量内存与纹理内存
1. 常量内存
- NVIDIA GPU卡从逻辑上对用户提供了 64KB 的常量内存空间,可以用来存储内核执行期间所需要的恒定数据
- 常量内存对一些特定情况下的小数据量的访问具有相比全局内存的额外优势,使用常量内存也一定程序上减少了对全局内存的带宽占用
- 常量内存具有
cache缓冲 - 下边例举一个简单的程序进行
a * x + b的数学运算
#include "stdio.h"
#include<iostream>
#include <cuda.h>
#include <cuda_runtime.h>
//Defining two constants
__constant__ int constant_f;
__constant__ int constant_g;
#define N 5
//Kernel function for using constant memory
__global__ void gpu_constant_memory(float *d_in, float *d_out) {//Thread index for current kernelint tid = threadIdx.x; d_out[tid] = constant_f*d_in[tid] + constant_g;
}
- 常量内存中的变量使用
__constant__关键字修饰 - 使用
cudaMemcpyToSymbol函数吧这些常量复制到内核执行所需要的常量内存中 - 常量内存应合理使用,不然会增加程序执行时间
- 主函数调用如下:
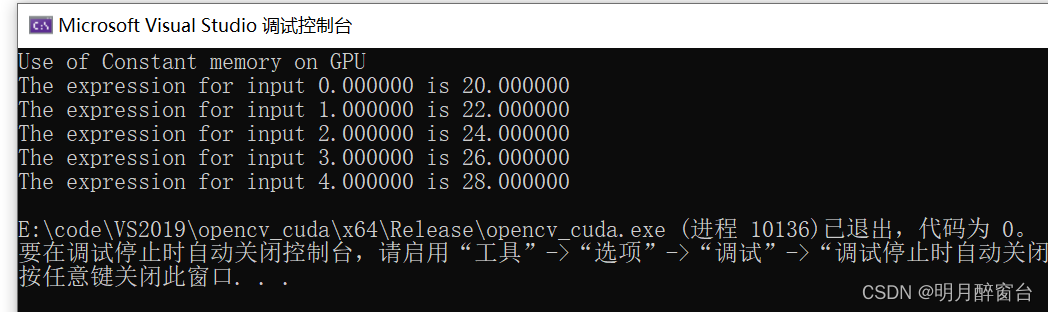
int main(void) {//Defining Arrays for hostfloat h_in[N], h_out[N];//Defining Pointers for devicefloat *d_in, *d_out;int h_f = 2;int h_g = 20;// allocate the memory on the cpucudaMalloc((void**)&d_in, N * sizeof(float));cudaMalloc((void**)&d_out, N * sizeof(float));//Initializing Arrayfor (int i = 0; i < N; i++) {h_in[i] = i;}//Copy Array from host to devicecudaMemcpy(d_in, h_in, N * sizeof(float), cudaMemcpyHostToDevice);//Copy constants to constant memorycudaMemcpyToSymbol(constant_f, &h_f, sizeof(int),0,cudaMemcpyHostToDevice);cudaMemcpyToSymbol(constant_g, &h_g, sizeof(int));//Calling kernel with one block and N threads per blockgpu_constant_memory << <1, N >> >(d_in, d_out);//Coping result back to host from device memorycudaMemcpy(h_out, d_out, N * sizeof(float), cudaMemcpyDeviceToHost);//Printing result on consoleprintf("Use of Constant memory on GPU \n");for (int i = 0; i < N; i++) {printf("The expression for input %f is %f\n", h_in[i], h_out[i]);}//Free up memorycudaFree(d_in);cudaFree(d_out);return 0;
}
2. 纹理内存
- 纹理内存时另外一种当数据的访问具有特定的模式的时候能够加速程序执行,并减少显存带宽的制度存储器,像常量内存一样,它也在芯片内部被
cache缓冲 - 该存储器最初是为了图像绘制而设计的,但也可以被用于通过计算
- 当程序进行具有很大程序上的空间临近性的访存的时候,这种存储器变得非常高效。空间临近性的意思是:每个现成的读取位置都和其他现成的读取位置临近,这对那些需要处理4个临近的相关点和8个临近的点的图像处理应用非常有用。一种线程进行2D的平面空间临近性的访存的例子,可能会像下表:

- 通用的全局内存的
cache将不能有效处理这种空间临近性,可能会导致进行大量的显存读取传输。纹理存储器被设计成能够利用这种方寸模型,这样它只会从显存读取1次,然后缓冲掉,因此执行速度会快得多 - 纹理内存支持2D和3D的纹理读取操作,但编程可能没有那么容易
- 下边给出一个通过纹理内存进行数组赋值的例子:
#include "stdio.h"
#include<iostream>
#include <cuda.h>
#include <cuda_runtime.h>
#define NUM_THREADS 10
#define N 10//纹理内存定义
texture <float, 1, cudaReadModeElementType> textureRef;
__global__ void gpu_texture_memory(int n, float *d_out)
{int idx = blockIdx.x*blockDim.x + threadIdx.x;if (idx < n) {float temp = tex1D(textureRef, float(idx));d_out[idx] = temp;}
}int main()
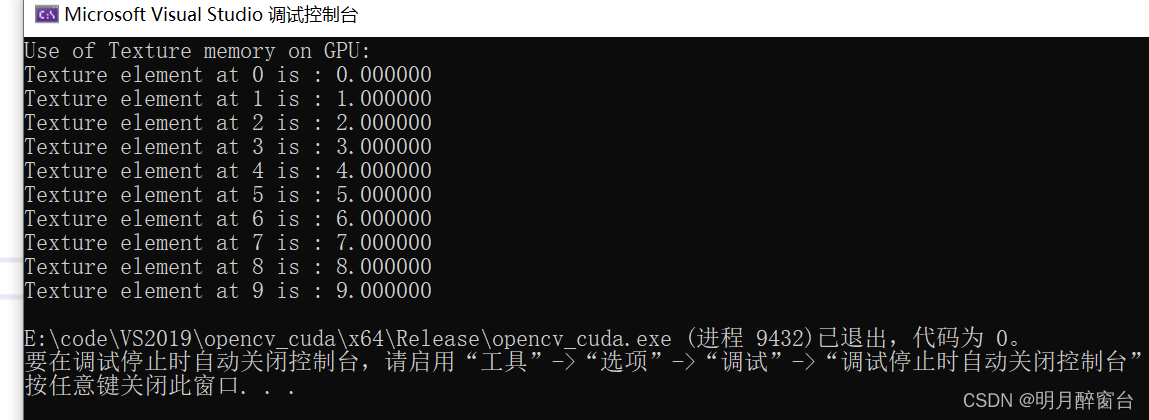
{//Calculate number of blocks to launchint num_blocks = N / NUM_THREADS + ((N % NUM_THREADS) ? 1 : 0);//Declare device pointerfloat *d_out;// allocate space on the device for the resultcudaMalloc((void**)&d_out, sizeof(float) * N);// allocate space on the host for the resultsfloat *h_out = (float*)malloc(sizeof(float)*N);//Declare and initialize host arrayfloat h_in[N];for (int i = 0; i < N; i++) {h_in[i] = float(i);}//Define CUDA ArraycudaArray *cu_Array;cudaMallocArray(&cu_Array, &textureRef.channelDesc, N, 1);//Copy data to CUDA Array,(0,0)表示从左上角开始cudaMemcpyToArray(cu_Array, 0, 0, h_in, sizeof(float)*N, cudaMemcpyHostToDevice);// bind a texture to the CUDA arraycudaBindTextureToArray(textureRef, cu_Array);//Call Kernel gpu_texture_memory << <num_blocks, NUM_THREADS >> >(N, d_out);// copy result back to hostcudaMemcpy(h_out, d_out, sizeof(float)*N, cudaMemcpyDeviceToHost);printf("Use of Texture memory on GPU: \n");for (int i = 0; i < N; i++) {printf("Texture element at %d is : %f\n",i, h_out[i]);}free(h_out);cudaFree(d_out);cudaFreeArray(cu_Array);cudaUnbindTexture(textureRef);}
- 纹理引用是通过
texture<>类型的变量进行定义的,定义是的三个参数意思是:
texture <p1, p2, p3> textureRef;
p1: 纹理元素的类型
p2: 纹理引用的类型,可以是1D,2D,3D的
p3:读取模式,是个可选参数,用来说明是否要执行读取时候的自动类型转换
- 一定要确保纹理引用被定义成全局静态变量,同时还要确保它不能作为参数传递给任何其他函数
cudaBindTextureToArray函数将纹理引用和CUDA数组进行绑定- 运行结果如下:
- ------ end------
这篇关于[7] CUDA之常量内存与纹理内存的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






