本文主要是介绍毕设 大数据校园卡数据分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 0 前言
- 1 课题介绍
- 2 数据预处理
- 2.1 数据清洗
- 2.2 数据规约
- 3 模型建立和分析
- 3.1 不同专业、性别的学生与消费能力的关系
- 3.2 消费时间的特征分析
- 4 Web系统效果展示
- 5 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 基于yolov5的深度学习车牌识别系统实现
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
🧿 选题指导, 项目分享:见文末
1 课题介绍
近年来,大数据的受关注程度越来越高。如何对大数据流进行抽取转换成有用的信息并应用于各行各业变得越来越重要。如今,校园一卡通系统在高校应用十分广泛,大部分高校主要利用校园一卡通对校园中的各类消费阅、补助领取等进行统一管理。通过数据分析算法,对大学生校内消费记录进行整理、分类、预测,从而整体反应学生在校消费情况,形成量化的评判标准,同时也为今后的贫困生资助管理工作提供可靠的数据支持,辅助完成贫困生的相关工作。
2 数据预处理
在进行数据挖掘或者数据分析之前,需要对“脏数据” 数据进行数据预处理,一般采用数据清理、数据集成、数据变换等方式,已获得更好的分析效果。
2.1 数据清洗
由于数据库中有着大量的数据表,我们获取到的数据表中会存在着异常数据,如数据不合法与常识不符,同一个字段属性值来源于多张数据表且数值不一样等。数据预处理主要去处可忽略的字段、忽略空缺记录、可处理噪声的数据、可删除的数据等。由于部分校园卡用户,如教职工、研究生等,消费时具有很强的随机性和离散型。同时,为了保护隐私,对姓名、学号等属性要做脱敏和隐私处理。
2.2 数据规约
预处理后的数据不一定适合直接使用,因此需要对数据进行集成和变换,将多个数据库中提取出的数据项整合到一起,组成新的数据集环境,并经过详细对比和筛选解决数据不一致和数据冗余等问题。为了适合分析,我们要对数据进行离散化和概念分层处理。
3 模型建立和分析
通过建立消费数据分析模型,对学校校园卡消费行为进行分析,总结学校学生消费特征,对不同消费类型的学生进行用户画像和分类。以学生的“性别”、“专业”分类作为横向分类,以“消费能力(金额)”,“消费项目”,“消费时间”和“消费地点”四个方面为纵向分类,组成分析模型。寻找消费特征进行进行总结,形成假设结论。
#1.总体消费情况
#2.不同专业、性别的学生与消费能力的关系
#3.不同性别的学生与消费项目的关系
#4.消费时间的特征分析
#5.消费地点与门禁通过地点的关系分析
#6.学生消费特征分层模型
import matplotlib.pyplot as plt
expen_rec = pd.read_csv(r'C:\Users\River\Desktop\校园卡数据\expen_rec.csv',encoding='gbk')
student = pd.read_csv(r'C:\Users\River\Desktop\校园卡数据\student.csv',encoding='gbk')
access = pd.read_csv(r'C:\Users\River\Desktop\校园卡数据\access.csv',encoding='gbk')
all_data1 = pd.merge(expen_rec,student,on ='校园卡号',how='left')
all_data1.head()
3.1 不同专业、性别的学生与消费能力的关系
from pylab import *
plt.rcParams['font.sans-serif']=['SimHei']
%matplotlib inline
total = con_sum.groupby(['性别'])[['消费金额']].sum()
total1= con_sum.groupby(['性别'])[['消费金额']].count()
plt.subplot(121)
plt.pie(total['消费金额'],labels=total.index,autopct='%2.f%%')
plt.title('男女生消费总金额对比')
plt.subplot(122)
plt.pie(total1['消费金额'],labels=total1.index,autopct='%2.f%%')
plt.title('男女生人数对比')
plt.show()
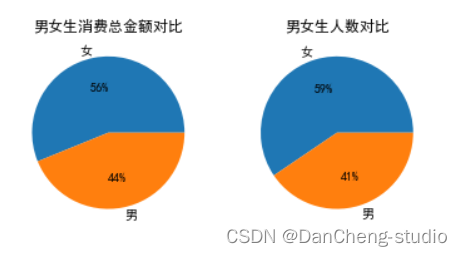
fig1 = plt.figure(num =1, figsize=(8,4))
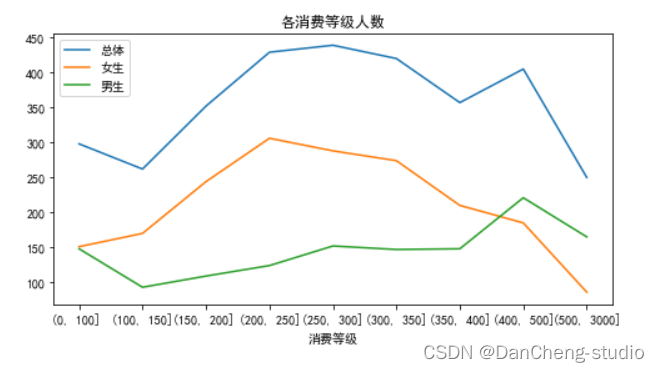
plt.title('各消费等级人数')
plt.xlabel('消费等级')
x1 =['(0, 100] ','(100, 150]','(150, 200] ','(200, 250]','(250, 300]','(300, 350]','(350, 400]','(400, 500]','(500, 3000]']
y1 = list(table1.values)
y2 =list(table2.loc[('女',slice(None))].values)
y3 =list(table2.loc[('男',slice(None))].values)
plt.plot(x1,y1,label='总体')
plt.plot(x1,y2,label='女生')
plt.plot(x1,y3,label='男生')
plt.legend(loc=2)
plt.show()
#分析各专业总消费金额排列
fig2 = plt.figure(num =2, figsize=(14,6))
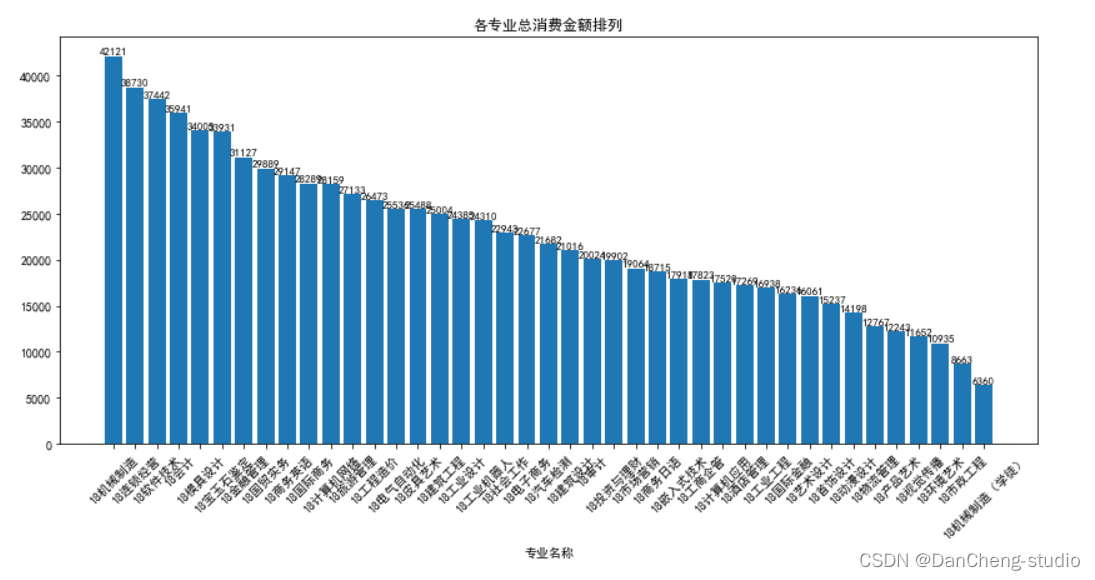
plt.title('各专业总消费金额排列')
plt.xlabel('专业名称')
x1=table3.index
y1=table3['消费总金额']
plt.bar(x1,y1)
plt.xticks(x1,x1,rotation=45)
for a,b in zip(x1,y1):plt.text(a, b+0.05, '%.0f' % b, ha='center', va= 'bottom',fontsize=9)
plt.show()
小结:
1.该校18级学生的人均每月校园卡消费295.96元;
2.女生人数占比59%,总消费额占比56%,消费总金额与性别差异不大;
3.从消费金额级区间上看,学生的总体消费金额主要在[200,500]的区间内,但男女生消费存在明显差异:女生消费金额在[200-350]区间内人数明显高于男生,但随着增加而下降,而男生在400以上的区间内的人数高于女生。男生对校园卡消费方式差异较大,一般不使用或者经常使用。女生多数选择轻度使用。
4.从各专业消费总金额上看机械制造专业最高,机械制造(学徒)专业最低。但结合各专业的人均消费分析,各专业的人均消费差异很小,标准差仅为42.8。人均消费最高的机械制造(学徒)专业因为人数最少仅为14人,对总体数据影响较小。可以得出:学生的校园卡消费能力与专业无明显区别。
3.2 消费时间的特征分析
fig7 = plt.figure(num =7, figsize=(8,4))
mon1= time_tab.groupby(['日期'])[['消费金额']].count()
mon2= time_tab1.groupby(['日期'])[['消费金额']].count()
mon3= time_tab2.groupby(['日期'])[['消费金额']].count()
plt.title('月度消费次数趋势分析')
plt.xlabel('日期')
x1 = list(mon1.index)
y1 = list(mon1.values)
y2 =list(mon2.values)
y3 =list(mon3.values)
plt.plot(x1,y1,label='总体')
plt.plot(x1,y2,label='女生')
plt.plot(x1,y3,label='男生')
plt.legend(loc=2)
plt.show()
#除个别天数外,女生均高于男生,每周之间趋势相似
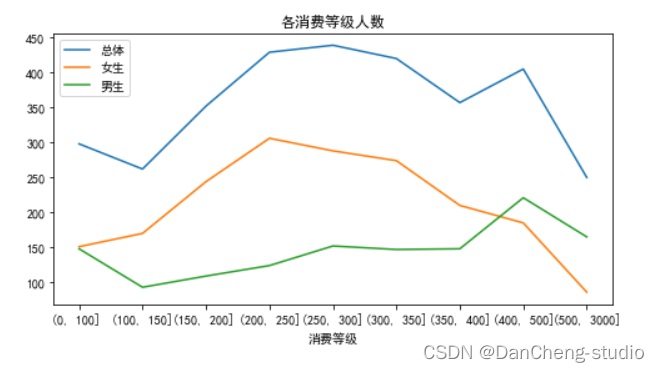
fig8 = plt.figure(num =8, figsize=(8,4))
wk1= time_tab.groupby(['星期'])[['消费金额']].count()
wk2= time_tab1.groupby(['星期'])[['消费金额']].count()
wk3= time_tab2.groupby(['星期'])[['消费金额']].count()
def autolabel(rects):for rect in rects:height = rect.get_height()plt.text(rect.get_x()+rect.get_width()/2.-0.2, 1.03*height, '%s' % float(height))
plt.title('月度消费次数趋势分析')
plt.xlabel('星期')
y1 = wk2['消费金额']
y2 = wk3['消费金额']
x1=range(len(y1))
x2=[i +0.35 for i in x1]
a=plt.bar(x1,y1, width=0.3,label='女生',color='blue')
b=plt.bar(x2,y2, width=0.3,label='男生',color='green')
autolabel(a)
autolabel(b)
plt.legend()
plt.xticks(x1,list(wk1.index),rotation=45)
plt.show()
#周一至周三消费次数较高,男女生在一周内的消费频率的波动没有明显差异
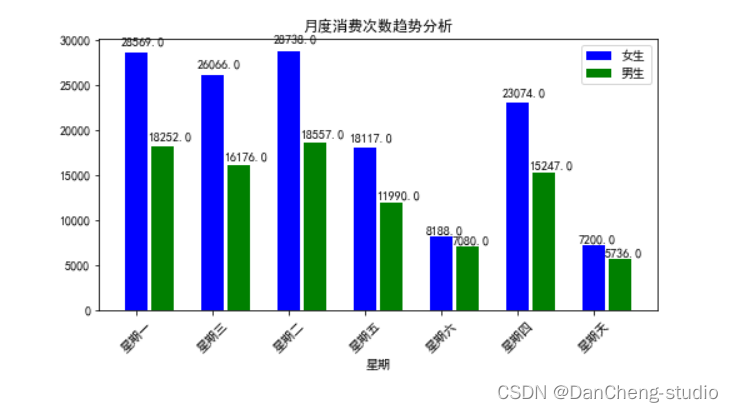
1.从一个月的每天的消费次数上看,除个别天数男女生消费次数相近,多大多数天数的女生的消费次数高于男生,且每周之间趋势相似,可以得出学生日常的消费习惯比较稳定;
2.从每周的消费次数汇总上看,周一至周三消费次数较高,并且逐步下降,周末为消费次数最低的时候。男女生在一周内的消费频率的波动趋势相同,没有明显差异;
3.从每天的消费的时间段分析上看,周末的刷卡消费次数为平常的12%。食堂可以根据数据情况,适当安排休息,减少人力成本浪费;
4.平常时间的早、中、晚餐的用餐时间集中在7点、11点、17-18点时间段。周末消费的时间相对平缓,早餐的高峰时间会延后到8点时间段,且持续有人员消费,中餐的用餐时间也会有部分后延到12点的时间段。晚餐时间则会部分提前17点的时间段进行,需要提前做好食堂的准备事项。
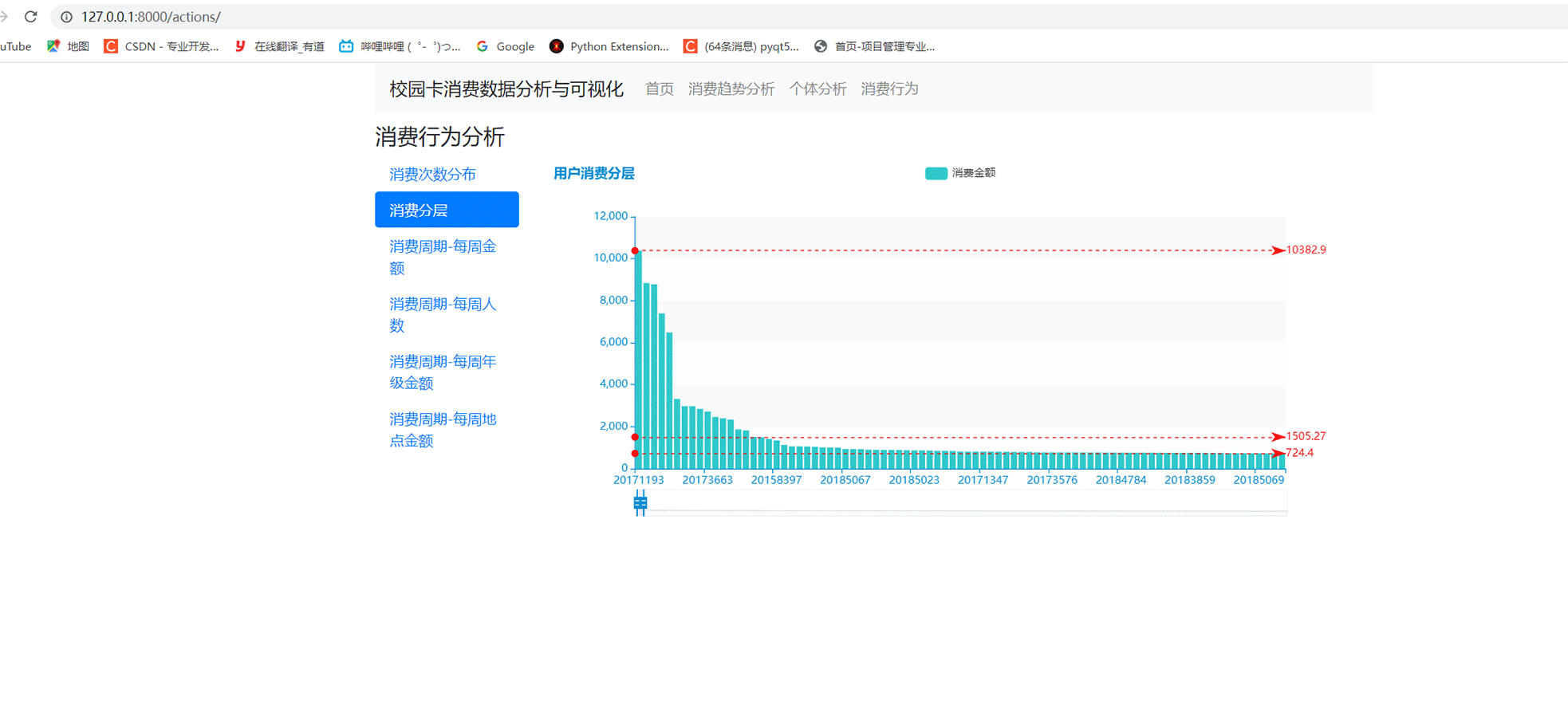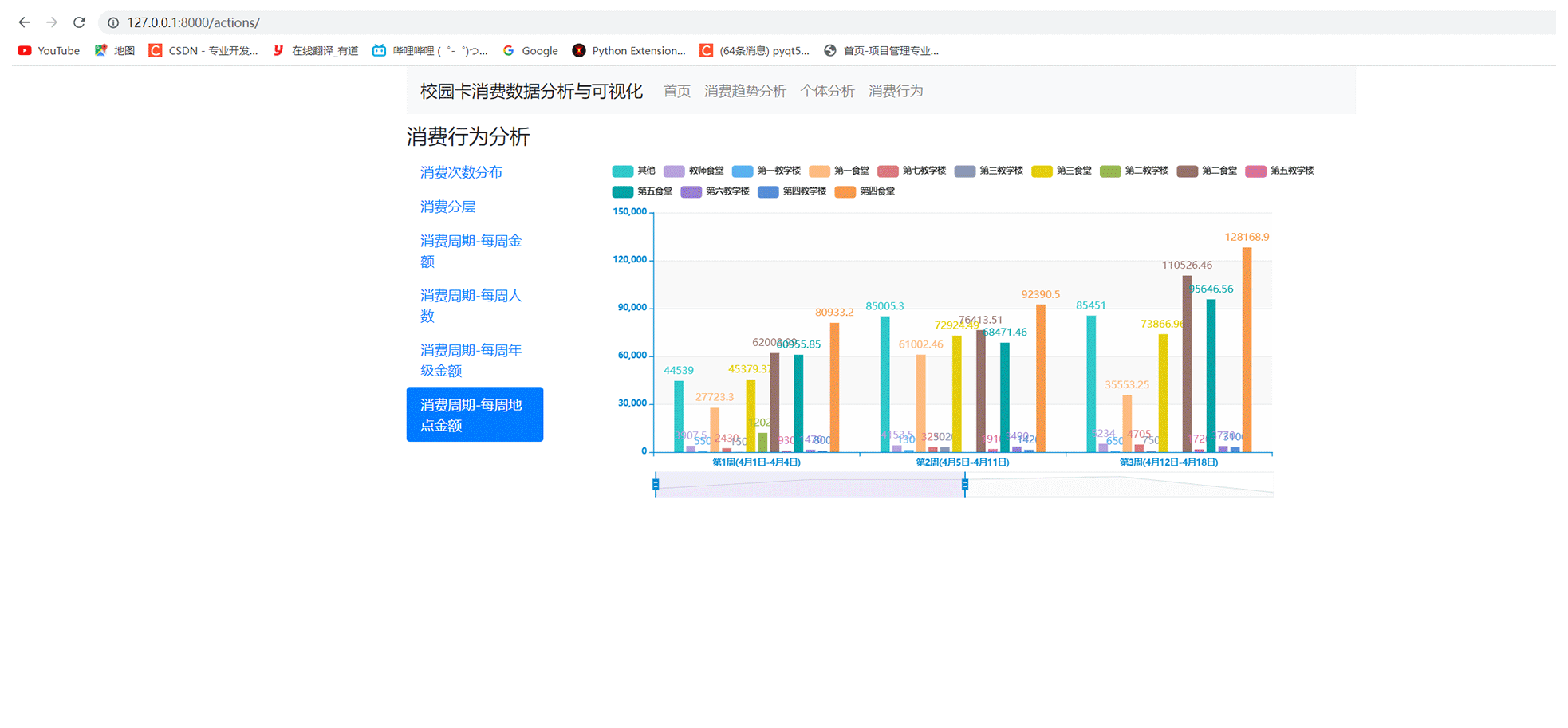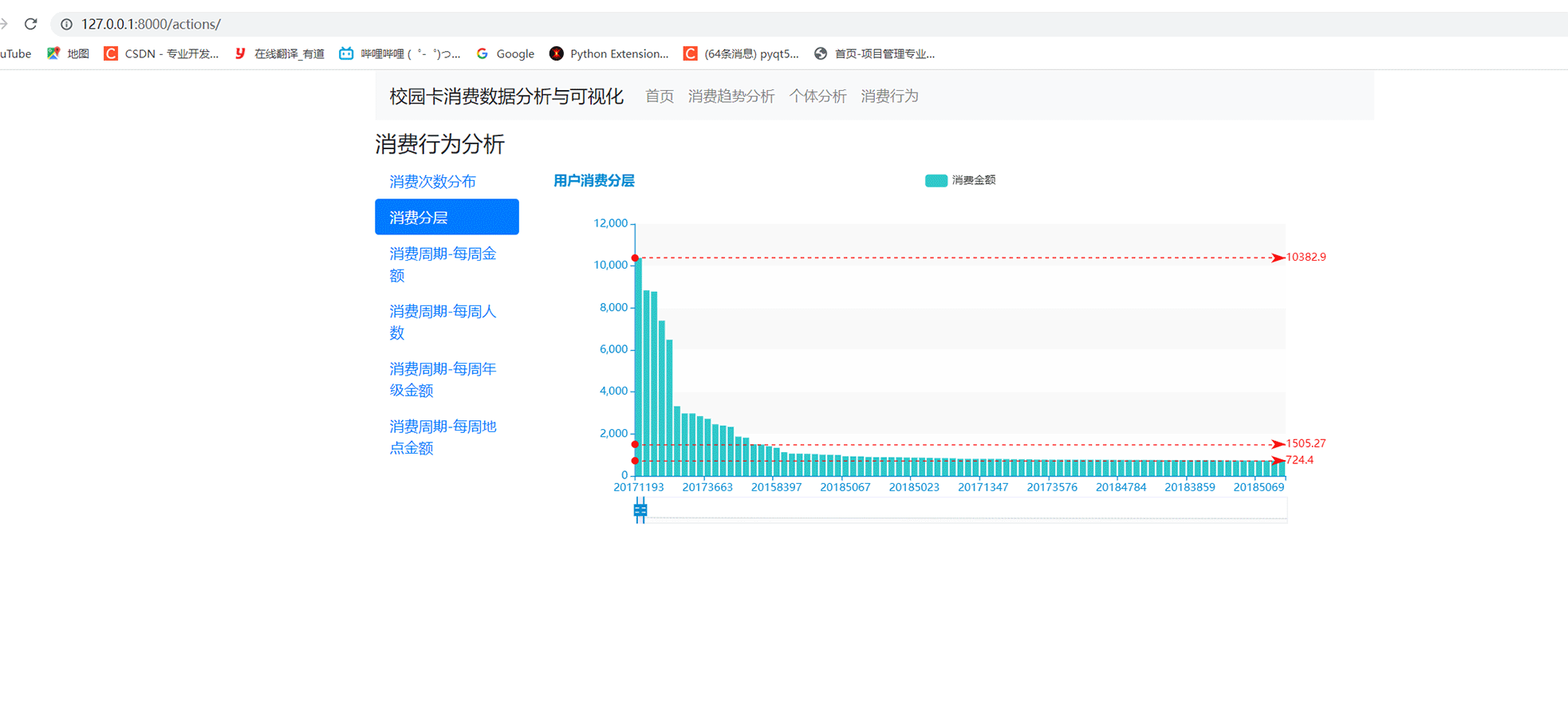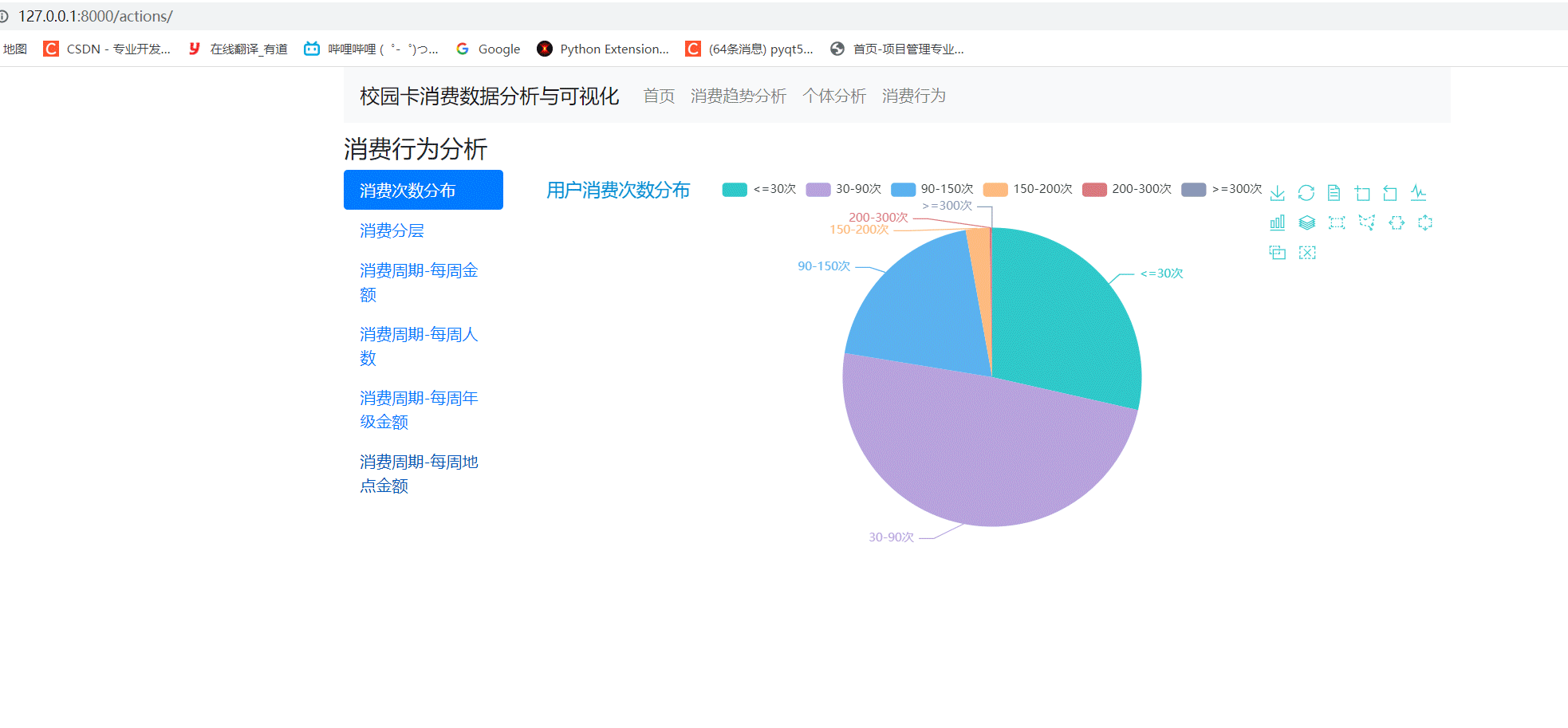
4 Web系统效果展示
以上是校园卡分析的部分过程,我们还可以做成web系统来展示。效果如下:
4.平常时间的早、中、晚餐的用餐时间集中在7点、11点、17-18点时间段。周末消费的时间相对平缓,早餐的高峰时间会延后到8点时间段,且持续有人员消费,中餐的用餐时间也会有部分后延到12点的时间段。晚餐时间则会部分提前17点的时间段进行,需要提前做好食堂的准备事项。
Web系统效果展示
以上是校园卡分析的部分过程,我们还可以做成web系统来展示。效果如下:
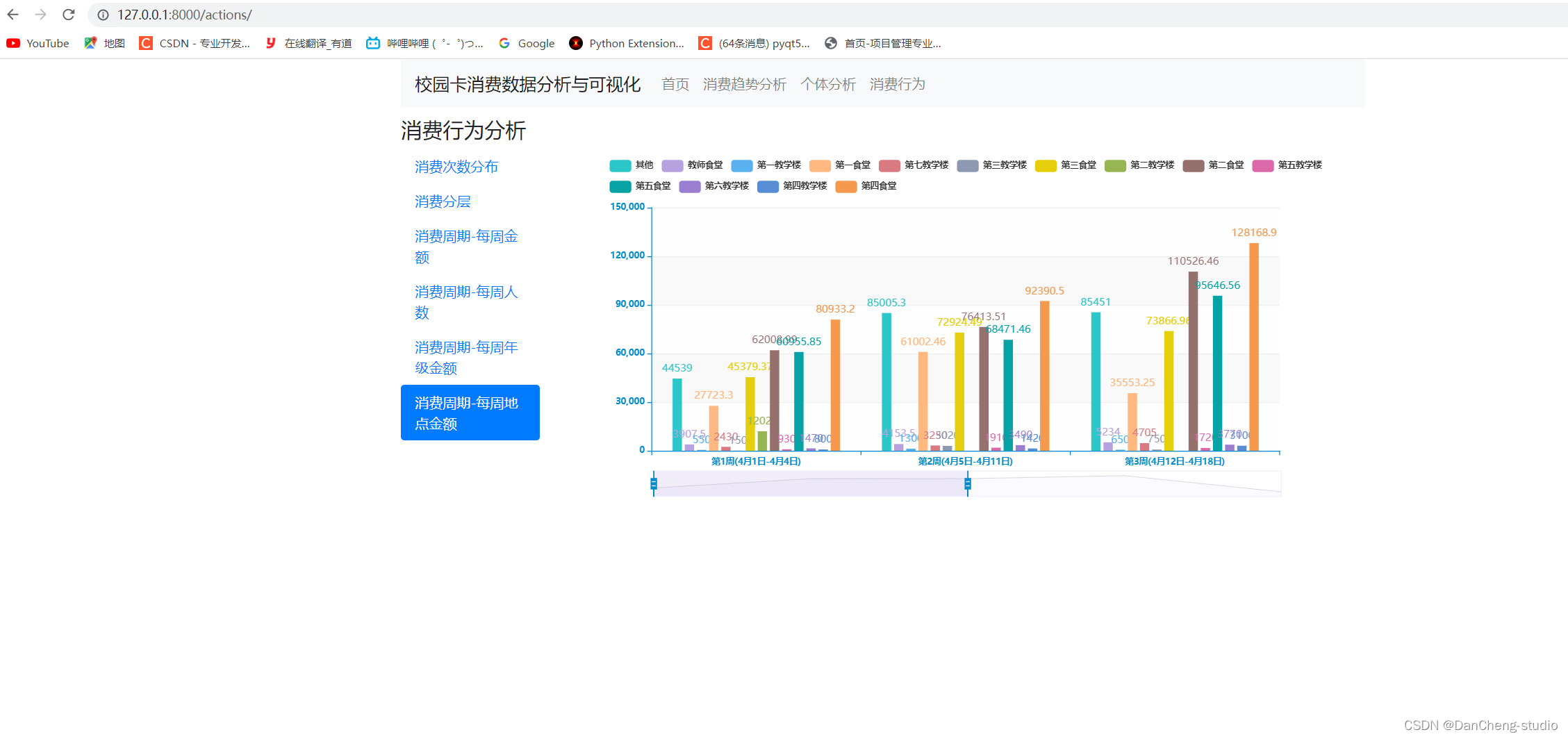
🧿 选题指导, 项目分享:见文末
5 最后
这篇关于毕设 大数据校园卡数据分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





