本文主要是介绍IO模型:同步阻塞、同步非阻塞、同步多路复用、异步非阻塞,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
stream和channel对比
同步、异步、阻塞、非阻塞
线程读取数据的过程
同步阻塞IO
同步非阻塞IO
同步IO多路复用
异步IO
优缺点对比
stream和channel对比
- stream不会自动缓冲数据,channel会利用系统提供的发送缓冲区、接收缓冲区。
- stream仅支持阻塞API,channel同时支持阻塞、非阻塞API,网络channel可配合selector实现多路复用。
- stream和channel均为全双工,读写可以同时进行。
同步、异步、阻塞、非阻塞
- 同步异步强调的是结果的获取是主动还是被动的:
- 同步:线程自己去获取结果。【一个线程】
- 异步:线程自己不去获取结果,而是由其他线程推送结果。【至少两个线程】
- 阻塞非阻塞表示获取这个动作是否可以立即返回而不需要等待:关注的是线程的状态。
- 阻塞:调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会恢复运行。
- 非阻塞:不能立即得到结果之前,该调用不会阻塞当前线程。
举例:
同步就是烧开水,要自己来看开没开;异步就是水开了,然后水壶响了通知你水开了 (回调通知)。阻塞是烧开水的过程中,你不能干其他事情,必须在旁边等着;非阻塞是烧开水的过程里可以干其他事情。
异步阻塞没有实际意义,所以组合后只有同步阻塞、同步非阻塞、异步非阻塞。考虑IO多路复用则有同步多路复用。
线程读取数据的过程
当用户线程发起一次系统调用(如channel.read()、stream.read())后,会由用户态切换至操作系统内核态完成真正数据的读取操作。数据读取又分为两个阶段:
- 等待数据阶段:等待内核将数据由物理设备(磁盘)拷贝至内核缓冲区。
- 复制数据阶段:将数据由内核缓冲区拷贝至用户缓冲区。

同步阻塞IO
阻塞I/O(同步阻塞IO):两个阶段都必须等待。①从硬件设备读取数据到内核空间;②将内核空间中的数据拷贝到用户缓冲区。

同步非阻塞IO
非阻塞I/O(同步非阻塞IO):用户系统调用操作会立即返回结果而不是阻塞用户进程。不断进行轮询查看数据是否已由物理设备拷贝至内核缓冲区,当数据准备就绪后,将数据从内核缓冲区拷贝至用户缓冲区仍然是阻塞的。

非阻塞I/O第一个阶段系统调用请求直接返回,可能误认为和阻塞I/O没有区别,实则非阻塞I/O直接返回后,其他进程也可以执行系统调用。
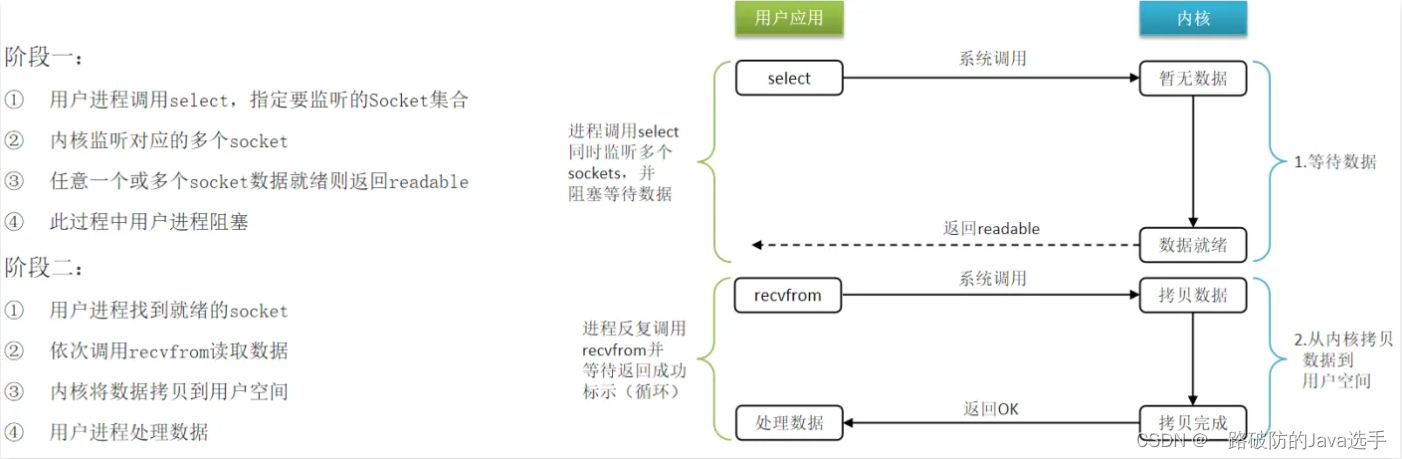
同步IO多路复用
I/O多路复用:利用单个线程来同时监听多个Socket,并在某个Socket可读、可写时得到通知。从而避免无效的等待,充分利用CPU资源。
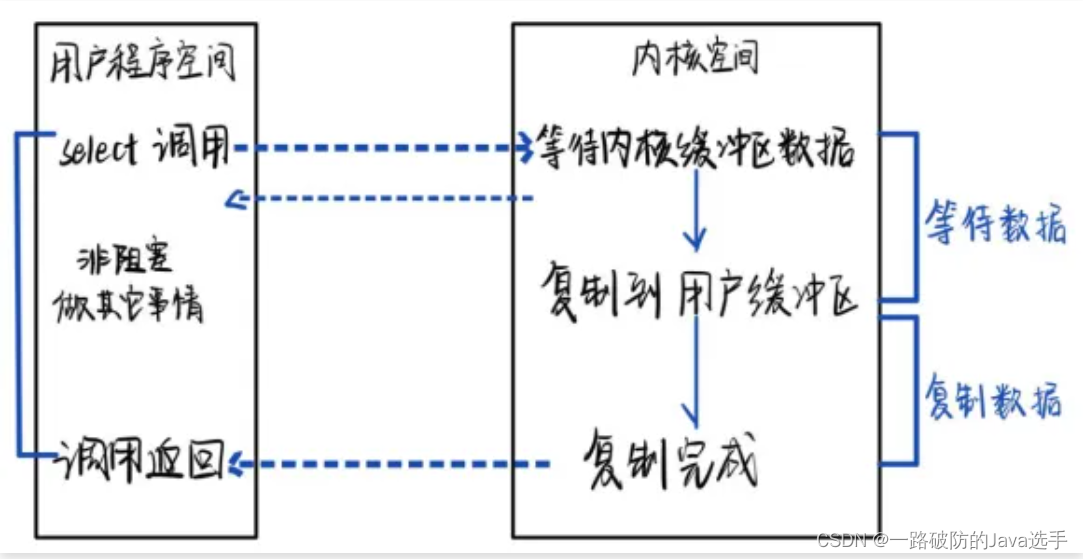
异步IO
异步I/O(Asynchronous IO【AIO】):用户线程通过系统调用,向内核注册某个IO操作,内核在整个IO操作(包括数据准备、数据复制)完成后,通知用户程序,执行后续的业务操作。在异步IO模型中,整个内核的数据处理过程中,包括①将数据从物理设备拷贝到内核缓冲区;②将数据从内核缓冲区拷贝到用户缓冲区,用户线程都不需要阻塞。当内核的IO操作完成后,内核会通知应用程序读取数据。
优缺点对比
- 同步阻塞IO
- 优点:程序开发简单;在阻塞等待数据期间,用户线程挂起,不占用CPU资源。
- 缺点:一个线程维护一个IO流的读写,在高并发应用场景下,需要大量的线程来维护大量的网络连接,内存、线程切换开销会十分巨大,BIO模型在高并发场景下是不可用的。
- 同步非阻塞IO
- 优点:内核缓冲区没有数据的情况下,发起的系统调用不会阻塞,用户程序不会阻塞,实时性较好。
- 缺点:需要不断地重复地发起IO调用,这种不断轮询,不断询问内核的方式,会占用CPU大量的时间,资源利用率比较低;在内核缓冲区有数据的情况下,也是阻塞的。NIO模型在高并发场景下是不可用的。
- IO多路复用
- 优点:select/epoll可以同时处理成百上千的连接,与之前的一个线程维护一个连接相比,IO多路复用则不需要创建线程,也就不需要维护,从而减少系统开销.
- 缺点: select/epoll系统调用,属于阻塞的模式。读写事件就绪之后,用户自己进行读写,这个读写过程也是阻塞的。
- 异步IO
- 优点:在内核等待数据和复制数据的两个阶段,用户线程都不是阻塞的。
- 缺点:需要事件的注册,就需要操作系统。
这篇关于IO模型:同步阻塞、同步非阻塞、同步多路复用、异步非阻塞的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





