dall专题

DALL-E 2(一):介绍和详解|生成模型|文本到图像|人工智能
目录 1. DALL-E 2 的背景与发展历程 2. DALL-E 2 的技术架构 2.1 Transformer 架构的核心原理 2.2 多模态学习的实现 2.3 生成过程的细节 3. DALL-E 2 的应用场景 3.1 创意设计与艺术创作 3.2 教育与科普 3.3 娱乐与游戏开发 3.4 医学图像生成 4. DALL-E 2 的优势与局限 4.1 优势 4.2 局

简单使用富有创造力的DALL·E 3 图像生成器——OpenAI Images Generations API
OpenAI Images Generations API 申请及使用 DALL-E 3 是 OpenAI 开发的两个版本的图像生成模型,它们能够根据文本描述生成高质量的图像。 本文档主要介绍 OpenAI Images Generations API 操作的使用流程,利用它我们可以轻松使用官方 OpenAI DALL-E 的图像生成功能。 申请流程 要使用 OpenAI Images G

Stable Diffusion 与 DALL·E3 的深度解析
一、Stable Diffusion 的全方位解读 Stable Diffusion 是一款令人瞩目的 AI 绘画工具,其显著特点之一便是开源免费。这意味着用户无需支付费用即可自由使用和修改,为广大创作者提供了极大的便利。然而,要想充分发挥其功能,对电脑硬件有一定要求。显卡方面,建议使用 NVIDIA 系列,显存至少 8G 以上,内存也最好在 16G 或更大。 它支持多种功能,如画作

AI生图提示词收集,/MJ/SD/DALL-E/VISION...
#摄影构图与角度Prompt关键词参考来源: https://www.studiobinder.com/blog/ultimate-guide-to-camera-shots/ https://ehowton.livejournal.com/933195.html 距离相关提示词 • extreme close-up(极近景)• close-up(近景)• medium close-up(

最新Prompt预设词分享,DALL-E3文生图+文档分析
使用指南 直接复制使用 可以前往已经添加好Prompt预设的AI系统测试使用(可自定义添加使用) 支持GPTs SparkAi SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型+国内AI全模型。支持GPT-4o大模型、文档分析、识图图片理解、GPTs应用、GPT语音对话、联网提问、GPT-4全模型
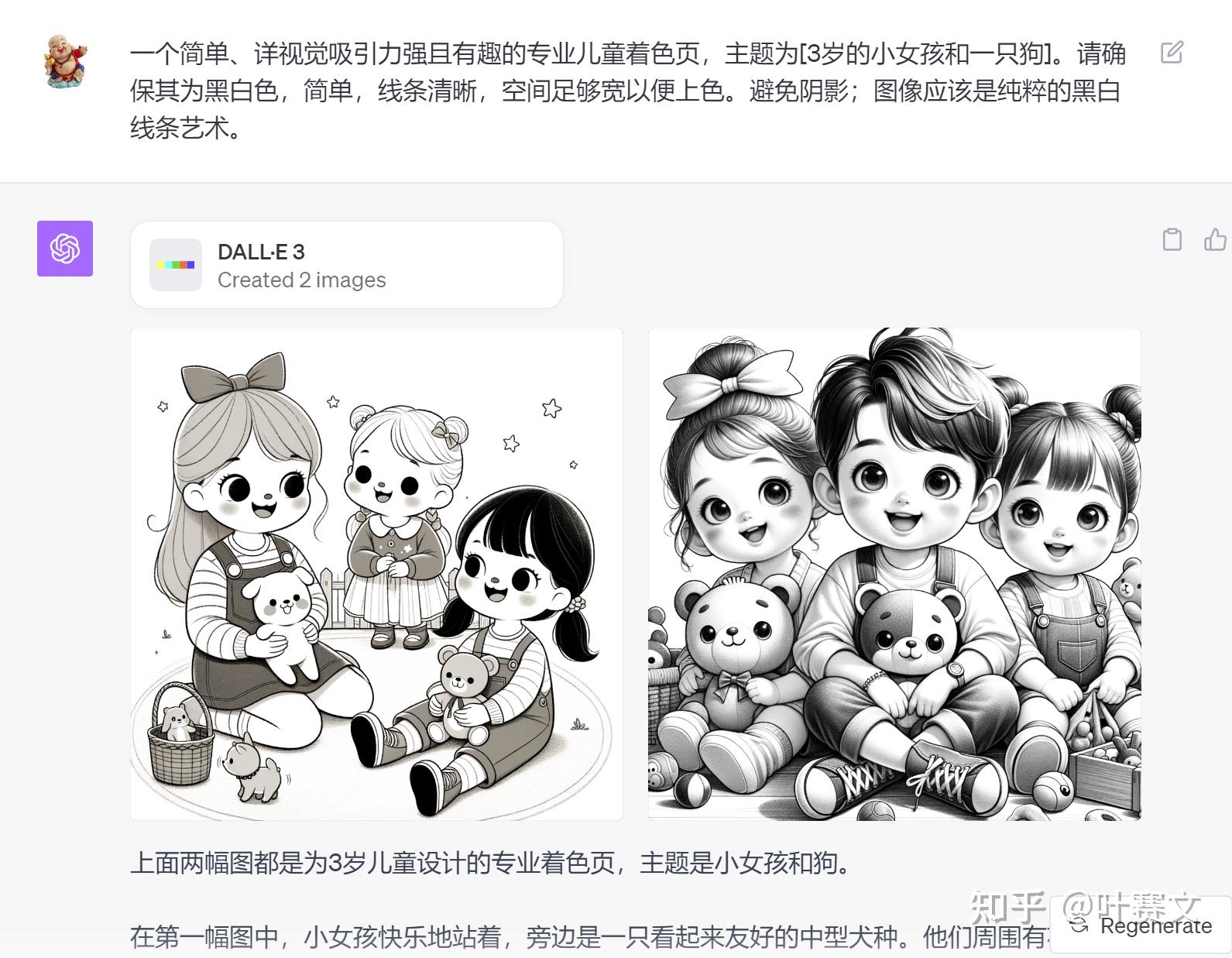
如何用 ChatGPT DALL-E3绘画(10个案例)
如何用ChatGPT绘画——10个案例(附提示词) DALL•E 3可以在ChatGPT plus里直接使用了。 如果想免费使用,可以用新必应免费使用。 上次有个朋友问:DALL•E 3 有什么用。 这里用十个案例,来解释一下这个问题。 1.创建矢量插图 (原文:@itsPaulAi,平台:x) 可以轻松为幻灯片或网站创建矢量插图。 您不再需要在互联网上搜索图像,也不再有水印。 1
什么是 DALL-E?如何使用它?
如何使用 DALL-E 注意:DALL-E 3 型号只能在 ChatGPT Plus 或者 Enterprise 中使用。 如果你升级了 ChatGPT Plus 下面就来看一看 DALL-E 怎么用。因为 OpenAI 已经在 GPT 中原生的构建了 DALL-E 3,所以我们只需要向其输入请求就可以生成具体的图像,在登录账户之后,如果使用的是 GPT-3.5,那么就下拉选择将其修改为 GP

DALL·E2最详细解读篇章
CLIP被证明其可以学习到鲁棒的图像特征,可以有效的捕获图像的语义和风格,且具有很强的zero-shot能力。另外,Diffusion是目前最优的生成式框架,其推动了图像、视频生成任务的最先进性能。Classifier-Free Diffusion指导技术以样本多样性为代价提高了样本保真度,达到了最佳结果。本文通过结合这两种方法设计了一个图像生成模型DALL-E2,以充分利用CLIP的特征。


颠覆想象的AI绘画:DALL-E 2
DALL-E 2是由美国人工智能研究公司OpenAI推出的文本生成图像系统,它是DALL-E的后续版本,具备更强大的功能和更高的图像质量。“DALL-E”这个名字源于西班牙著名艺术家Salvador Dalí和广受欢迎的皮克斯动画机器人“Wall-E”的组合。 发展历史 初代DALL-E:2021年1月,OpenAI发布了初代DALL-E,该工具因其将任何文本描述转化为独特图像的能力

DALL·E 2详解:人工智能如何将您的想象力变为现实!
引言 DALL·E 2是一个基于人工智能的图像生成模型,它通过理解自然语言描述来生成匹配这些描述的图像。这一模型的核心在于其创新的两阶段工作流程,首先是将文本描述转换为图像表示,然后是基于这个表示生成具体的图像。 下面详细介绍DALL-E2的功能和使用方法: 核心组成和技术框架 CLIP模型:DALL·E 2利用CLIP(Contrastive Language-Image Pre-t

OpenAI推出DALL·E 3识别器、媒体管理器
5月8日,OpenAI在官网宣布,将推出面向其文生图模型DALL·E 3 的内容识别器,以及一个媒体管理器。 随着ChatGPT、DALL·E 3等生成式AI产品被大量应用在实际业务中,人们越来越难分辨AI和人类创建内容的区别,这个识别器可以帮助开发人员快速识别内容的真假。 目前,OpenAI已经开放了DALL·E 3识别器的API,开发人员从今天开始至7月31日可申请试用。OpenAI会在8

ChatGPT 4.0 直接用 !!!Code Copilot编程大模型、DALL-E AI绘图、绘制流程图、上传文件
嗨,你好呀,我是哪吒。 这一年最让人揪心的热点,就是各种层出不穷的AI技术。 原以为它只是短暂霸屏,但现实却赤裸裸展示了,什么叫AI抢走你的饭碗,连招呼都不打一声! 什么策划方案、公众号文案、营销卖点、宣传海报,打工人辛辛苦苦掌握到手的技能,却被AI分分钟吊打。 平常要绞尽脑汁的文档报告、复盘总结,合同大纲,AI能帮忙以秒为单位完成。 哪吒AI是一个AI 聚合工具平台,包含ChatG

GPT-3和DALL-E 2在AIGC领域具体有哪些应用?
GPT-3和DALL-E 2 是人工智能领域中两个备受关注的模型,它们分别代表了自然语言处理(NLP)和图像生成领域的最新进展。 1.GPT-3和DALL-E 2的概念与特点 1.1 GPT-3 GPT-3(Generative Pre-trained Transformer 3): GPT-3是由 OpenAI 开发的一个大型语言模型,它使用了深度学习中的预训练技术。GPT-3 采用了
ChatGPT付费创作系统V2.8.4独立版 WEB+H5+小程序端 (新增Pika视频+短信宝+DALL-E-3+Midjourney接口)
小狐狸GPT付费体验系统最新版系统是一款基于ThinkPHP框架开发的AI问答小程序,是基于国外很火的ChatGPT进行开发的Ai智能问答小程序。当前全民热议ChatGPT,流量超级大,引流不要太简单!一键下单即可拥有自己的GPT!无限多开、更新不限时,可以说小狐狸GPT目前国内最好的一款的ChatGPT对接OpenAI 软件系统。 ------------------------------

图像生成模型浅析(Stable Diffusion、DALL-E、Imagen)
目录 前言1. 速览图像生成模型1.1 VAE1.2 Flow-based Model1.3 Diffusion Model1.4 GAN1.5 对比速览 2. Diffusion Model3. Stable Diffusion3.1 Text Encoder3.2 Decoder3.3 Generation Model 总结参考 前言 简单学习下图像生成模型的相关知识🤗

Stable Diffusion 3 API 发布!超越Midjourney v6和DALL-E 3
Stable Diffusion 3 于 2 月首次宣布作为预览版发布。而今天,StabilityAI 正式推出了 Stable Diffusion 3 和 Stable Diffusion 3 Turbo API 的API接口服务。 Stability AI 称仍在持续改进该模型,并没有说明发布日期。模型还没发布,但API先来了! 官方宣传称SD3模型在文字到图像生成领域的表现达到或

手把手教你从零搭建ChatGPT网站AI绘画系统,(SparkAi系统V6)GPTs应用、DALL-E3文生图、AI换脸、垫图混图、SunoAI音乐生成
一、系统前言 SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型+国内AI全模型。本期针对源码系统整体测试下来非常完美,那么如何搭建部署AI创作ChatGPT?小编这里写一个详细图文教程吧。已支持GPTs、GPT语音对话、GPT-4模型、GPT联网提问、DALL-E3文生图、图片对话能力上传图片,GPT4-All联网

点亮创意:ChatGPT如何搭桥DALL-E图像编辑新纪元
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ OpenAI 刚刚宣布,现在您可以在 ChatGPT 中编辑由 DALL

在ChatGPT中,能用DALL·E 3编辑图片啦!
4月3日,OpenAI开始向部分用户,提供在ChatGPT中的DALL·E 3图片编辑功能。 DALL·E 3是OpenAI在2023年9月20日发布的一款文生图模型,其生成的图片效果可以与Midjourney、leonardo、ideogram等顶级产品媲美,随后被融合到ChatGPT中增强其多模态能力。 但有一个很大的问题是,人们无法对AI生成的内容进行精准控制,因为这些都是神经元随机生成

ChatGPT 上线新功能:DALL·E 可以编辑图片了
ChatGPT 上线新功能:DALL·E 可以编辑图片了。可以对生成的图片内容进行修改、添加和删除。 前几天看到消息说还在内测中,今天就体验上了。 这是官方文档:https://help.openai.com/en/articles/9055440-editing-your-images-with-dall-e 界面操作比较简单,选择一张图片,点击右上角的画笔图标,就进入编辑模式了。 左上

今日AI:Sora超现实大片震惊好莱坞;IPadapter插件史诗级更新;苹果要推AI应用商店;DALL-E也推局部重绘功能
📰🤖📢AI新鲜事 OpenAI联手视觉艺术家推大作 首批7个Sora超现实大片震惊好莱坞 【AiBase提要:】 1️⃣ 人人变导演!Sora颠覆传统创意,创造完全超现实内容; 2️⃣ 影片展示气球人的不同视角,传递正能量; 3️⃣ 金色唱片、异种动物、美人鱼等作品展示Sora创意无限,艺术家们与Sora合作开启创作新时代。 视频合集点此查看 :https://qqi2

Midjourney 和 Dall-E 的优劣势比较
Midjourney 和 Dall-E 的优劣势比较 Midjourney 和 Dall-E 都是强大的 AI 绘画工具,可以根据文本描述生成图像。 它们都使用深度学习模型来理解文本并将其转换为图像。 但是,它们在功能、可用性和成本方面存在一些差异。 Midjourney 优势: 可以生成更具艺术性和创造性的图像拥有更活跃的社区,可以提供灵感和支持提供更低的入门价格 劣势: 缺乏对生成
新智元 | Stable Diffusion 3技术报告流出,Sora构架再立大功!生图圈开源暴打Midjourney和DALL·E 3?
本文来源公众号“新智元”,仅用于学术分享,侵权删,干货满满。 原文链接:Stable Diffusion 3技术报告流出,Sora构架再立大功!生图圈开源暴打Midjourney和DALL·E 3? 【新智元导读】Stability AI放出了号称能暴打闭源模型的Stable Diffusion 3的技术报告,采用DiT构架的新模型在灵活性和性能上都达到了新的高度。 Stability AI

【LLM多模态】Cogview3、DALL-E3、CogVLM、LLava模型
note 文章目录 noteVisualGLM-6B模型图生文:CogVLM-17B模型0. 直接部署推理模型Situation 2.1 CLI (SAT version)Situation 2.2 CLI (Huggingface version)Situation 2.3 Web Demo 1. 模型架构2. 模型效果3. 训练数据:CogVLM-SFT-311K数据集信息数据集数量数
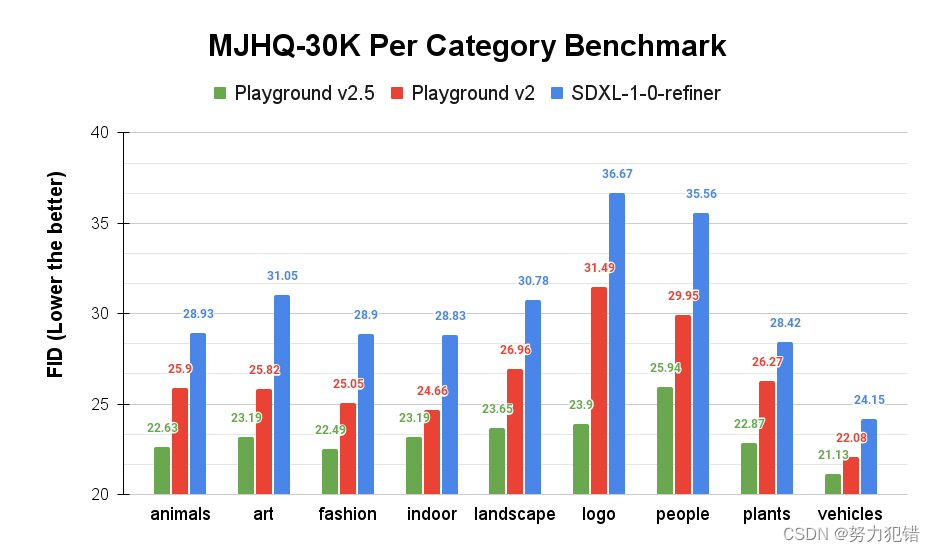
开源文生图大模型Playground v2.5发布:超越SD、DALL·E 3和 Midjourney
前言 在AI技术迅速发展的今天,文生图模型成为了艺术创作、设计创新等领域的重要工具。Playground v2.5的发布,不仅在技术上取得了突破,更在开源文化的推广与实践上迈出了重要一步。 Huggingface模型下载:https://huggingface.co/playgroundai AI快站模型免费加速下载:https://aifasthub.com/models/playgro