chat专题
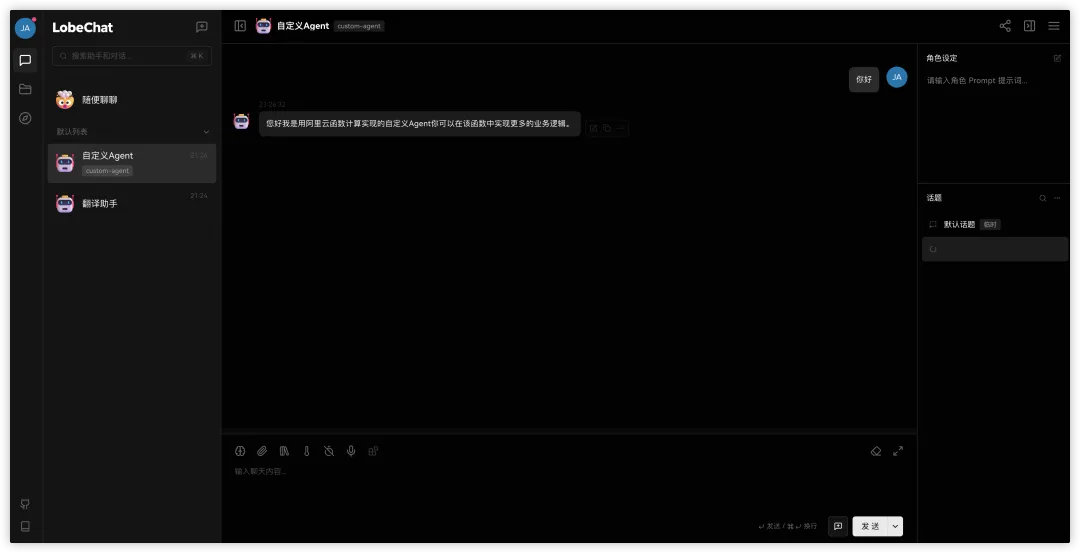
基于阿里云函数计算(FC)x 云原生 API 网关构建生产级别 LLM Chat 应用方案最佳实践
作者:计缘 LLM Chat 应用大家应该都不陌生,这类应用也逐渐称为了我们日常的得力助手,如果只是个人使用,那么目前市面上有很多方案可以快速的构建出一个LLM Chat应用,但是如果要用在企业生产级别的项目中,那对整体部署架构,使用组件的性能,健壮性,扩展性要求还是比较高的。本文带大家了解一下如何使用阿里云Serverless计算产品函数计算构建生产级别的LLM Chat应用。 该最佳实践会

Qwen-7B-Chat大模型安装训练推理-helloworld
初始大模型之helloworld编写 开发环境:modelscope GPU版本上测试的,GPU免费36小时 ps:可以不用conda直接用环境自带的python环境使用 魔搭社区 安装conda wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh 1.2 bash Minicond

RAG 进阶:零成本 chat_with_readthedocs
Readthedocs 是知名的文档托管平台,通常用于免费存放 GitHub 和 GitLab 的项目文档。当项目文档较多时,简单的搜索难以满足读者需求,此外在 AI 2.0 时代,“主动寻找答案”这类用户体验已经逐渐落后。 本文将介绍如何基于 HuixiangDou 在 readthedocs 中做源码检索,同时不需要自备 GPU 服务器和域名。 HuixiangDou ——开源的适合群聊

How can I change from OpenAI to ChatOpenAI in langchain and Flask?
题意:“在 LangChain 和 Flask 中,如何将 OpenAI 更改为 ChatOpenAI?” 问题背景: This is an implementation based on langchain and flask and refers to an implementation to be able to stream responses from the OpenAI

自然语言处理-应用场景-聊天机器人(二):Seq2Seq【CHAT/闲聊机器人】--> BeamSearch算法预测【替代 “维特比算法” 预测、替代 “贪心算法” 预测】
在项目准备阶段我们知道,用户说了一句话后,会判断其意图,如果是想进行闲聊,那么就会调用闲聊模型返回结果。 目前市面上的常见闲聊机器人有微软小冰这种类型的模型,很久之前还有小黄鸡这种体验更差的模型 常见的闲聊模型都是一种seq2seq的结构。 一、准备训练数据 单轮次的聊天数据非常不好获取,所以这里我们从github上使用一些开放的数据集来训练我们的闲聊模型 数据地址:https://gi

通义千问-VL-Chat-Int4
Qwen-VL 是阿里云研发的大规模视觉语言模型(Large Vision Language Model, LVLM)。Qwen-VL 可以以图像、文本、检测框作为输入,并以文本和检测框作为输出。Qwen-VL 系列模型性能强大,具备多语言对话、多图交错对话等能力,并支持中文开放域定位和细粒度图像识别与理解。 安装要求 (Requirements) python 3.8及以上版本pytor

Winform 中Chat控件绘图区闪烁问题
Winform 中使用Chat控件绘制实时曲线时,绘图区闪烁问题解决办法 使用Chat控件,根据接收到的串口数据实时绘制数据曲线,但是在绘制曲线时,绘图区闪烁严重,网上找了很多方法,都不起作用,双缓存也不起作用,最后使用 protected override void WndProc(ref Message m){if (m.Msg == 0x0014) // 禁掉清除背景消息return;

我问Chat GPT:怎么提交app到苹果商店审核
ChatGPT 说: ChatGPT 将应用提交到苹果应用商店 (App Store) 进行审核是一个多步骤的过程,以下是详细步骤: 1. 准备工作 在提交应用之前,请确保完成以下准备工作: 创建 App Store 连接账号: 确保您已经注册为 Apple Developer 并且有一个 App Store Connect 账号。 配置 Xcode 项目: 在 Xcode 中

字节跳动测试岗面试挂在二面,我决定用【Chat GPT】在战一次
先说下我基本情况,本科不是计算机专业,现在是学通信,然后做图像处理,可能面试官看我不是科班出身没有问太多计算机相关的问题,因为第一次找工作,字节的游戏专场又是最早开始的,就投递了,投递的是游戏测试开发岗,字节是自己投的第一家公司,也是第一家笔试 面试的公司。 一般提到面试,肯定都会想问一下面试结果,我就大概的说一下面试结果,哈哈,其实不太想说,因为挺惨的,并没有像很多大佬一样 ”已拿字节阿里腾讯
ChatOpenAI和OpenAI辨析
这篇文章主要讲LangChain中ChatOpenAI和OpenAI的不同,代码完全是在B站 LangChain入门 - ChatOpenAI与OpenAI究竟有何不同?看到的,代码在GitHub上也有Difference between ChatOpenAI and OpenAI 其他相关链接: LangChain Quickstart LangChain OpenAI functions

基于huggingface peft进行qwen1.5-7b-chat训练/推理/服务发布
一、huggingface peft微调框架 1、定义 PEFT 是一个为大型预训练模型提供多种高效微调方法的Python库。 微调传统范式是针对每个下游任务微调模型参数。大模型参数总量庞大,这种方式变得极其昂贵和不切实际。PEFT采用的高效做法是训练少量提示参数(Prompt Tuning)或使用低秩适应(LORA)等重新参数化方法来减少微调时训练参数的数量。 二、qwen-1.5b-c
【深度学习】LLaMA-Factory 大模型微调工具, 微调GLM-4-9B-Chat-1M ,Docker (4)
文章目录 回顾制作镜像数据准备WebUI训练推理导出模型部署 回顾 之前LLaMA-Factory 还未正式支持GLM-4-9B,做了魔改后进行微调了: https://qq742971636.blog.csdn.net/article/details/140620014 如今LLaMA-Factory 已正式支持GLM-4-9B,本篇文章会以Docker方式进行GLM-4-9

InternLM2.5-20B-Chat 正式上线 SiliconCloud 平台
经推理加速的 InternLM2.5-20B-Chat 已正式上线 SiliconCloud 平台。开发者们无需自行开发和部署,直接通过平台就可以轻松调用 API 服务实际应用。 API 调用代码: from openai import OpenAIclient = OpenAI(api_key="YOUR_API_KEY", base_url="https://api.siliconfl
[Winform] Chat控件闪烁
使用Chat控件,根据接收到的串口数据实时绘制数据曲线,但是在绘制曲线时,绘图区闪烁严重,网上找了很多方法,都不起作用,双缓存也不起作用,最后使用 protected override void WndProc(ref Message m){if (m.Msg == 0x0014) // 禁掉清除背景消息return;base.WndProc(ref m);} 成功。 使用该方法时也
Chat App 项目之解析(八)
Chat App 项目介绍与解析(一)-CSDN博客文章浏览阅读340次,点赞7次,收藏3次。Chat App 是一个实时聊天应用程序,旨在为用户提供一个简单、直观的聊天平台。该应用程序不仅支持普通用户的注册和登录,还提供了管理员登录功能,以便管理员可以查看和管理聊天记录。本文将详细介绍index.html文件的实现细节,包括代码解释、实现效果、实现方法以及后续需要实现的功能。https://bl
Chat App 项目之解析(三)
Chat App 项目介绍与解析(一)-CSDN博客文章浏览阅读76次。Chat App 是一个实时聊天应用程序,旨在为用户提供一个简单、直观的聊天平台。该应用程序不仅支持普通用户的注册和登录,还提供了管理员登录功能,以便管理员可以查看和管理聊天记录。本文将详细介绍index.html文件的实现细节,包括代码解释、实现效果、实现方法以及后续需要实现的功能。https://blog.csdn.net
AI 大模型企业应用实战(10)-LLMs和Chat Models
1 模型 来看两种不同类型的模型--LLM 和聊天模型。然后,它将介绍如何使用提示模板来格式化这些模型的输入,以及如何使用输出解析器来处理输出。 LangChain 中的语言模型有两种类型: 1.1 Chat Models 聊天模型通常由 LLM 支持,但专门针对会话进行了调整。提供者 API 使用与纯文本补全模型不同的接口。它们的输入不是单个字符串,而是聊天信息列表,输出则是一条人工智能
最新版ChatGPT对话系统源码 Chat Nio系统源码
最新版ChatGPT对话系统源码 Chat Nio系统源码 支持 Vision 模型, 同时支持 直接上传图片 和 输入图片直链或 Base64 图片 功能 (如 GPT-4 Vision Preview, Gemini Pro Vision 等模型) 支持 DALL-E 模型绘图 支持 Midjourney / Niji 模型的 Imagine / Upscale / Variant /
GLM4-9B-Chat模型LoRA微调
文本记录GLM4-9B-Chat模型进行LoRA微调的过程。 一、环境: 操作系统: Ubuntu 22.04CUDA: 12.1GPU: 3090 x 2 创建conda环境: conda create -n glm4 python=3.10.14conda activate glm4cd /home/data/chatglm4-finetune 二、数
![[大模型]XVERSE-7B-chat WebDemo 部署](https://img-blog.csdnimg.cn/direct/6217e32fe0a64f2c9a95361ec720c3c3.png#pic_center)
[大模型]XVERSE-7B-chat WebDemo 部署
XVERSE-7B-Chat为XVERSE-7B模型对齐后的版本。 XVERSE-7B 是由深圳元象科技自主研发的支持多语言的大语言模型(Large Language Model),参数规模为 70 亿,主要特点如下: 模型结构:XVERSE-7B 使用主流 Decoder-only 的标准 Transformer 网络结构,支持 8K 的上下文长度(Context Length),能满足更长
Llama3-8B-Chinese-Chat 聊天机器人
Llama3-8B-Chinese-Chat 聊天机器人 1. 创建虚拟环境2. 安装 pytorch3. 安装 transformers 和 gradio4. 开发 ui 代码5. 运行 ui 代码6. 访问 web ui 1. 创建虚拟环境 conda create -n llama3-chinese python=3.11 -yconda activate llama3-

chat_bubbles包的用法
文章目录 1. 概念介绍2. 思路与方法2.1 组件及属性2.2 实现方法2.3 功能扩展 3. 示例代码4. 内容总结 我们在上一章回中介绍了"buble包"相关的内容,本章回中将介绍chat_bubbles包.闲话休提,让我们一起Talk Flutter吧。 1. 概念介绍 我们在本章回中介绍的chat_bubbles包是一个三方插件,它用来实现类似聊天窗口的功能,常
![[大模型]MiniCPM-2B-chat Lora Full 微调](https://img-blog.csdnimg.cn/direct/1b9775b35ecf41d0b84e94ae4974da3d.png#pic_center)
[大模型]MiniCPM-2B-chat Lora Full 微调
MiniCPM-2B-chat 介绍 MiniCPM 是面壁智能与清华大学自然语言处理实验室共同开源的系列端侧大模型,主体语言模型 MiniCPM-2B 仅有 24亿(2.4B)的非词嵌入参数量。 经过 SFT 后,MiniCPM 在公开综合性评测集上,MiniCPM 与 Mistral-7B相近(中文、数学、代码能力更优),整体性能超越 Llama2-13B、MPT-30B、Falcon-4
DeepSeek-V2-Chat多卡推理(不考虑性能)
@TOC 本文演示了如何使用accelerate推理DeepSeek-V2-Chat(裁剪以后的模型,仅演示如何将权值拆到多卡) 代码 import torchfrom transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfigfrom accelerate import init_empty_wei
GLM4-Chat-1M(号称可以输入200万字)的长文本测试结果(推理时间,推理效果)
GLM4-Chat-1M(号称可以输入200万字)的长文本测试结果(推理时间,推理效果) 测试方法 使用如下prompt,让模型提取小说(测试数据)中出现的人物名,数字表示用到的内容章节数目: test_f=['3-这游戏也太真实了.txt','6-这游戏也太真实了.txt','9-这游戏也太真实了.txt','20-这游戏也太真实了.txt','50-这游戏也太真实了.txt','10

基于SWIFT和Qwen1.5-14B-Chat进行大模型LoRA微调测试
基于SWIFT和Qwen1.5-14B-Chat进行大模型LoRA微调测试 环境准备 基础环境 操作系统:Ubuntu 18.04.5 LTS (GNU/Linux 3.10.0-1127.el7.x86_64 x86_64)Anaconda3:Anaconda3-2023.03-1-Linux-x86_64根据服务器网络情况配置好conda源和pip源,此处使用的是超算山河源服务器硬件配置