本文主要是介绍【阿里前端面试题】客户端和服务器交互的过程中,丢包是怎么产生的?超详细,建议关注收藏,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我是“寻找DX3906”。每天进步一点。日积月累,有朝一日定会厚积薄发!
前言
前面已经和大家分享了2篇面试题:
《【阿里前端面试题】浏览器的加载渲染过程》
《【阿里前端面试题】客户端和服务器交互,为什么选用tcp协议建立链接?》
都是围客户端渲染以及和服务器交互 进行分享的。那在客户端和服务器交互的过程中,丢包是怎么产生的呢?
什么是“数据包”
TCP(传输控制协议)数据包,通常被称为TCP段(segments),是TCP协议中用于传输数据的基本单位。每个TCP段都包含了一些控制信息和数据本身,用于确保数据的可靠传输。以下是TCP数据包的一些基本概念:
-
段头(Header):每个TCP段的开始部分是段头,它包含了用于控制数据传输和保证数据完整性的重要信息,如源端口号、目的端口号、序列号、确认号、控制标志位等。
-
序列号(Sequence Number):用于标识从发送方发送的数据字节的顺序。TCP使用序列号来确保数据的有序传输,并且能够检测丢包和重复包。
-
确认号(Acknowledgment Number):是接收方发送回发送方的,用于确认已经成功接收到的数据的序列号。
-
控制标志位(Control Flags):
- SYN(Synchronize Sequence Numbers):用于建立连接时同步序列号。
- ACK(Acknowledgment):表示确认收到了对方发送的数据。
- FIN(End of Data):用于释放连接,表示没有更多的数据要发送了。
- RST(Reset the Connection):用于强制释放一个不正常的或不需要的连接。
-
窗口大小(Window Size):用于流量控制,指示接收方可以接收的字节数量,从而控制发送方的发送速率。
-
校验和(Checksum):用于错误检测,确保TCP段在传输过程中没有被篡改或损坏。
-
紧急指针(Urgent Pointer):指示段中紧急数据的结束位置。
-
选项(Options):可以包含多种扩展功能,如最大报文段大小(MSS)等。
-
数据(Data):实际要传输的数据负载,紧跟在段头之后。
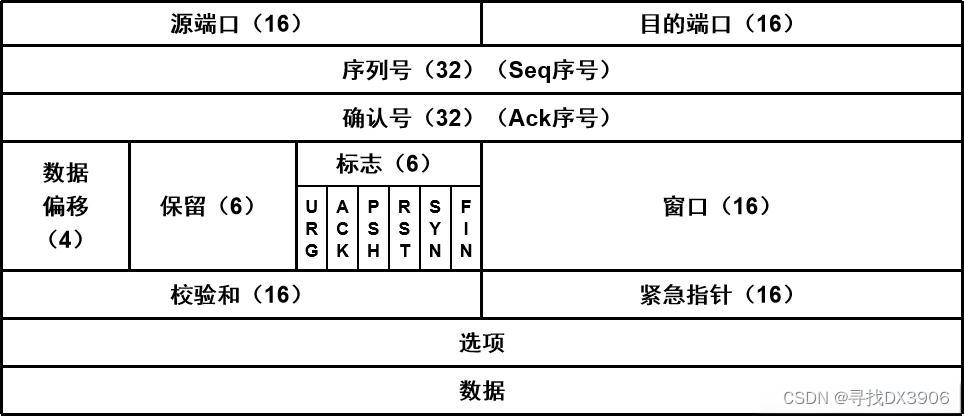
TCP段数据包的设计允许它在不可靠的网络介质上提供可靠的、有序的和错误检测的数据传输服务。通过使用序列号、确认号、校验和以及重传机制,TCP能够确保数据的完整性和顺序性,即使在网络条件不佳或出现丢包的情况下。此外,TCP的流量控制和拥塞控制机制使用窗口大小和拥塞窗口来调节数据的发送速率,以适应网络的当前状态。
什么是“丢包”
"丢包"在计算机网络中是指在数据传输过程中,数据包(packet)没有成功地从发送端传输到接收端,而是在途中丢失了。简单来说,就是数据包在网络中"不见了"。
造成“丢包的原因”
TCP(传输控制协议)通常被设计为可靠的协议,它负责确保数据的可靠传输,但仍然有一些情况下可能导致数据包丢失的情况。
-
网络拥塞:网络中的数据流量超过了网络设备或链路的处理能力,导致部分数据包无法被处理和转发。
-
错误:数据在传输过程中可能会受到干扰或损坏,导致接收端无法正确识别或处理数据包。
-
资源限制:网络设备(如路由器、交换机)的缓冲区(内存)有限,当缓冲区满时,新到达的数据包可能会被丢弃。
-
路由问题:数据包在网络中传输时需要经过多个中间节点。如果路由信息不正确或存在问题,数据包可能会被错误地转发或无法到达目的地。
-
超时:每个数据包都有一定的生存时间(TTL,Time to Live),超过这个时间仍未到达目的地的数据包会被丢弃。
-
安全策略:网络安全设备(如防火墙)可能会根据安全策略丢弃某些类型的数据包,以防止潜在的威胁。
-
软件缺陷:操作系统、网络协议栈或网络应用中的软件错误也可能导致数据包处理不当而被丢弃。
-
网络攻击:恶意的网络攻击,如分布式拒绝服务攻击(DDoS),可以导致大量的数据包被故意丢弃,从而影响网络服务的可用性。
丢包会影响网络通信的质量和效率,特别是在需要可靠传输的应用中,如文件传输、视频会议等。为了减少丢包的影响,网络协议(如TCP)通常会实现一些机制,比如超时重传、流量控制和拥塞控制,以确保数据能够尽可能可靠地传输。
简而言之,"丢包"就是指在网络传输过程中,数据包没有成功到达目的地,而是在途中丢失了。这是网络通信中常见的问题,可能会影响通信的质量和效率。
结语
🔥如果此文对你有帮助的话,欢迎💗关注、👍点赞、⭐收藏、✍️评论,支持一下博主~
这篇关于【阿里前端面试题】客户端和服务器交互的过程中,丢包是怎么产生的?超详细,建议关注收藏的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






