本文主要是介绍H800基础能力测试,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
H800基础能力测试
- 参考链接
- A100、A800、H100、H800差异
- H100详细规格
- H100 TensorCore FP16 理论算力计算公式
- 锁频
- 安装依赖
- pytorch FP16算力测试
- cublas FP16算力测试
- 运行cuda-samples
本文记录了H800基础测试步骤及测试结果
参考链接
- NVIDIA H100 Tensor Core GPU Architecture
- How to calculate the Tensor Core FP16 performance of H100?
- NVIDIA H100 PCIe 80 GB
- NVIDIA H800 Tensor Core GPU
A100、A800、H100、H800差异
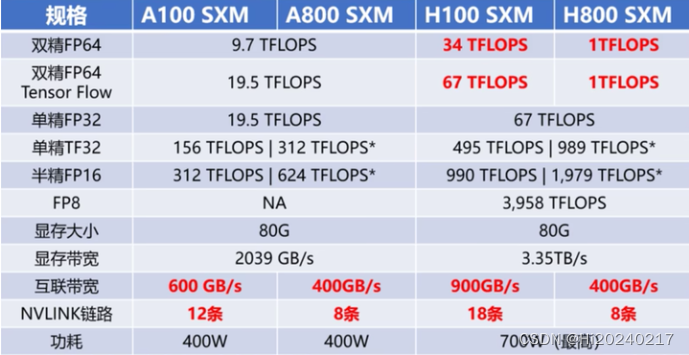
H100详细规格
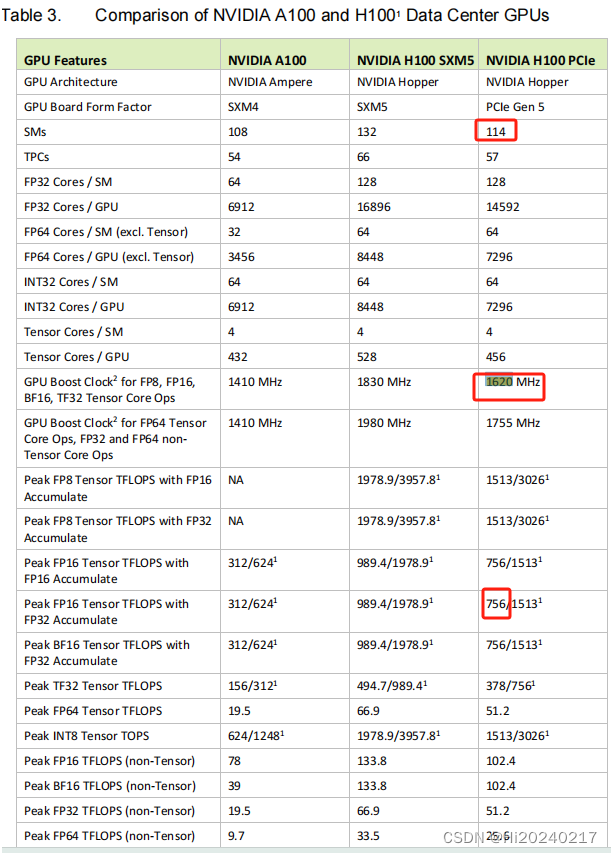
H100 TensorCore FP16 理论算力计算公式
- 4096 FLOP/clk per SM.
- The H100 PCIE has 114 SMs
- 114 x 4096 = 466944 FLOP/clk
- BoostClock:1620MHz
- 114 x 4096 x1620M/1000/1000=756 TFLOPS
- 当前的卡最大频率为1980–> 114 x 4096 x1980M/1000/1000=924 TFLOPS
锁频
nvidia-smi -q -d SUPPORTED_CLOCKS
nvidia-smi -lgc 1980,1980
nvidia-smi --lock-memory-clocks-deferred=2619
安装依赖
pip3 install https://github.com/cupy/cupy/releases/download/v13.1.0/cupy_cuda12x-13.1.0-cp310-cp310-manylinux2014_x86_64.whl
pip3 install pycuda
pytorch FP16算力测试
tee torch_flops.py <<-'EOF'
import pycuda.autoinit
import pycuda.driver as cuda
import torch
import timedef benchmark_pytorch_fp16(M,N,K, num_runs):# 确保使用 GPU 并设置数据类型为半精度浮点数 (float16)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')dtype = torch.float16# 生成随机矩阵A = torch.randn((M, K), device=device, dtype=dtype)B = torch.randn((K, N), device=device, dtype=dtype) # 预热 GPU,进行一次矩阵乘法C = torch.matmul(A, B) # 记录开始时间start_time = time.time() # 多次进行矩阵乘法,计算 FLOPSstart = cuda.Event()end = cuda.Event()start.record() for _ in range(num_runs):C = torch.mm(A, B) end.record()torch.cuda.synchronize() elapsed_time = start.time_till(end) / num_runs # 计算 GFLOPSnum_operations = 2 * M*N*Kgflops = num_operations / (elapsed_time * 1e-3) / 1e12 return elapsed_time, gflops# 记录结束时间end_time = time.time() # 计算平均运行时间elapsed_time = (end_time - start_time) / num_runs # 计算总的 FLOPstotal_flops = 2 * M*K*N # 计算 GFLOPSgflops = total_flops / elapsed_time / 1e12 return elapsed_time, gflops
# 设置矩阵大小和运行次数
num_runs = 32
M=2048
N=2048
K=40960
for i in range(5):# 运行基准测试elapsed_time, gflops = benchmark_pytorch_fp16(M,N,K, num_runs)# 输出结果print(f"Num:{i} 矩阵乘法大小: {M}x{K}X{N} 平均运行时间: {elapsed_time:.6f} 秒 TFLOPS: {gflops:.2f}")time.sleep(0.1)
EOF
python3 torch_flops.py
输出(790/924=85%)
Num:0 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.441580 秒 TFLOPS: 778.11
Num:1 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.430380 秒 TFLOPS: 798.36
Num:2 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.430523 秒 TFLOPS: 798.09
Num:3 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.430742 秒 TFLOPS: 797.69
Num:4 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.430283 秒 TFLOPS: 798.54
cublas FP16算力测试
tee cublas_flops.py <<-'EOF'
import cupy as cp
import numpy as np
from cupy._core import _dtype
from cupy.cuda import cublas
from time import time
from ctypes import c_void_p, c_float, cast, pointer, byref
import pycuda.autoinit
import pycuda.driver as cudadef cublas_fp16_strided_batched_gemm(M,N,K, batch_size, num_runs):# 创建随机半精度矩阵并转换为 CuPy 数组cp.cuda.Device(0).use()A = cp.random.randn(batch_size, M, K).astype(cp.float16)B = cp.random.randn(batch_size, K, N).astype(cp.float16)C = cp.empty((batch_size, M, N), dtype=cp.float16)# 创建 cuBLAS 句柄handle = cublas.create() # 标量 alpha 和 betaalpha = np.array(1, dtype=np.float16)beta = np.array(0, dtype=np.float16) cublas.setMathMode(handle, cublas.CUBLAS_TENSOR_OP_MATH)algo = cublas.CUBLAS_GEMM_DEFAULT_TENSOR_OP try:# Warm-up (预热)for j in range(1):cublas.gemmStridedBatchedEx(handle,cublas.CUBLAS_OP_N, cublas.CUBLAS_OP_N,M, N, K,alpha.ctypes.data, A.data.ptr,_dtype.to_cuda_dtype(A.dtype,True), M, M * K,B.data.ptr, _dtype.to_cuda_dtype(B.dtype,True), K, K * N,beta.ctypes.data, C.data.ptr, _dtype.to_cuda_dtype(C.dtype,True), M, M * N,batch_size,_dtype.to_cuda_dtype(C.dtype,True), algo)cp.cuda.Device(0).synchronize() # 实际基准测试start = cuda.Event()end = cuda.Event()start.record()start_time = time()for _ in range(num_runs):cublas.gemmStridedBatchedEx(handle,cublas.CUBLAS_OP_N, cublas.CUBLAS_OP_N,M, N, K,alpha.ctypes.data, A.data.ptr,_dtype.to_cuda_dtype(A.dtype,True), M, M * K,B.data.ptr, _dtype.to_cuda_dtype(B.dtype,True), K, K * N,beta.ctypes.data, C.data.ptr, _dtype.to_cuda_dtype(C.dtype,True), M, M * N,batch_size,_dtype.to_cuda_dtype(C.dtype,True), algo)end.record()cp.cuda.Device(0).synchronize()end_time = time() except cp.cuda.runtime.CUDARuntimeError as e:print(f"CUDA 运行时错误: {e}")cublas.destroy(handle)return None, None elapsed_time = start.time_till(end) / num_runs # 计算 GFLOPSnum_operations = 2 * M*N*K*batch_sizegflops = num_operations / (elapsed_time * 1e-3) / 1e12 return elapsed_time, gflops elapsed_time = (end_time - start_time) / num_runsnum_ops = 2*M*K*N*batch_sizegflops = num_ops / elapsed_time / 1e12 cublas.destroy(handle) return elapsed_time, gflops
num_runs = 32
M=2048
N=2048
K=40960
matrix_size = 1
for i in range(5):elapsed_time, gflops = cublas_fp16_strided_batched_gemm(M,N,K,matrix_size,num_runs)print(f"Num:{i} 矩阵乘法大小: {M}x{K}X{N} 平均运行时间: {elapsed_time:.6f} 秒 TFLOPS: {gflops:.2f}")
EOF
python3 cublas_flops.py
输出(817/924=88%)
Num:0 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.421070 秒 TFLOPS: 816.01
Num:1 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.420407 秒 TFLOPS: 817.30
Num:2 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.420305 秒 TFLOPS: 817.50
Num:3 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.420304 秒 TFLOPS: 817.50
Num:4 矩阵乘法大小: 2048x40960X2048 平均运行时间: 0.420554 秒 TFLOPS: 817.01
运行cuda-samples
git clone https://www.github.com/nvidia/cuda-samples
cd cuda-samples/Samples/1_Utilities/deviceQuery
make clean && make
./deviceQuery
cd ../bandwidthTest/
make clean && make
./bandwidthTest
cd ../../4_CUDA_Libraries/batchCUBLAS/
make clean && make
./batchCUBLAS -m8192 -n8192 -k8192 --device=0
输出
Device 0: "NVIDIA H800"CUDA Driver Version / Runtime Version 12.2 / 12.2CUDA Capability Major/Minor version number: 9.0Total amount of global memory: 81008 MBytes (84942979072 bytes)(132) Multiprocessors, (128) CUDA Cores/MP: 16896 CUDA CoresGPU Max Clock rate: 1980 MHz (1.98 GHz)Memory Clock rate: 2619 MhzMemory Bus Width: 5120-bitL2 Cache Size: 52428800 bytesMaximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layersMaximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layersTotal amount of constant memory: 65536 bytesTotal amount of shared memory per block: 49152 bytesTotal shared memory per multiprocessor: 233472 bytesTotal number of registers available per block: 65536Warp size: 32Maximum number of threads per multiprocessor: 2048Maximum number of threads per block: 1024Max dimension size of a thread block (x,y,z): (1024, 1024, 64)Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)Maximum memory pitch: 2147483647 bytesTexture alignment: 512 bytesConcurrent copy and kernel execution: Yes with 3 copy engine(s)Run time limit on kernels: NoIntegrated GPU sharing Host Memory: NoSupport host page-locked memory mapping: YesAlignment requirement for Surfaces: YesDevice has ECC support: EnabledDevice supports Unified Addressing (UVA): YesDevice supports Managed Memory: YesDevice supports Compute Preemption: YesSupports Cooperative Kernel Launch: YesSupports MultiDevice Co-op Kernel Launch: YesDevice PCI Domain ID / Bus ID / location ID: 0 / 215 / 0Compute Mode:< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
-----------------------------------------------------------------------------------------------------[CUDA Bandwidth Test] - Starting...
Running on...Device 0: NVIDIA H800Quick ModeHost to Device Bandwidth, 1 Device(s)PINNED Memory TransfersTransfer Size (Bytes) Bandwidth(GB/s)32000000 55.2Device to Host Bandwidth, 1 Device(s)PINNED Memory TransfersTransfer Size (Bytes) Bandwidth(GB/s)32000000 55.3Device to Device Bandwidth, 1 Device(s)PINNED Memory TransfersTransfer Size (Bytes) Bandwidth(GB/s)32000000 2085.3Result = PASS-----------------------------------------------------------------------------------------------------==== Running single kernels ====Testing sgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0xbf800000, -1) beta= (0x40000000, 2)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 0.04317784 sec GFLOPS=25464.7
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0x0000000000000000, 0) beta= (0x0000000000000000, 0)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 0.00023699 sec GFLOPS=4.63952e+06
@@@@ dgemm test OK==== Running N=10 without streams ====Testing sgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0xbf800000, -1) beta= (0x00000000, 0)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 0.22819090 sec GFLOPS=48183.9
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 11.56301594 sec GFLOPS=950.887
@@@@ dgemm test OK==== Running N=10 with streams ====Testing sgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0x40000000, 2) beta= (0x40000000, 2)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 0.23047590 sec GFLOPS=47706.1
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 11.38687706 sec GFLOPS=965.595
@@@@ dgemm test OK==== Running N=10 batched ====Testing sgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0x3f800000, 1) beta= (0xbf800000, -1)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 0.21581888 sec GFLOPS=50946
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=8192 n=8192 k=8192 alpha = (0xbff0000000000000, -1) beta= (0x4000000000000000, 2)
#### args: lda=8192 ldb=8192 ldc=8192
^^^^ elapsed = 11.38980007 sec GFLOPS=965.348
@@@@ dgemm test OKTest Summary
0 error(s)
这篇关于H800基础能力测试的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






