本文主要是介绍23.HashMap的put方法流程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、put方法的流程图
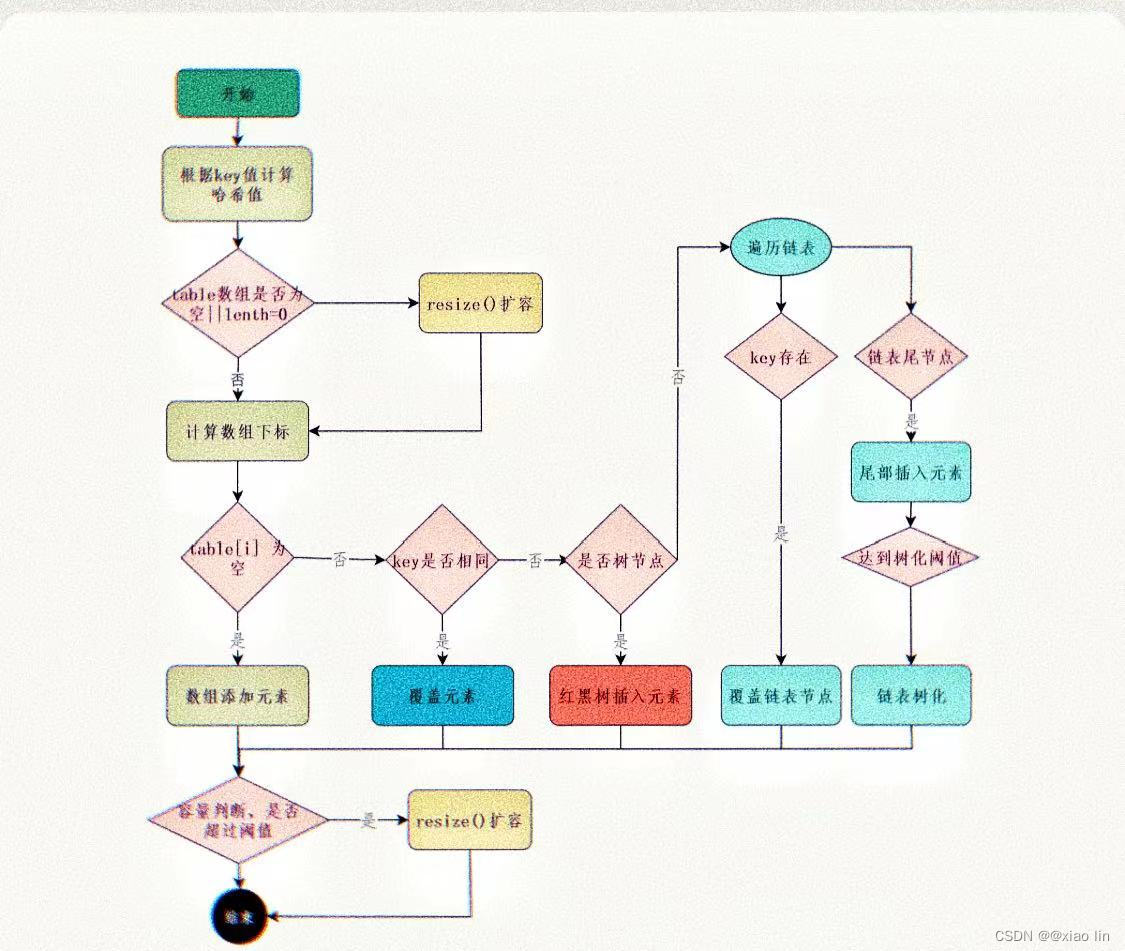
二、put方法的执行步骤
- 首先,根据key值计算哈希值。
- 然后判断table数组是否为空或者数组长度是否为0,是的话则要扩容,resize()。
- 接着,根据哈希值计算数组下标。
- 如果这个下标位置为空,添加元素即可。
- 如果这个下标位置不为空,则判断此下标位置的首元素的key值与要添加元素的key值是否相同,相同的话,就直接覆盖元素。
- 不相同的话,则判断首元素是否为树节点,是的话,则向这个红黑树中插入元素(在红黑树中插入一个新节点时,首先会遍历树以找到这个新节点应该插入的位置。在这个遍历过程中,也会检查是否已经存在相同key值的节点。如果存在,也会覆盖元素;不存在,则新节点会被插入到正确的位置)。
- 如果是链表的话,那就需要遍历链表,看key是否已经存在,存在则覆盖元素,不存在则在链表尾部插入元素。插入之后,如果链表长度大于等于8,则需要把链表转换为红黑树。
- 最后,待所有元素处理完之后,还要判断容量是否超过阈值,超过了则需要扩容。
三、对应源码:
/*** Computes key.hashCode() and spreads (XORs) higher bits of hash* to lower. Because the table uses power-of-two masking, sets of* hashes that vary only in bits above the current mask will* always collide. (Among known examples are sets of Float keys* holding consecutive whole numbers in small tables.) So we* apply a transform that spreads the impact of higher bits* downward. There is a tradeoff between speed, utility, and* quality of bit-spreading. Because many common sets of hashes* are already reasonably distributed (so don't benefit from* spreading), and because we use trees to handle large sets of* collisions in bins, we just XOR some shifted bits in the* cheapest possible way to reduce systematic lossage, as well as* to incorporate impact of the highest bits that would otherwise* never be used in index calculations because of table bounds.*/static final int hash(Object key) {//1.首先,根据key值计算哈希值。int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);}/*** Associates the specified value with the specified key in this map.* If the map previously contained a mapping for the key, the old* value is replaced.** @param key key with which the specified value is to be associated* @param value value to be associated with the specified key* @return the previous value associated with <tt>key</tt>, or* <tt>null</tt> if there was no mapping for <tt>key</tt>.* (A <tt>null</tt> return can also indicate that the map* previously associated <tt>null</tt> with <tt>key</tt>.)*/public V put(K key, V value) {return putVal(hash(key), key, value, false, true);//hash值}/*** Implements Map.put and related methods.** @param hash hash for key* @param key the key* @param value the value to put* @param onlyIfAbsent if true, don't change existing value* @param evict if false, the table is in creation mode.* @return previous value, or null if none*/final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;//2.然后判断table数组是否为空或者数组长度是否为0,是的话则要扩容,resize()。if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;//3.接着,根据哈希值计算数组下标。
//4.如果这个下标位置为空,添加元素即可。if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {//5.如果这个下标位置不为空,则判断此下标位置的首元素的key值与要添加元素的key值是否相同,相同的话,就直接覆盖元素。Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;//6.不相同的话,则判断首元素是否为树节点,是的话,则向这个红黑树中插入元素else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//7.如果是链表的话,那就需要遍历链表,看key是否已经存在,存在则覆盖元素,不存在则在链表尾部插入元素。不存在则在链表尾部插入元素。插入之后,如果链表长度大于等于8,则需要把链表转换为红黑树。else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);//转为红黑树break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;//8.最后,待所有元素处理完之后,还要判断容量是否超过阈值,超过了则需要扩容。if (++size > threshold)resize();afterNodeInsertion(evict);return null;}这篇关于23.HashMap的put方法流程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






