本文主要是介绍mysql----武侠剑客之-----MEMORY 存储引擎,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- mysql--------MEMORY 存储引擎
- 1、1 特点:
- 1、2 代码演示:
mysql--------MEMORY 存储引擎
1、1 特点:
1.frm文件存储表的结构信息
2 数据存放在内存中,没有表数据文件,重启后,数据丢失
3 使用表级锁
4 表的最大大小受参数max_heap_table_size的限制
1、2 代码演示:
创建表,添加数据,查看数据:存储引擎MEMORY

表中数据可以正常查询
相应的存储文件位置查看test表的.frm
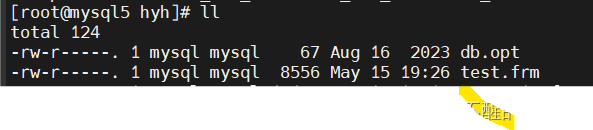
表的.frm存储文件结构查看正常
**重启mysql数据库后,表中添加的数据丢失:**
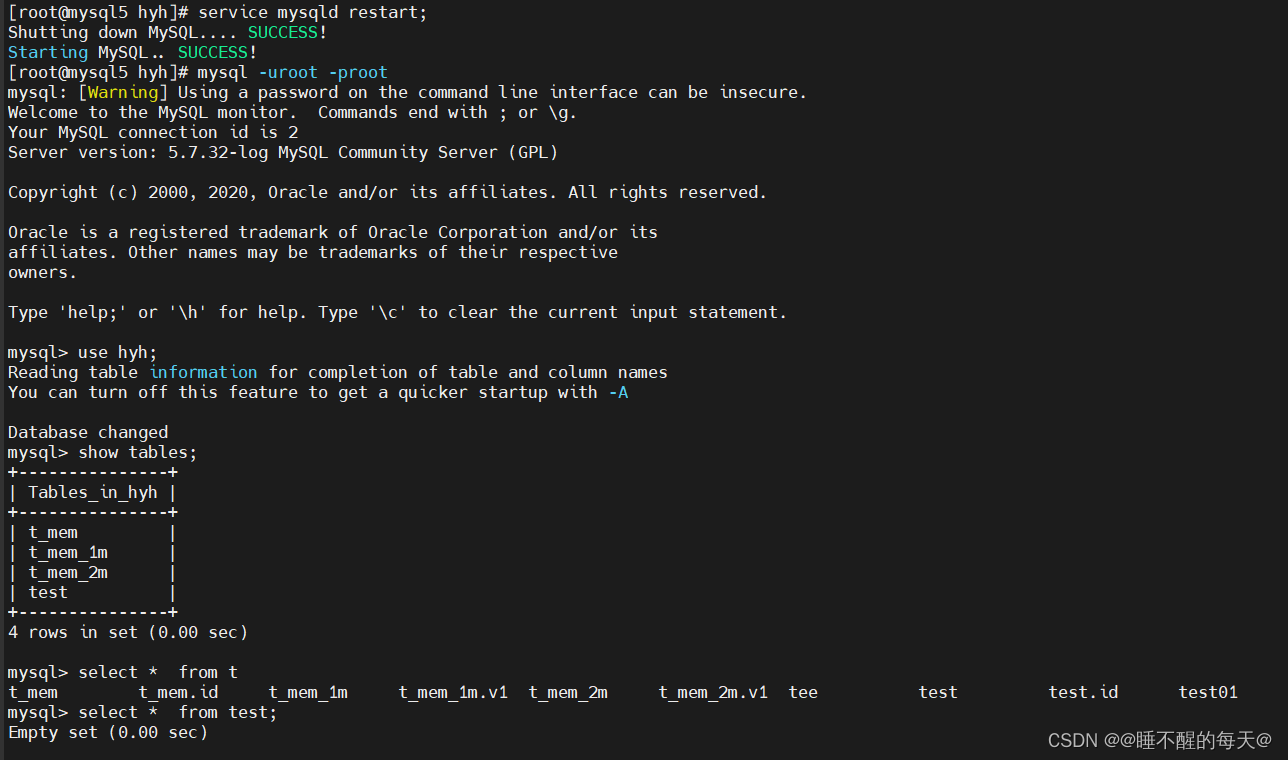
创建的数据库表存储引擎为MEMORY时,重启数据库的情况下会导致表中的数据全部丢失
表的存储引擎为MEMORY的情况下,表的最大大小受参数max_heap_table_size的限制:
测试参数设置:
set max_heap_table_size=1024*1024
create table test1(v1 varchar(10000)) engine=memory;set max_heap_table_size=1024*1024*3
create table test2(v1 varchar(10000)) engine=memory;set max_heap_table_size=1024*1024*8
create table test3(v1 varchar(10000)) engine=memory;show table status like ‘test%’ \G;查看:
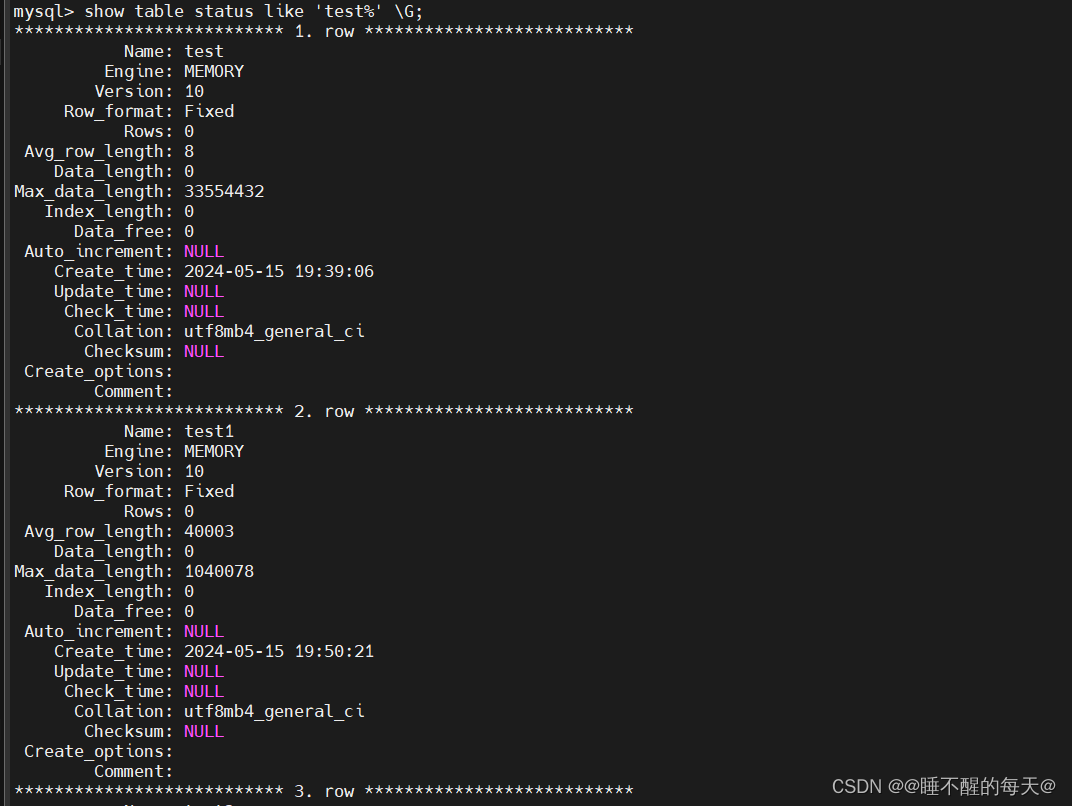

默认max_heap_table_size=33554432/1024=
32,768MB在这个范围之内max_heap_table_size参数可进行任意的设置
这篇关于mysql----武侠剑客之-----MEMORY 存储引擎的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







