本文主要是介绍CV每日论文--2024.5.10,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、Attention-Driven Training-Free Efficiency Enhancement of Diffusion Models
中文标题:扩散模型的注意力驱动的训练免费效率增强


简介:扩散模型在生成高质量和多样化图像方面取得了出色的表现,但其卓越性能是以昂贵的架构设计为代价的,特别是广泛使用注意力模块。现有的工作主要通过重新训练的方式来提高扩散模型的效率,但这种方法计算开销大,可扩展性也较差。
为此,我们提出了一种基于注意力驱动的无训练高效扩散模型(AT-EDM)框架。该框架利用注意力图在运行时修剪冗余标记,无需任何重新训练。具体而言,我们开发了一种新的排名算法"广义加权页面排名(G-WPR)"来识别冗余标记,并提出了一种基于相似性的恢复方法来恢复卷积操作的标记。此外,我们还提出了一种"去噪步骤感知修剪(DSAP)"方法,以调整不同去噪步骤之间的修剪预算,以获得更好的生成质量。
广泛的评估结果表明,AT-EDM在提高效率方面表现出色,例如,与Stable Diffusion XL相比,可节省38.8%的FLOPs,并提高了1.53倍的速度,同时保持了与完整模型几乎相同的FID和CLIP分数。项目网页:https://atedm.github.io。
2、Imagine Flash: Accelerating Emu Diffusion Models with Backward Distillation
中文标题:Imagine Flash:利用反向蒸馏加速emu扩散模型
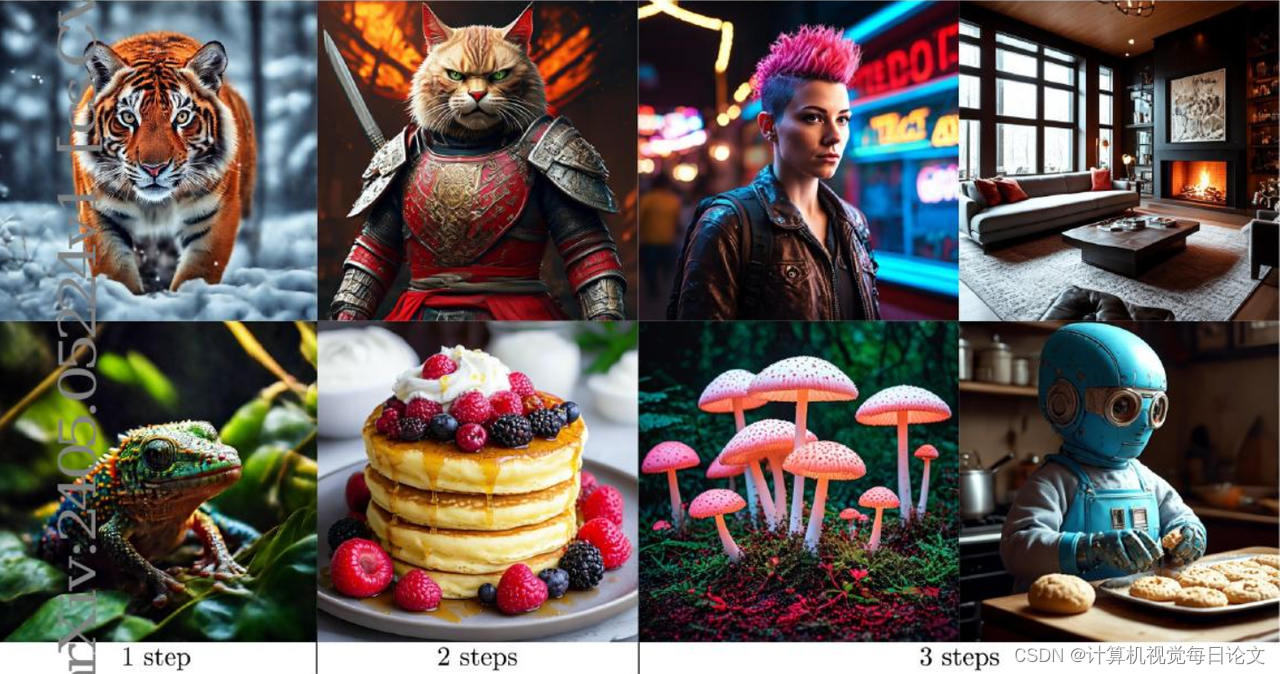

简介:扩散模型是一种强大的生成框架,但在推理时需要大量计算资源,这是一个主要挑战。现有的加速方法往往会损害生成图像的质量,或在极低步长的情况下无法良好工作。
在这项研究中,作者提出了一种新的蒸馏框架,目标是通过仅使用1-3个步骤就能实现高保真度和多样性的样本生成。这个方法包括三个关键组成部分:
反向蒸馏:通过在模型自身的反向轨迹上校准学生模型,来缓解训练-推理的差异。
移位重构损失:根据当前时间步动态调整知识转移,以提高生成的准确性。
噪声校正:在推理时采用的一种技术,通过解决噪声预测中的奇异性,来增强生成样本的质量。
作者通过大量实验证明,该方法在定量指标和人类评估方面都优于现有的竞争方法。值得一提的是,仅使用3个去噪步骤就能达到与教师模型相当的性能,实现了高效的高质量样本生成。
3、Picking watermarks from noise (PWFN): an improved robust watermarking model against intensive distortions
中文标题:从噪音中提取水印(PWFN):一种改进的抗强干扰水印模型

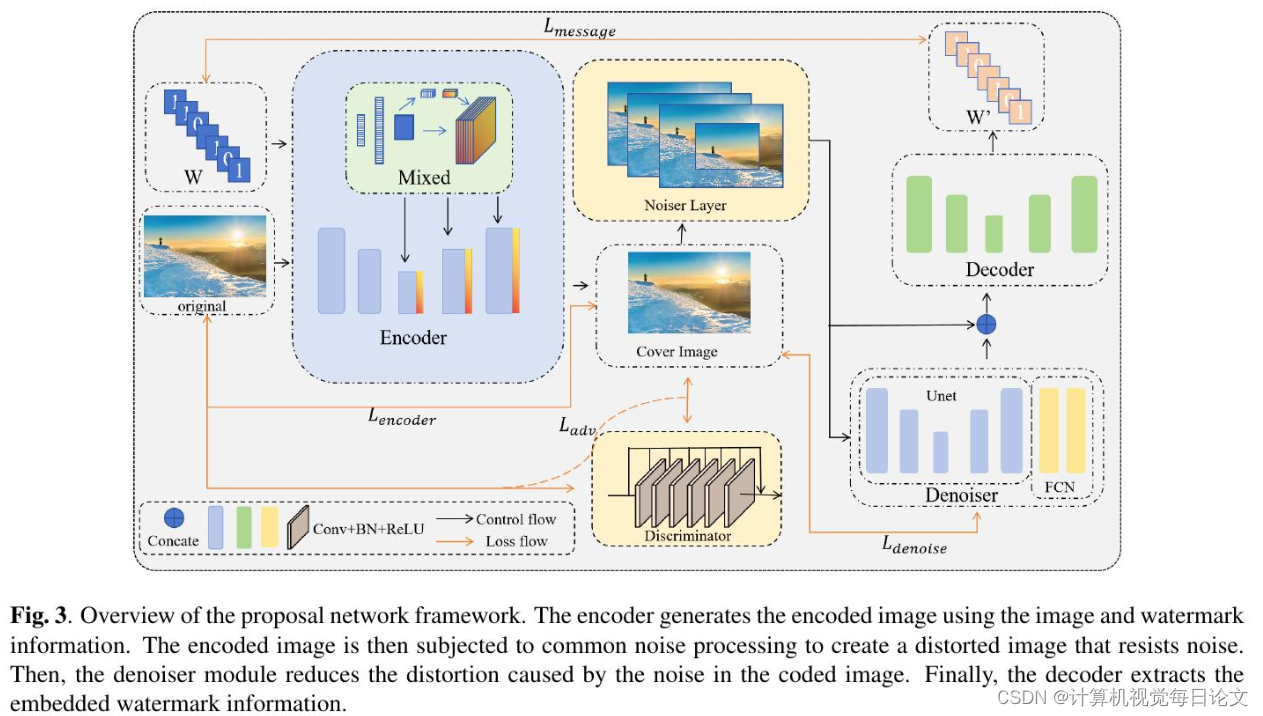
简介:数字水印技术能够将秘密信息嵌入图像中,而人眼是无法察觉这种改变的。为了提高模型的抗干扰能力,许多基于深度学习的数字水印方法使用了编码器-解码器架构,并向噪声层添加不同类型的噪声。解码器则从受损的图像中提取水印信息。但这种方法只能抵御较弱的噪声攻击。
为了提高算法对强噪声的鲁棒性,本文提出在噪声层和解码器之间引入去噪模块,以减少噪声干扰并恢复部分丢失的信息。此外,本文还引入了SE模块,在像素和通道维度融合数字水印信息,从而提高编码器的性能。
实验结果表明,本文提出的方法不仅与现有模型相当,在不同强度噪声下也优于最先进的方法。消融实验也验证了所提出模块的有效性。
总的来说,这项研究提出了一种新颖的数字水印方法,在抗噪声干扰方面显示出良好的性能。
这篇关于CV每日论文--2024.5.10的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









