本文主要是介绍C++ STL中sort()原理浅解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为什么会想要写这篇微博,主要发现在算法题中,很多题目都要使用到sort()来对数组进行一个排序,然后对其进行别的操作的时候会简单很多。所以就总结一下sort()的原理,以后有什么问题也可以追根溯源的解决一下,况且排序也是算法中重要的的组成部分之一,所以研究研究有利无害。sort()的使用方法为sort(begin,end),在一般的编程之中可以直接带入容器的begin()和end()函数来对,容器进行遍历。其函数包含在头文件<algorithm>中,其组成方面主要有两中排序方法(1)插入排序(2)快速排序。STL中定义了一个SORT_MAX变量来进行判断,如果大于SORT_MAX就使用快排,否则使用插排。
1、插入排序
插入排序的顺序如下,即按照顺序,从第一个数开始向后面依次遍历,寻找后面的元素在前面元素的位置,然后将数字插入进去,所以很容易知道插入排序的时间复杂度为O(n^2)次方,其实现程序如下:
void Insert_Sort(int *num,int n){int tmp=0;for(int i=0;i<n;i++){tmp=num[i];int j=i-1;while(j>=0&&tmp<num[j]){//将已经排序的数组和数本身相比如果比它大则将数组向后移num[j+1]=num[j];j--;}num[j+1]=tmp;}
}2快速排序:
快速排序是一种对于冒泡排序的方法的一种改进,冒泡排序是将两个相邻元素进行交换,而快速排序在此基础上使用了二分法对数组进行操作,确定一个基数的位置,然后对基数右侧的都是比基数大的数字,而左侧都是比它小的数字,然后再进行递归排序。但快速排序并不是一个稳定的排序的方法,其时间复杂度并不是确定的,其平均排序时间复杂度为O(nlogn),但当情况特殊时,其最差的时间复杂度为O(n^2)和冒泡排序相同,其基本排序的规则如下: 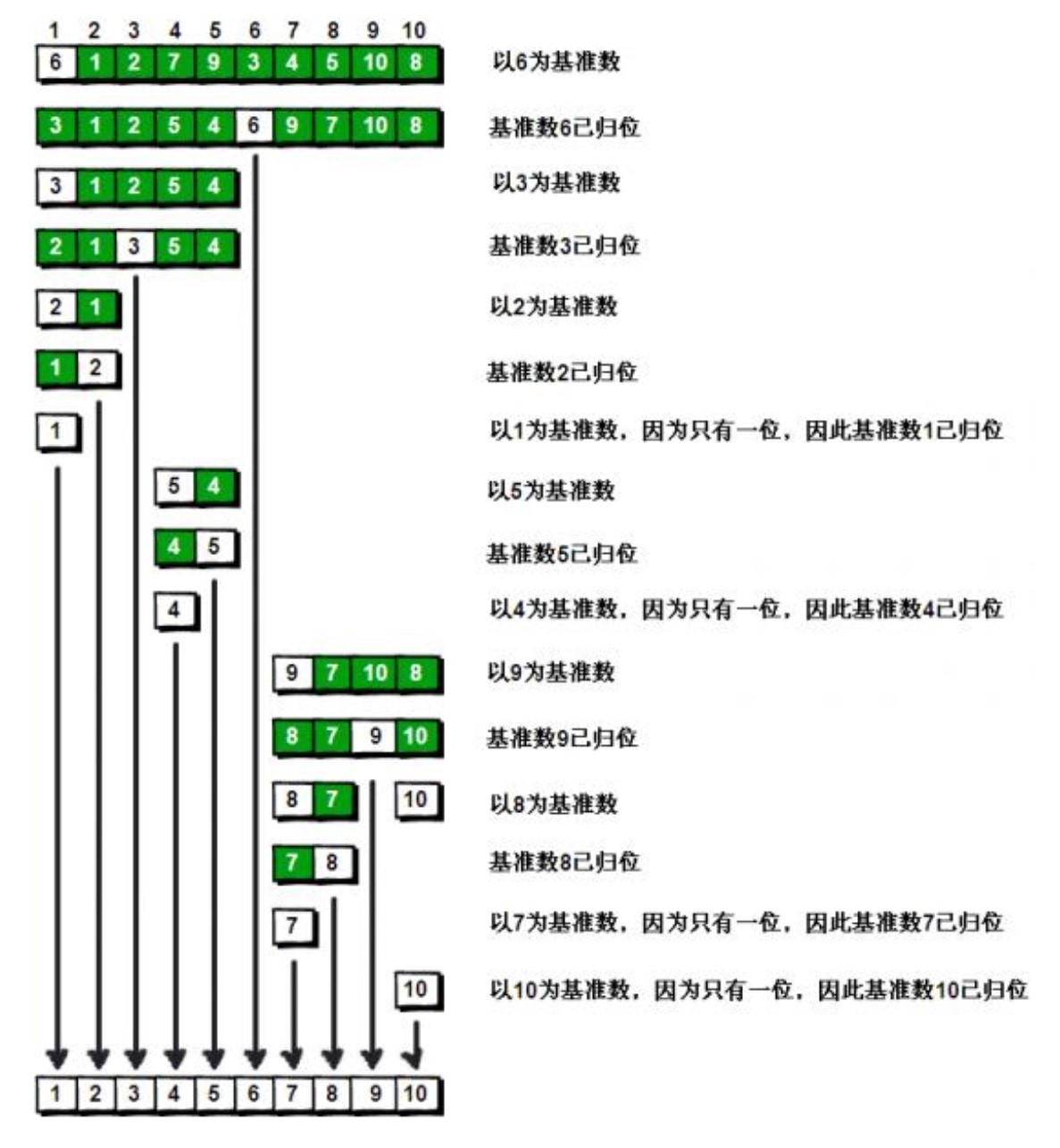
所以其实现要使用递归调用,其实现代码如下:
int a[101]
void Quicks_Sort(int begin,int end){//带入开始位置和结束位置if(begin>end)//若开始大于结束return;int tmp=a[begin];//确定基数int i=begin;int j=end;while(i!=j){while(a[j]>=tmp&&j>i)//寻找比基数小的数j--;while(a[i]<=tmp&&j>i)//寻找比基数大的数i++;if(j>i){//交换两者int t=a[i];a[i]=a[j];a[j]=t;}}a[begin]=a[i];//交换基数和其位置a[i]=tmp;Qiicks_Sort(begin,i-1);//左侧迭代Qicks_Sort(i+1,end);//右侧迭代
}其中需要先排右侧再排左侧,否则当某些情况下,当左侧先和右侧到达同一位置的时候排序会出现问题,其具体例子请见下面的博客:http://blog.csdn.net/w282529350/article/details/50982650
例子中出现了后面j需要小于i的情况,所以排序出错,最后需要提一下上面的程序大部分都是c实现的,而真正的STL源码中应该是用迭代器或者用迭代器操作符重载实现的,并非STL源码。
这篇关于C++ STL中sort()原理浅解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









