本文主要是介绍语音识别-paddlespeech-流程梳理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上一次研究语音识别是21年年底的事情了,记得当时是先进行了语音识别的应用,然后操作了模型的再次训练;两年过去,关于ASR相关流程忘得差不多了,这次基于paddlespeech的代码,进行了流程的梳理,关于一些细节还在学习中,先记录于此:
'zh:[conformer_wenetspeech-zh-16k], '
'en:[transformer_librispeech-en-16k], '
'zh_en:[conformer_talcs-codeswitch_zh_en-16k]'
本次测试的是中文、非流式模型,model = conformer_wenetspeech
语音识别,输入可以是.wav,输出是其对应的中文文字;
针对该测试调用的模型,该代码可简单分为三部分:
- Init model and other resources from a specific path;
- 对输入的.wav预处理,wav–>vector/tensor;
- 预测,并输出结果
针对第二部分,涉及到的基本是:文件的读取,及,特征提取,等。
涉及的关键词,比如是:
.wav的读取,波形变换,MFCC, pcm16 -> pcm 32,fbank,等;
涉及的库:soundfile,librosa,python_speech_features 等;
针对第三部分,可以分为三步来阐述:
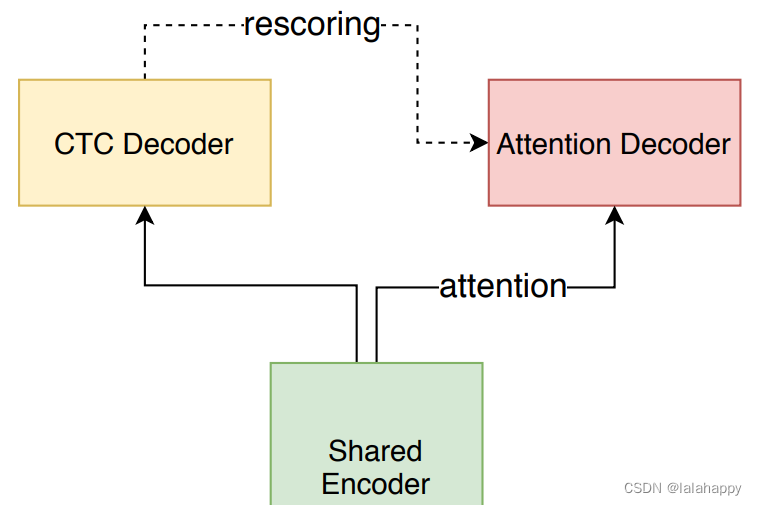
# paddlespeech.s2t.models.u2 line 876 --- U2Model(U2DecodeModel)
def _init_from_config(cls, configs: dict):"""init sub module for model.Returns:vocab size(int), encoder(nn.Layer), decoder(nn.Layer), ctc(nn.Layer)"""# U2 Encoder type: conformer---ConformerEncoder---paddlespeech.s2t.modules.encoder.py# U2 Decoder type: bitransformer---BiTransformerDecoder----error# U2 Decoder type: transformer---paddlespeech.s2t.modules.decoder.py# ctc decoder and ctc loss---CTCDecoderBase---paddlespeech.s2t.modules.ctc.py
第一步:代码调用了conformer-encoder,进行编码:
输入:(batch, max_len, feat_dim) — [1, 498, 80]
输出:(B, maxlen, encoder_dim) — [1, 123, 512]
第二步:使用 CTCDecoderBase + ctc prefix beam search 对 encoder-out 进行 操作,输出 beam_size个预测结果:
输入:(B, maxlen, encoder_dim) — [1, 123, 512]
输出:长度为beam_size的列表,列表的每一项包括一个预测结果,及其得分;
[((1719, 4412, 66, 4641, 2397, 2139, 4935, 4381, 3184, 1286, 2084, 3642,1719, 1411, 2180, 98, 4698, 205, 309, 1458), -0.0025442275918039605), ((1719, 4412, 66, 4641, 2397, 2139, 4935, 4381, 3184, 1286, 2084, 3642, 1719, 1411, 2180, 4698, 205, 309, 1458), -7.808644069258369), ----
]
第三步:使用 TransformerDecoder 进行最后的纠正与预测,其输入是第一步的encoder-out 和第二步的初步预测结果;
(['我认为跑步最重要的就是给我带来了身体健康'], [(1719, 4412, 66, 4641, 2397, 2139, 4935, 4381, 3184, 1286, 2084, 3642, 1719, 1411, 2180, 98, 4698, 205, 309, 1458)]
)
关于第二步的:CTCDecoderBase + ctc prefix beam search:
对于 CTCDecoderBase,其输入是:
输入:(B, maxlen, encoder_dim) — [1, 123, 512]
ctc_probs = self.ctc.log_softmax(encoder_out)
输出:(1, maxlen, vocab_size) — [1, 123, 5537]
将 encoder_out 进行了一个linear,输出维度是[1, maxlen, vocab_size],然后进行softmax,得到每一步的关于vocab的概率分布;
然后针对该输出,进行pefix beam search,得到:长度为beam_size的列表,其中,列表的每一项包括一个预测结果,及其得分;
关于prefix beam search:
这篇关于语音识别-paddlespeech-流程梳理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





