本文主要是介绍selenium进行xhs图片爬虫:06xhs一个博主的全部文章图片爬取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
📚博客主页:knighthood2001
✨公众号:认知up吧 (目前正在带领大家一起提升认知,感兴趣可以来围观一下)
🎃知识星球:【认知up吧|成长|副业】介绍
❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️
🙏笔者水平有限,欢迎各位大佬指点,相互学习进步!
保存文章url
本来我想这把实现爬取一个博主的全部文章图片爬取放在一个py文件中,后来想想还是分开吧。
那就涉及到爬取博主文章链接的存放,我这里是存放到txt文件中。
def save_to_txt(array,file_path="url_list.txt"):# 打开文件,以写入模式打开('w')with open(file_path, 'w') as file:# 遍历数组的每一个元素for item in array:# 将当前元素转换为字符串,并写入文件file.write(str(item) + '\n')
该函数就是将列表/数组中的每个元素存入txt的每行中。
当你熟悉01保存链接到txt.py文件后,你可以将其封装一下。如01保存链接到txt(代码重构).py
01保存链接到txt.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from collections import Counter # 解决去重+乱序问题
import re
import time
import os
import requests# # TODO 实现免登录爬虫
options = Options()
options.add_experimental_option("debuggerAddress", "127.0.0.1:9527")
driver = webdriver.Chrome(options=options)time.sleep(3)
# driver = webdriver.Chrome() # 直接这样爬取到的网址不全
url = "https://www.xiaohongshu.com/user/profile/613c82b800000000020270c1"
# url = "https://www.xiaohongshu.com/user/profile/6262794f000000002102a1e4"
# 访问某个网页
driver.get(url) # 使用驱动实例打开指定的网页
driver.maximize_window()
# 打印网页title
print(driver.current_url)
print(driver.title)
# TODO 该函数是用来返回每次网页中的链接最后数字,如https://www.xiaohongshu.com/explore/65f23536000000000d00f0cd的65f23536000000000d00f0cd,方便后续构造函数
def get_url_code(content):url_pattern = re.compile(r'href="/explore/(.*?)"')matches = url_pattern.findall(content)return matchestemp_height = 0
url_code_list = []
while True:content = driver.page_sourcenew_url_list = get_url_code(content)# print(new_url_list)url_code_list += new_url_list# 循环将滚动条下拉driver.execute_script("window.scrollBy(0,600)")# sleep一下让滚动条反应一下time.sleep(1)# 获取当前滚动条距离顶部的距离check_height = driver.execute_script("return document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;")# 如果两者相等说明到底了if check_height == temp_height:print("到底了")breaktemp_height = check_heightprint(check_height)unique_url_code_list = list(Counter(url_code_list))
print(unique_url_code_list)
print(len(unique_url_code_list))def get_url_list(unique_url_code_list):added_string = 'https://www.xiaohongshu.com/explore/'# 创建一个空列表来存放结果new_url_list = []# 循环遍历原始列表,将每个元素加上相同的字符串并存放到新的列表中for x in unique_url_code_list:new_url_list.append(added_string + x)print(new_url_list) # 输出加上相同字符串后的新列表new_url_list = new_url_list[::-1] # 倒序变成顺序return new_url_list# 得到了网址链接
url_array = get_url_list(unique_url_code_list)def save_to_txt(array,file_path="url_list.txt"):# 打开文件,以写入模式打开('w')with open(file_path, 'w') as file:# 遍历数组的每一个元素for item in array:# 将当前元素转换为字符串,并写入文件file.write(str(item) + '\n')save_to_txt(url_array)
01保存链接到txt(代码重构).py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from collections import Counter # 解决去重+乱序问题
import re
import time
import os
import requests# TODO 该函数是用来返回每次网页中的链接最后数字,如https://www.xiaohongshu.com/explore/65f23536000000000d00f0cd的65f23536000000000d00f0cd,方便后续构造函数
def get_url_code(content):url_pattern = re.compile(r'href="/explore/(.*?)"')matches = url_pattern.findall(content)return matches# TODO 浏览器进行滚动到最底部,返回网址的url中图片没有去重的网址
def browser_scrolling(url,driver):driver.get(url) # 使用驱动实例打开指定的网页driver.maximize_window()# 打印网页titleprint(driver.current_url)print(driver.title)temp_height = 0url_code_list = []while True:content = driver.page_sourcenew_url_list = get_url_code(content)# print(new_url_list)url_code_list += new_url_list # 图片url网址合并到一个list中,里面不免有重复,后续需要去重# 循环将滚动条下拉driver.execute_script("window.scrollBy(0,600)")# sleep一下让滚动条反应一下time.sleep(1)# 获取当前滚动条距离顶部的距离check_height = driver.execute_script("return document.documentElement.scrollTop || window.pageYOffset || document.body.scrollTop;")# 如果两者相等说明到底了if check_height == temp_height:print("到底了")breaktemp_height = check_heightprint(check_height)return url_code_list# TODO 通过传入每个url不同的部分,可以构造出每个完整的url,并且这里将其由倒序变成正序
def get_url_list(unique_url_code_list):added_string = 'https://www.xiaohongshu.com/explore/'# 创建一个空列表来存放结果new_url_list = []# 循环遍历原始列表,将每个元素加上相同的字符串并存放到新的列表中for x in unique_url_code_list:new_url_list.append(added_string + x)print(new_url_list) # 输出加上相同字符串后的新列表new_url_list = new_url_list[::-1] # 倒序变成顺序return new_url_list# TODO 该函数将数组内容按每个元素存入到txt文件中
def save_to_txt(array, file_path="url_list.txt"):# 打开文件,以写入模式打开('w')with open(file_path, 'w') as file:# 遍历数组的每一个元素for item in array:# 将当前元素转换为字符串,并写入文件file.write(str(item) + '\n')#TODO 该函数用于返回网页源代码,输入的是xhs链接
def get_html_code(url):headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"}response = requests.get(url, headers=headers)content = response.content.decode()return content# 获取当前时间戳,后续每个xhs网址的图片保存在每个时间戳中。
def get_time():import timetimestamp = int(time.time())return timestamp#TODO 实现输入一个图片url列表,将其中的图片保存到目录中,并按照1-nums排序,这样可以保证下载下来的图片顺序不乱。
#TODO 比如输入[图片链接1,图片链接2,图片链接3]和"image",最后就会生成image/时间戳的目录,然后在里面保存1.png,2.png,3.png
def image_save_batch(image_urls, save_dir):time_path = get_time()path = os.path.join(save_dir, str(time_path))if not os.path.exists(path):os.makedirs(path)for i, url in enumerate(image_urls):# 发送 GET 请求获取图片数据response = requests.get(url)# 确保请求成功if response.status_code == 200:# 生成图片文件名image_name = f"{time_path}/{i}.png"# 拼接图片保存路径save_path = os.path.join(save_dir, image_name)# 将图片数据写入文件with open(save_path, 'wb') as f:f.write(response.content)print(f'图片{i+1}已保存为: {save_path}')else:print(f'下载图片{i+1}失败,状态码: {response.status_code}')def get_img_url_list(content, path="images"):# 使用正则表达式提取网址url_pattern = re.compile(r'<meta name="og:image" content="(.*?)">')matches = url_pattern.findall(content)if matches:# 去重+顺序# unique_matches = list(set(matches)) # 会乱序unique_matches = list(Counter(matches))nums = len(unique_matches)print(f"图片数量:{nums}, 图片去重数量:{len(matches)-nums}")print(unique_matches)# # 打印每个网址# for i in range(nums):# print(unique_matches[i])# image_save(unique_matches[i], "images")image_save_batch(unique_matches, path)else:print("No URL found.")
if __name__ == '__main__':# # TODO 实现免登录爬虫options = Options()options.add_experimental_option("debuggerAddress", "127.0.0.1:9527")driver = webdriver.Chrome(options=options)time.sleep(3)# driver = webdriver.Chrome() # 直接这样爬取到的网址不全# url = "https://www.xiaohongshu.com/user/profile/6520e7d10000000024017cfc"url = "https://www.xiaohongshu.com/user/profile/6576a2b8000000003d02a409"url_code_list = browser_scrolling(url, driver)# 去重unique_url_code_list = list(Counter(url_code_list))print(unique_url_code_list)print(len(unique_url_code_list))# 得到了网址链接url_array = get_url_list(unique_url_code_list)save_to_txt(url_array)
爬取每篇文章的图片
爬取图片就是简单了,这个就是我们之前经常说的内容了。
if __name__ == '__main__':# 打开文件url_list = []with open('url_list.txt', 'r') as file:# 逐行读取文件内容for line in file:# 处理每行的内容,例如打印或者进行其他操作url_list.append(line.strip()) # 使用strip()方法去除每行末尾的换行符for i, url in enumerate(url_list):print(f"处理进度:{i+1}/{len(url_list)}现在正在处理的网址为:{url}")page_source = get_html_code(url)get_img_url_list(page_source)time.sleep(1)
这里就是首先读取txt内容,保存到列表中,然后用一个循环,每隔一秒去爬取每篇文章的图片。
02爬图片.py
from collections import Counter # 解决去重+乱序问题
import re
import time
import os
import requests#TODO 该函数用于返回网页源代码,输入的是xhs链接
def get_html_code(url):headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"}response = requests.get(url, headers=headers)content = response.content.decode()return content# 获取当前时间戳
def get_time():import timetimestamp = int(time.time())return timestamp#TODO 实现输入一个图片url列表,将其中的图片保存到目录中,并按照1-nums排序,这样可以保证下载下来的图片顺序不乱。
#TODO 比如输入[图片链接1,图片链接2,图片链接3]和"image",最后就会生成image/时间戳的目录,然后在里面保存1.png,2.png,3.png
def image_save_batch(image_urls, save_dir):time_path = get_time()path = os.path.join(save_dir, str(time_path))if not os.path.exists(path):os.makedirs(path)for i, url in enumerate(image_urls):# 发送 GET 请求获取图片数据response = requests.get(url)# 确保请求成功if response.status_code == 200:# 生成图片文件名image_name = f"{time_path}/{i}.png"# 拼接图片保存路径save_path = os.path.join(save_dir, image_name)# 将图片数据写入文件with open(save_path, 'wb') as f:f.write(response.content)print(f'图片{i+1}已保存为: {save_path}')else:print(f'下载图片{i+1}失败,状态码: {response.status_code}')def get_img_url_list(content, path="images"):# 使用正则表达式提取网址url_pattern = re.compile(r'<meta name="og:image" content="(.*?)">')matches = url_pattern.findall(content)if matches:# 去重+顺序# unique_matches = list(set(matches)) # 会乱序unique_matches = list(Counter(matches))nums = len(unique_matches)print(f"图片数量:{nums}, 图片去重数量:{len(matches)-nums}")print(unique_matches)image_save_batch(unique_matches, path)else:print("没有图片链接发现")if __name__ == '__main__':# 打开文件url_list = []with open('url_list.txt', 'r') as file:# 逐行读取文件内容for line in file:# 处理每行的内容,例如打印或者进行其他操作url_list.append(line.strip()) # 使用strip()方法去除每行末尾的换行符for i, url in enumerate(url_list):print(f"处理进度:{i+1}/{len(url_list)} 现在正在处理的网址为:{url}")page_source = get_html_code(url)# todo 路径编写get_img_url_list(page_source, path="images\\头像")time.sleep(1)
运行结果如下:
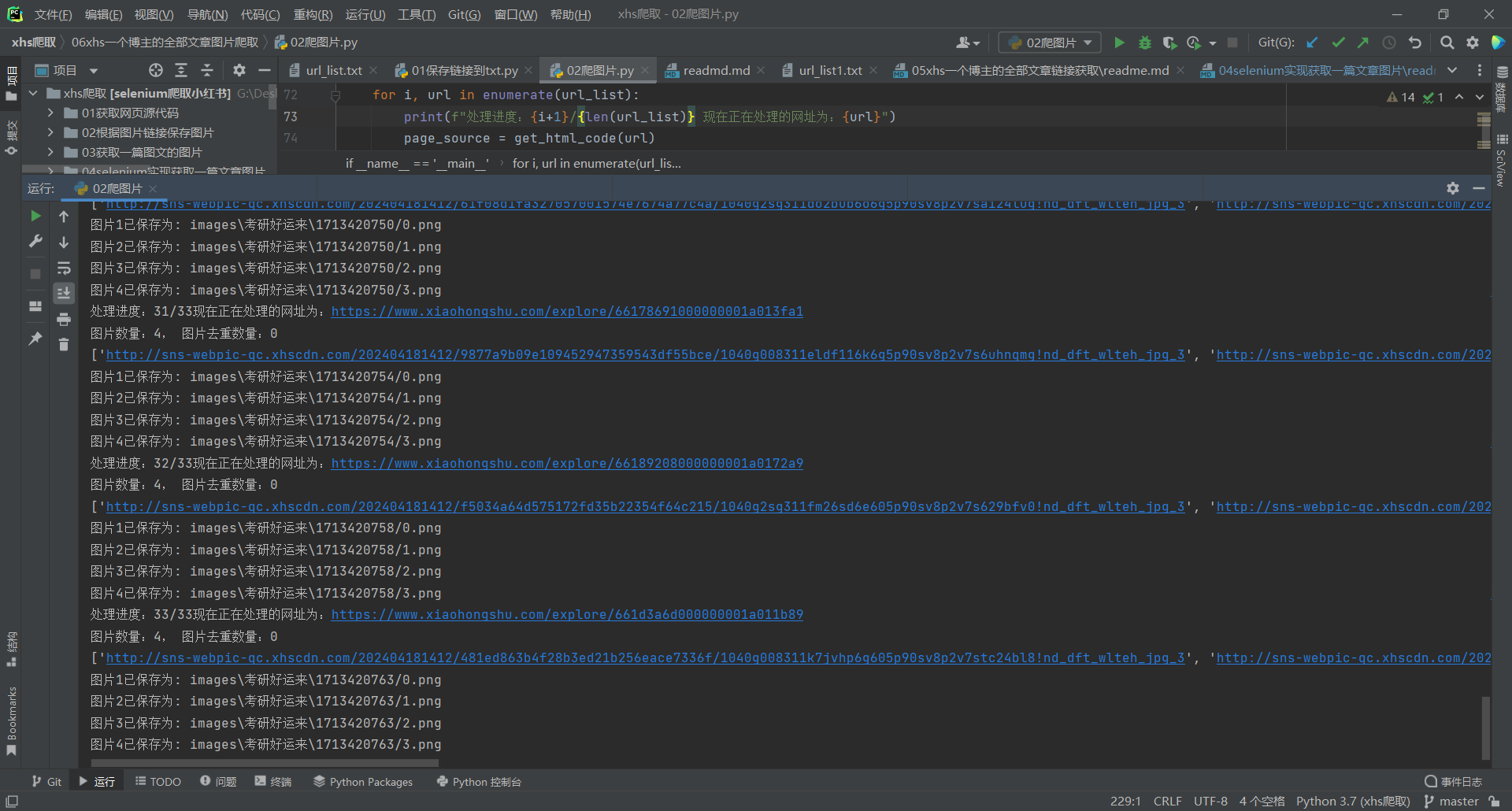
图片会保存在你命名的路径下,按照时间戳对每篇文章图片分类
最后
这里有个需要特别关注的地方。xhs视频会有一个封面,该代码也会爬取这个视频封面,而不是漏过这个视频。
这篇关于selenium进行xhs图片爬虫:06xhs一个博主的全部文章图片爬取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



