本文主要是介绍分布式追踪 APM 系统 SkyWalking 源码分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 概述
本文主要分享 SkyWalking DataCarrier 异步处理库。
基于生产者消费者的模式,大体结构如下图: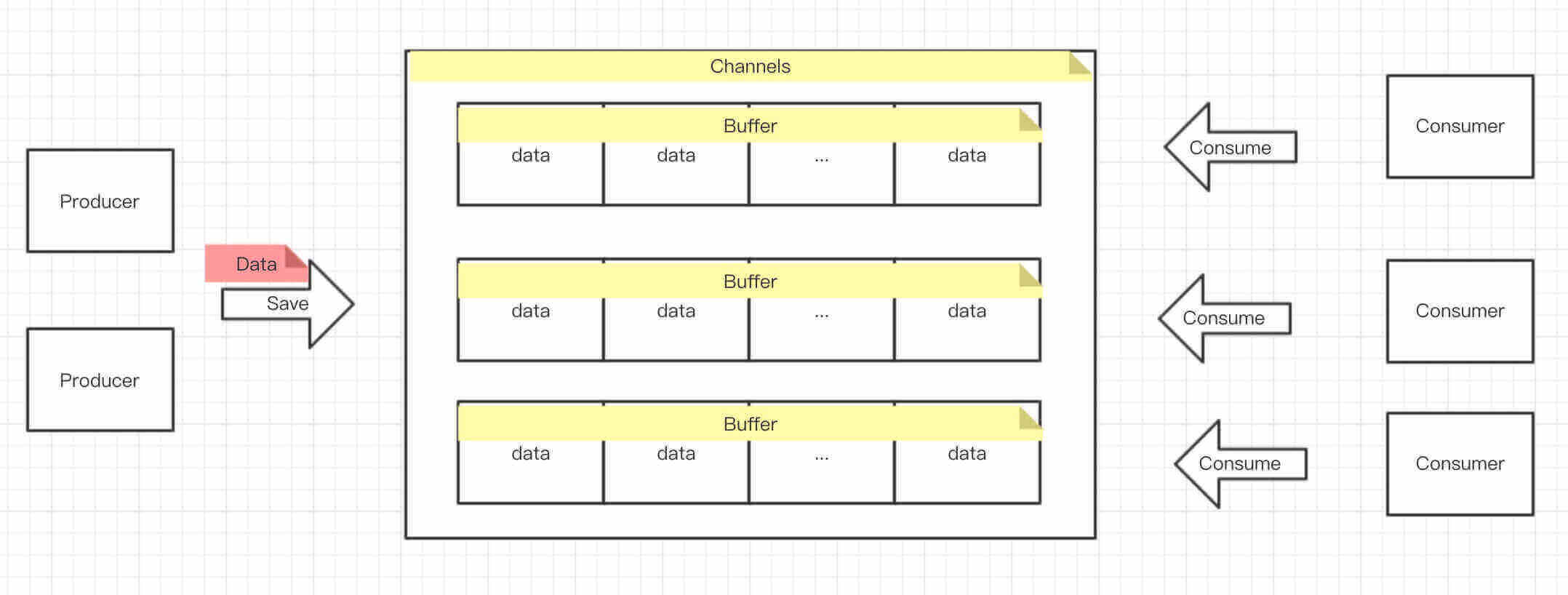
- 实际项目中,没有 Producer 这个类。所以本文提到的 Producer ,更多的是一种角色。
下面我们来看看整体的项目结构,如下图所示 :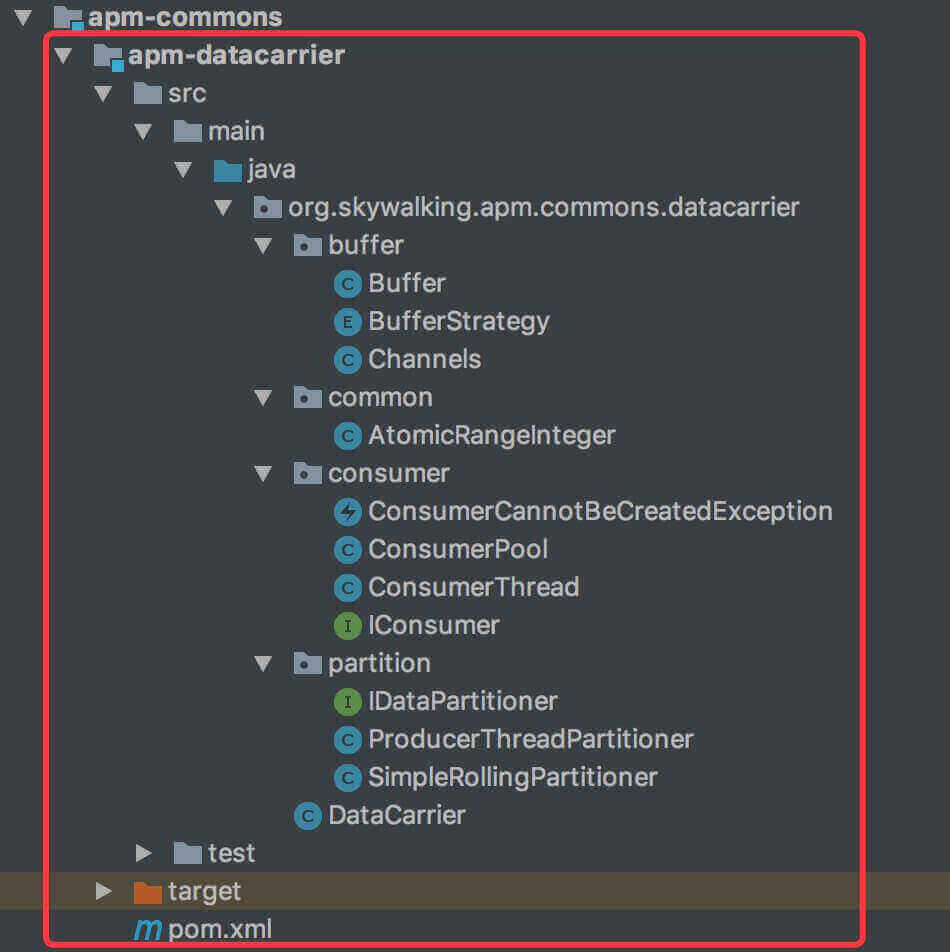
2. buffer
org.skywalking.apm.commons.datacarrier.buffer 包,主要包含 Channels 、Buffer 两个类。Channels 是 Buffer 数组的封装。
2.1 Buffer
org.skywalking.apm.commons.datacarrier.buffer.Buffer ,缓存区。
- buffer 属性,缓冲数组。Producer 保存的数据到 buffer 里。
- strategy ,缓冲策略( org.skywalking.apm.commons.datacarrier.buffer.BufferStrategy ) 。
- index 属性,递增位置( org.skywalking.apm.commons.datacarrier.common.AtomicRangeInteger)。
Buffer 在保存数据时,把 buffer 作为一个 “环“,使用 index 记录最后存储的位置,不断向下,循环存储到 buffer 中。通过这样的方式,带来良好的存储性能,避免扩容问题。But ,存储会存在冲突的问题:buffer 写入位置,暂未被消费,已经存在值。此时,根据不同的 BufferStrategy 进行处理。整体流程见 #save(data) 方法。
当 Buffer 被 Consumer 消费时,被调用 #obtain(start, end) 方法,获得数据并清空。为什么会带 start 、end 方法参数呢?下文揭晓答案。
2.2 Channels
org.skywalking.apm.commons.datacarrier.buffer.Channels ,内嵌多个 Buffer 的通道。
- bufferChannels 属性,Buffer 数组。
- dataPartitioner 属性,数据分区(org.skywalking.apm.commons.datacarrier.partition.IDataPartitioner )。
- strategy 属性,缓冲策略( org.skywalking.apm.commons.datacarrier.buffer.BufferStrategy ) 。
Channels 在保存数据时,相比 Buffer ,从 buffer 变成了多 buffer ,因此需要先选一个buffer 。通过使用不同的 IDataPartitioner 实现类,进行 Buffer 的选择。当缓冲策略为BufferStrategy.IF_POSSIBLE 时,根据 IDataPartitioner 定义的重试次数,进行多次保存数据直到成功。整体流程见 #save(data) 方法。
3. partition
org.skywalking.apm.commons.datacarrier.partition.IDataPartitioner ,数据分配者接口。定义了如下方法:
- #partition(total, data) 接口方法,获得数据被分配的分区位置。
- #maxRetryCount() 接口方法,获得最大重试次数。
IDataPartitioner 目前有两个子类实现:
- ProducerThreadPartitioner ,基于线程编号分配策略的数据分配者实现类。
- SimpleRollingPartitioner ,基于顺序分配策略的数据分配者实现类。
4. consumer
org.skywalking.apm.commons.datacarrier.consumer 包,主要包含 ConsumerPool 、ConsumerThread 、IConsumer 三个类。
- ConsumerThread 使用 IConsumer ,消费数据
- ConsumerPool 是 ConsumerThread 的线程池封装
4.1 IConsumer
org.skywalking.apm.commons.datacarrier.consumer.IConsumer ,消费者接口。定义了如下方法:
- #init() 接口方法,初始化消费者。
- #consume(List<T>) 接口方法,批量消费消息。
- #onError(List<T>, Throwable) 接口方法,处理当消费发生异常。
- #onExit() 接口方法,处理当消费结束。此处的结束时,ConsumerThread 关闭。
我们在使用时,自定义 Consumer 类,实现 IConsumer 接口。例如:RemoteMessageConsumer 。
4.2 ConsumerThread
org.skywalking.apm.commons.datacarrier.consumer.ConsumerThread ,继承 java.lang.Thread ,消费线程。
- running 属性,是否运行中。
- consumer 属性,消费者对象。
- dataSources 属性,消费消息的数据源( DataSource )数组。一个 ConsumerThread ,可以消费多个 Buffer ,并且单个 Buffer 消费的分区范围可配置,即一个 Buffer 可以被多个 ConsumerThread 同时无冲突的消费。在 「4.3 ConsumerPool」 详细解析 ConsumerThread 分配 Buffer 的方式。
- #addDataSource(sourceBuffer, start, end) 方法,添加 Buffer 部分范围。
- #addDataSource(sourceBuffer) 方法,添加 Buffer 全部范围。
#run() 实现方法,不断、批量的消费数据。代码如下:
- 第 78 至 88 行:不断消费,直到线程关闭( #shutdown() )。
- 第 80 行:调用 #consume() 方法,批量消费数据。
- 第 82 至 87 行:当未消费到数据,说明 dataSources 为空,等待 20 ms ,避免 CPU 空跑。
- 第 93 行:当线程关闭,调用 #consume() 方法,消费完 dataSources 剩余的数据。
- 第 95 行:调用 IConsumer#onExit() 方法,处理当消费结束。
#consume() 方法,批量消费数据。代码如下:
- 第 107 至 117 行:从 dataSources 中,获取要消费的数据。
- 第 120 至 126 行:当有数据可消费时,调用 IConsumer#consume(List<T>) 方法。当消费发生异常时,调用 IConsumer#onError(List<T>, Throwable) 方法。
- 第 127 行:返回是否有消费数据。
4.3 ConsumerPool
org.skywalking.apm.commons.datacarrier.consumer.ConsumerPool ,消费者池,提供了对 Channels 启动指定数量的 ConsumerThread 进行消费。
- running 属性,是否运行中。
- consumerThreads 属性,ConsumerThread 数组,通过构造方法的 num 参数进行指定。
- channels 属性,数据通道。
- lock 属性,锁。保证 ConsumerPool 启动或关闭时的线程安全。
#begin() 方法,启动 ConsumerPool ,进行数据消费。代码如下:
- 第 97 至 99 行:正在运行中,直接返回。
- 第 101 行:获得锁。
- 第 104 行:调用 #allocateBuffer2Thread() 方法,将 channels 的多个 Buffer ,分配给consumerThreads 的多个 ConsumerThread。
- 第 107 至 109 行:启动每个 ConsumerThread ,开始消费。
- 第 112 行:标记正在运行中。
- 第 114 行:释放锁。
close() 方法,关闭 ConsumerPool 。代码如下:
- 第 168 行:获得锁。
- 第 169 行:标记不在运行中。
- 第 170 至 172 行:关闭每个 ConsumerThread ,结束消费。
- 第 174 行:释放锁。
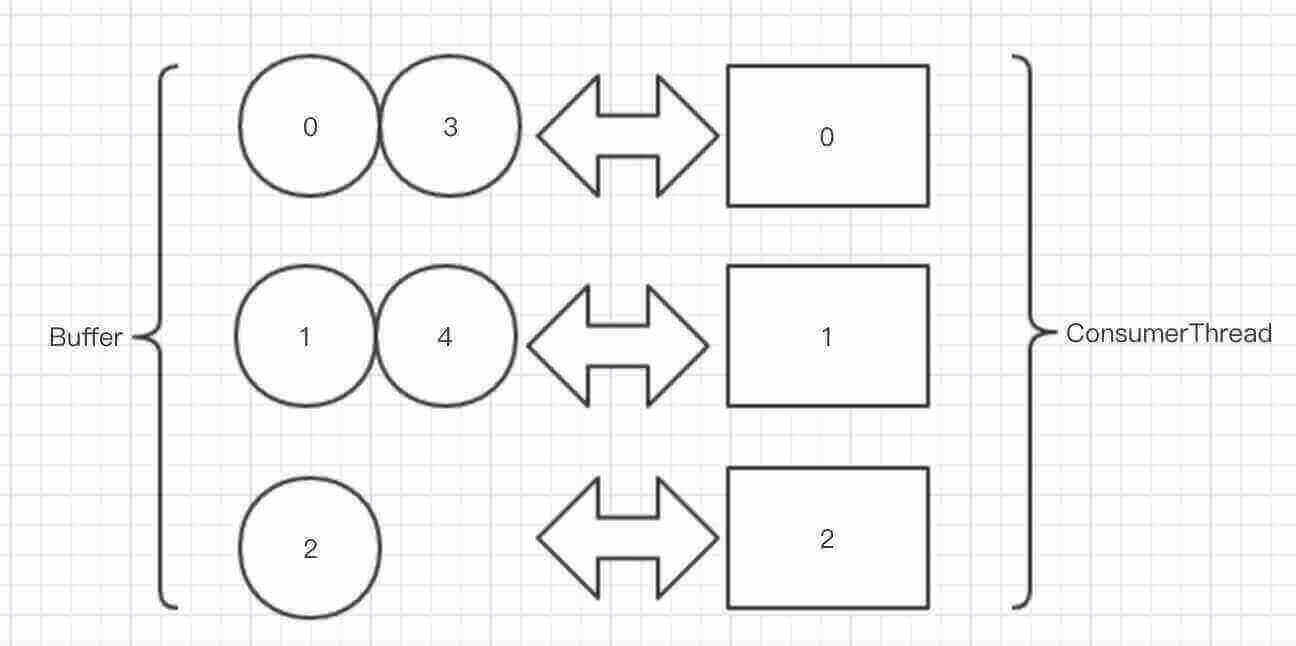
#allocateBuffer2Thread() 方法,将 channels 的多个 Buffer ,分配给 consumerThreads 的多个ConsumerThread。一共会有三种情况:
- Buffer 数量等于 ConsumerThread 数量,这个十分好分配,一比一。
- Buffer 数量大于 ConsumerThread 数量,那么按照 Buffer 数量 % ConsumerThread 数量进行分组,分配给 ConsumerThread ,如下图所示:
- Buffer 数量大于 ConsumerThread 数量,那么按照 ConsumerThread 数量 % Buffer 数量进行分组,分配给 Buffer 。其中,一个 Buffer 会被均分给多个 ConsumerThread ,如下图所示:
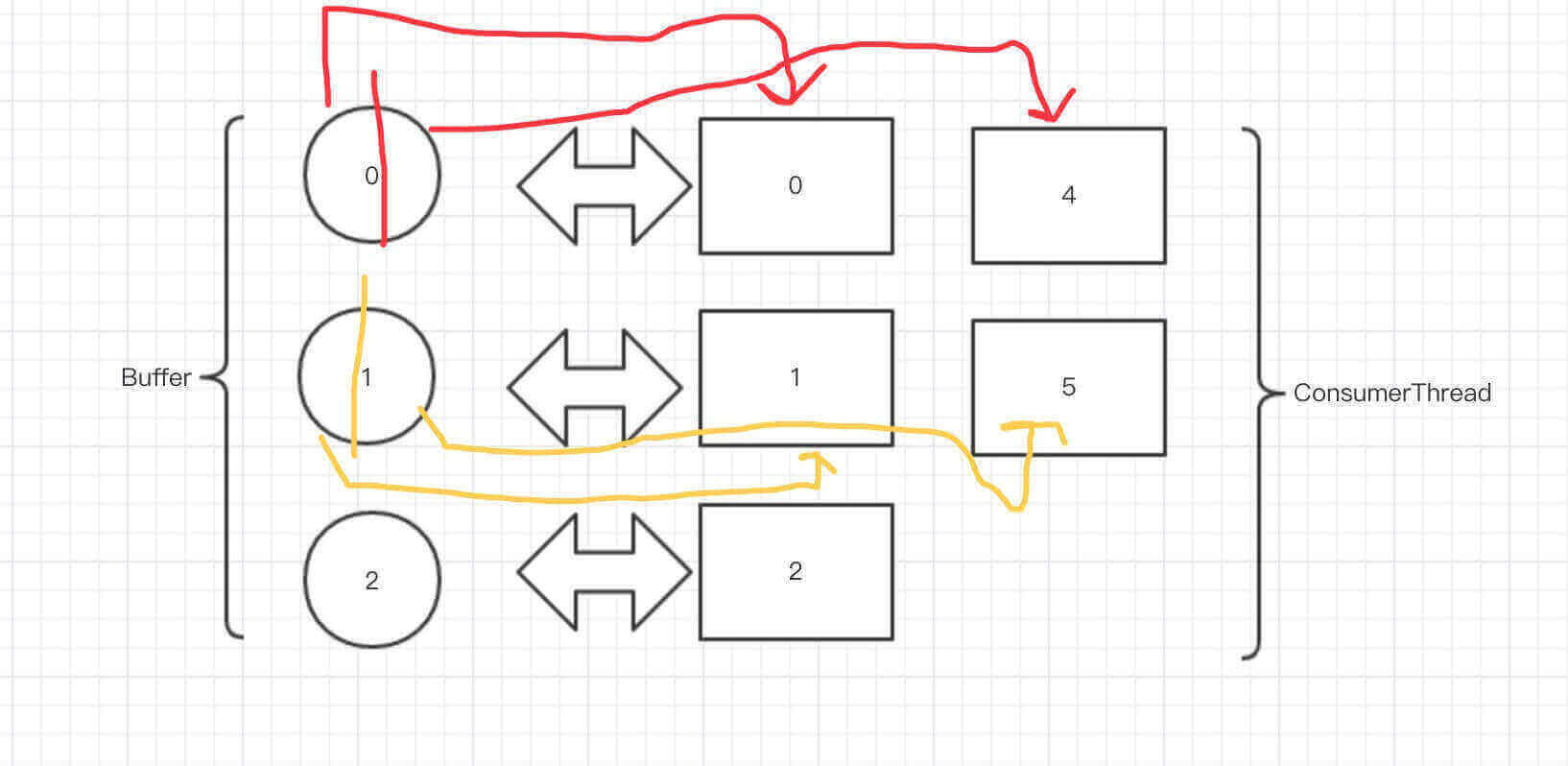
- 这个就是为什么 Buffer 里面,提供了 Buffer#obtain(start, end) 方法的原因。
4. DataCarrier
org.skywalking.apm.commons.datacarrier.DataCarrier ,DataCarrier 异步处理库的入口程序。通过创建 DataCarrier 对象,使用生产者消费者的模式,执行异步执行逻辑。
构造方法 ,代码如下:
- channels 属性,数据通道。在构造方法中,我们可以看到默认使用 SimpleRollingPartitioner 作为数据分区分配者,使用 BufferStrategy.BLOCKING 作为缓冲策略。
- #setPartitioner(IDataPartitioner) 方法,设置数据分区分配者。
- #setBufferStrategy(BufferStrategy) 方法,设置缓冲策略。
- channelSize 方法参数,通道大小。
- bufferSize 方法参数,缓冲区大小。
设置消费者和消费线程数量:
- #consume(Class<? extends IConsumer<T>>, num)
- #consume(IConsumer<T>, num)
生产消息
- #produce(data)
关闭消费
- #shutdownConsumers()
这篇关于分布式追踪 APM 系统 SkyWalking 源码分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







