本文主要是介绍改进YOLOv5,YOLOv5+CBAM注意力机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1. 目标检测模型
2. YOLOv5s
3. YOLOv5s融合注意力机制
4. 修改yolov5.yaml文件
5. ChannelAttentionModule.py
6. 修改yolo.py
1. 目标检测模型
目标检测算法现在已经在实际中广泛应用,其目的是找出图像中感兴趣的对象,并确定对象的类别和位置。本文将目标检测算法分为传统的技术和基于卷积神经网络的技术。传统的技术主要有基于颜色、基于纹理、基于形状和一些中高级语义特征的技术,检测的最终目标是准确地对检测对象进行识别和分类。检测步骤主要包括以下三个:区域选择、特征提取和分类器分类。首先将输入图像作为候选区域,使用不同大小、比例的滑动窗口以一定步长滑动;然后对每个候选区域的局部信息进行特征提取;最后使用分类器对检测的对象进行识别分类。在判断出检测对象预测框之后,可能会有一系列的预测框,并且这些预测框可能会有一些重叠遮挡问题。因此,需要使用非极大值抑制NMS(Non-MaximumSuppression)的方法来对这些预测框进行筛选和合并。虽然传统的检测技术可以在特定的情况下取得较好的效果,但其主要存在两个方面的问题:一是滑窗选择策略没有针对性,时间复杂度高,窗口冗余,无法满足实时监控的要求;二是手工设计的特征鲁棒性较差,在天气变化、物体分布不均匀等条件下,其准确度难以保证,泛化能力较差。此外,传统的手工设计特性还需要大量的先验知识。基于卷积神经网络的对象检测算法主要分为两类:
(1)由R-CNN(Region based Convolutional Neural Network)表示的两阶段算法;
(2)由YOLO(You Only Look Once)表示的基于回归的目标检测算法。
由YOLO表示的基于回归的目标检测算法真正实现了端到端训练,一次完成目标类别的确定和定位。整个网络结构只由卷积层和输入图像组成。卷积操作后,直接返回目标类别和位置。因此,单阶段目标检测算法快于两阶段目标检测算法,特别是YOLOv5,已达到先进的速度和精度水平。在DBT算法中,检测器效果的好坏严重影响目标跟踪的结果,并且检测器速率的快慢和模型的大小也是完成实时目标跟踪的关键。由于监控现场大多是算力较低的嵌入式设备,无法部署规模较大的检测模型。为了降低运算成本,加强实用性,本文选择YOLOv5系列中的最小模型YOLOv5s作为车辆检测的基础模型。
2. YOLOv5s
YOLOv5s的结构主要分为四个部分,Input输入端、Backbone主干网络、Neck网络、Head输出端,如图1所示。Input输入端主要包含对数据的预处理,包括Mosaic数据增强[11]、自适应图像填充,并且为了适用不同的数据集,YOLOv5s在Input输入端集成了自适应锚框计算,以便在更换数据集时,自动设定初始锚框大小。Backbone主干网络通过深度卷积操作从图像中提取不同层次的特征,主要利用了瓶颈跨阶段局部结构BottleneckCSP和空间金字塔池化SPP[21],前者的目的是为了减少计算量、提高推理速度,后者实现了对同一个特征图进行不同尺度的特征提取,有助于检测精度的提高。Neck网络层包含特征金字塔FPN、路径聚合结构PAN[22],FPN在网络中自上而下传递语义信息,PAN则自下而上传递定位信息,对Backbone中不同网络层的信息进行融合,进一步提升检测能力。Head输出端作为最后的检测部分,主要是在大小不同的特征图上预测不同尺寸的目标。
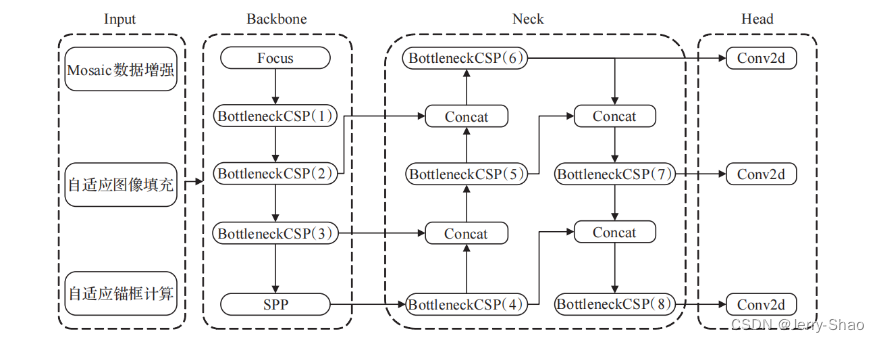
YOLOv5s网络结构
3. YOLOv5s融合注意力机制
在计算机视觉领域,注意力机制的有效性已经得到证明,并且已经广泛用于分类、检测、分割任务。在CNN网络中,注意力机制作用于特征图上,用于获取特征图中可用的注意力信息[23],主要包括空间注意力和通道注意力信息。卷积注意力模块(convolutional block attention module,CBAM)[24]同时关注了空间和通道信息,通过两个子模块CAM(channel attention module)和SAM(spatial attention module)对网络中间的特征图进行重构,强调重要特征,抑制一般特征,达到提升目标检测效果的目的,其结构如图所示。对于CNN网络中某一层的三维特征图F∈ℝC×H×W,CBAM顺序地从F推理出一维通道注意力特征图Mc和二维空间注意力特征图Ms,并分别进行逐元素相乘,最终得出与F同等维度的输出特征图,如公式(1)所示。其中F表示网络中某网络层特征图,Mc(F)表示CAM对F进行通道注意力重构,Ms(F′)表示SAM对通道注意力重构的结果F′进行空间注意力重构,⊗表示逐元素乘法。
F′=Mc(F)⊗FF″=Ms(F′)⊗F′ (1)
CAM和SAM的结构如图3所示。图(a)展示了CAM的计算过程,输入特征图F的每个通道同时经过最大池化和平均池化,得出的中间向量经过一个多层感知机(multi-layer perceptron,MLP),为了减少计算量,MLP只设计一个隐层,最后对MLP输出的特征向量进行逐元素加法并进行Sigmoid激活操作,得到通道注意力Mc。图(b)展示了SAM的计算过程,经过Mc激活的特征图F′沿通道方向上分别进行最大池化和平均池化,对得到的中间向量进行卷积操作,卷积结果经过Sigmoid激活之后得到空间注意力Ms。

CBAM结构

CAM和SAM模块结构
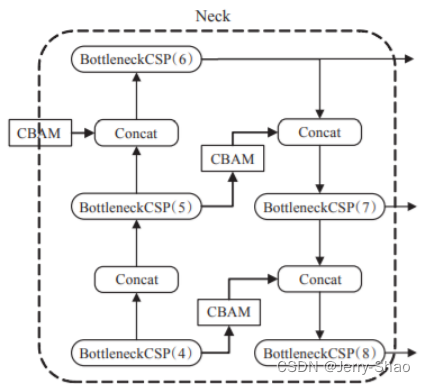
Neck融合CBAM
注意力机制最重要的功能是对特征图进行注意力重构,突出特征图中的重要信息,抑制一般信息,YOLOv5s网络中提取特征最关键的部分在Backbone,因此,本文将CBAM融合在Backbone之后,Neck网络的特征融合之前,这么做的原因是YOLOv5s在Backbone中完成了特征提取,经过Neck特征融合之后在不同的特征图上预测输出,CBAM在此处进行注意力重构,可以起到承上启下的作用,具体结构如上图所示。
4. 修改yolov5.yaml文件
# YOLOv5 🚀 by YOLOAir, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[-1, 1, CBAM, [1024]],[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]5. ChannelAttentionModule.py
新增一个ChannelAttentionModule.py文件,新增以下代码:
class ChannelAttentionModule(nn.Module):def __init__(self, c1, reduction=16):super(ChannelAttentionModule, self).__init__()mid_channel = c1 // reductionself.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.shared_MLP = nn.Sequential(nn.Linear(in_features=c1, out_features=mid_channel),nn.LeakyReLU(0.1, inplace=True),nn.Linear(in_features=mid_channel, out_features=c1))self.act = nn.Sigmoid()#self.act=nn.SiLU()def forward(self, x):avgout = self.shared_MLP(self.avg_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)maxout = self.shared_MLP(self.max_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)return self.act(avgout + maxout)class SpatialAttentionModule(nn.Module):def __init__(self):super(SpatialAttentionModule, self).__init__()self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)self.act = nn.Sigmoid()def forward(self, x):avgout = torch.mean(x, dim=1, keepdim=True)maxout, _ = torch.max(x, dim=1, keepdim=True)out = torch.cat([avgout, maxout], dim=1)out = self.act(self.conv2d(out))return outclass CBAM(nn.Module):def __init__(self, c1,c2):super(CBAM, self).__init__()self.channel_attention = ChannelAttentionModule(c1)self.spatial_attention = SpatialAttentionModule()def forward(self, x):out = self.channel_attention(x) * xout = self.spatial_attention(out) * outreturn out然后 在./models/common.py文件中,导入模块 CBAM。
6. 修改yolo.py
在for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部加入以下代码:
elif m is CBAM:c1, c2 = ch[f], args[0]if c2 != no:c2 = make_divisible(c2 * gw, 8)args = [c1, c2]这篇关于改进YOLOv5,YOLOv5+CBAM注意力机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




