本文主要是介绍Netty源码分析二NioEventLoop 剖析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
剖析方向
NioEventLoop是一个重量级的类,其中涉及到的方法都有很复杂的继承关系,调用链,要想把源码全部过一遍工作量实在是太大了,于是小编就基于下面的这些常见的问题来对NioEventLoop的源码来进行剖析
1.Seletor何时创建
1.1Selector为什么有两个Selector成员
2.nio线程在何时启动
3.每次循环时什么时候会进入SelecStrategy.SELECT分支
3.1何时会select阻塞,会阻塞多久
4.nio空轮询bug在哪里体现,Netty如何解决的?
5.ioRatio控制什么,设置为100有什么作用
6.Netty中对selectKeys优化是怎么回事
我们需要时刻记住下面这两点:
NioEventLoop的重要组成:Selector、线程、任务队列
NioEventLoop 线程不仅要处理 IO 事件,还要处理 Task(包括普通任务和定时任务)
具体剖析NioEventLoop
NioEventLoop的重要组成
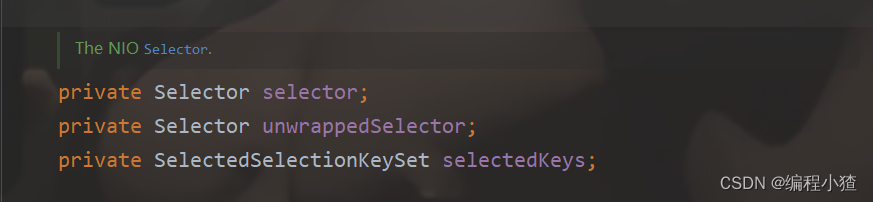
首先我们先来看一下NioEventLoop的几个重要的成员变量
Selector:
线程:0
线程不在NioEventLoop本类里面,在其祖父类SingleThreadEventExecutor里面
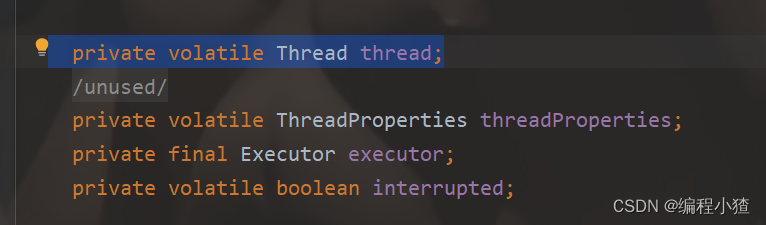
下面的Executor就是线程的执行器
任务队列:

在其曾祖父类AbstractScheduledEventExecutor里面有处理定时任务的任务队列

Selector何时创建
快捷键Ctrl+F12可以用来查看当前类的方法和成员变量,我们找Selector的构造方法

我们来研究一下上面标注的这行代码:
先来看一下SelectorTuple是什么:
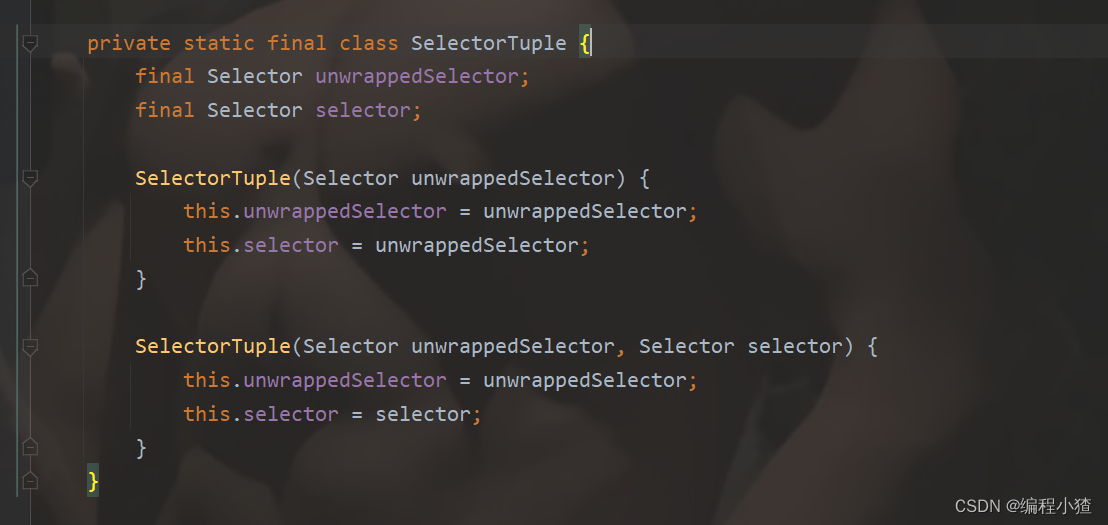
我们可以看到SelectorTuple是一个内部类,里面封装了Selector
然后再去看一下真正创建Selector的方法openSelector()
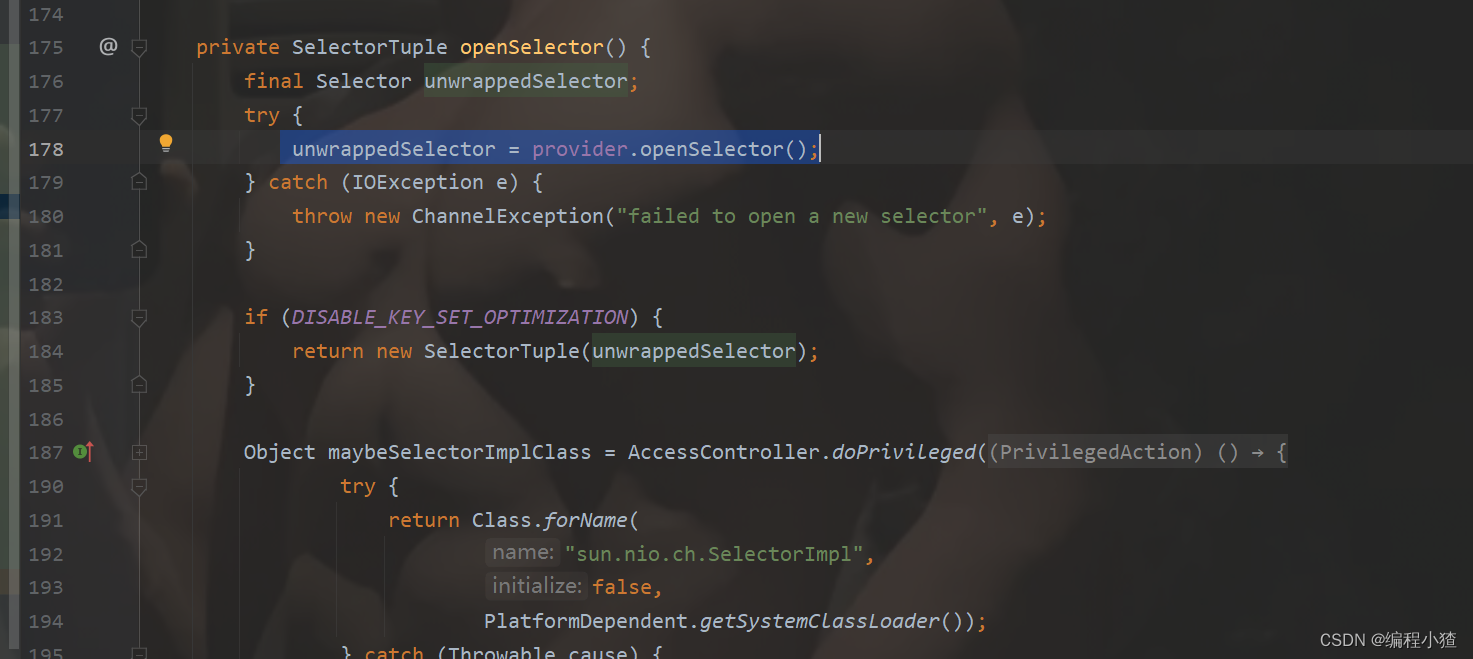
我们发现与NIO中的Selector创建一样也是通过SelectorProvider这个类创建的,SelectorProvider是一个抽象工厂类,Selector的创建过程体现了工厂设计模式。
那么看完源码之后就可以回答上面的问题了:Selector是何时创建的呢?在构造方法调用的时候创建。
Selector为什么有两个Selector成员
我们读源码可以看到在NioEventLoop这个类中有两个Selector成员
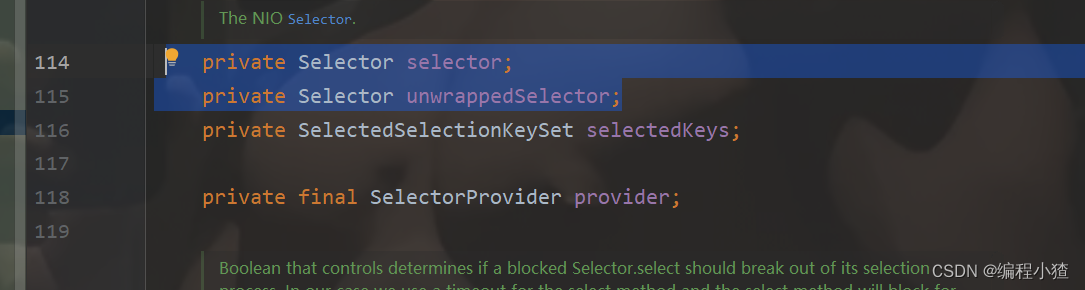
我们来看openSelector()这个方法

我们发现调用工厂类获得的Selector实例赋值给了unwrappedSelector,此处的Selector实例是与NIO中的Selector实例是同一种,因为它们都是通过同一个工厂类获得的,因此unwrappedSelector才是真正的底层NIO的Selector。这里讲一下Netty中的Selector与NIO中的Selector区别:NIO中的Selector内部有一个selectedKeys集合,这个集合里面存储了监听的事件类型SelectionKey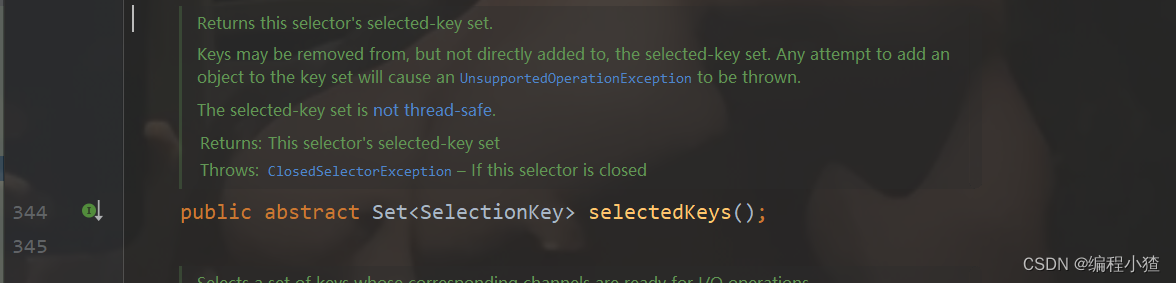
我们可以看到这个集合是一个Set集合,但是Set由于底层是一个哈希表,哈希表的遍历需要遍历每一个哈希桶,因此遍历的性能不高。Netty中的selectedKeys集合就对这点做了优化,改用数组来存储SelectionKey提高了遍历性能。我们可以看是通过反射机制来改用数组进行存储的。

看完源码我们可以回答上面的问题了:unwrappedSelector是原生的NIO中的Selector,selector是Netty中经过优化后的Selector,原生的Selector采用Set存储SelectionKey,NIO中的Selector采用数组存储SelectionKey,为了在遍历SelectionKey时提高性能,同时在其他地方使用到原生的Selector,因此有两个Selector成员。
nio线程在何时启动
为了了解清除nio线程是如何启动的,我写了一个测试类,以debug的模式来分析。
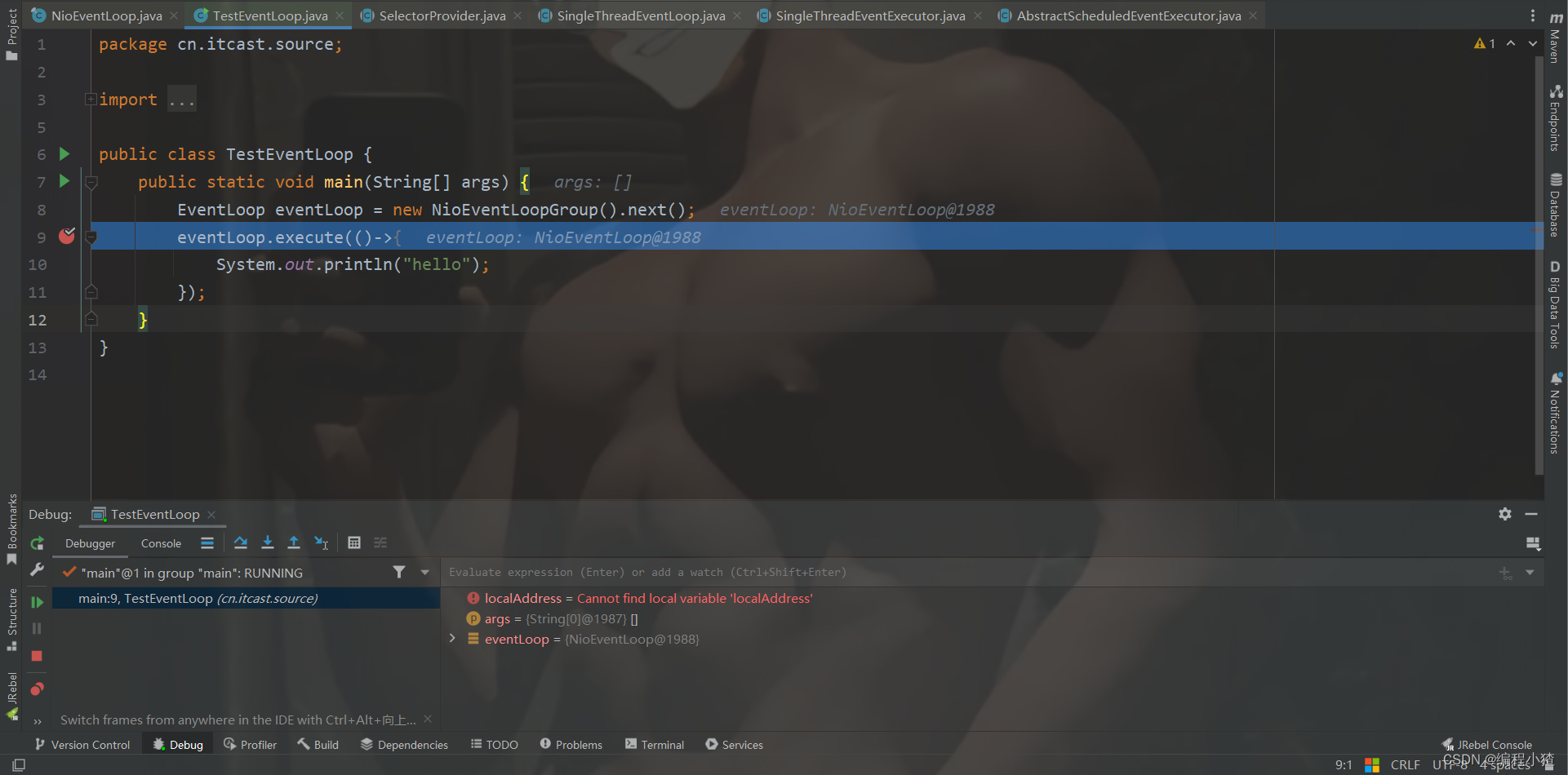
进入到execute方法中
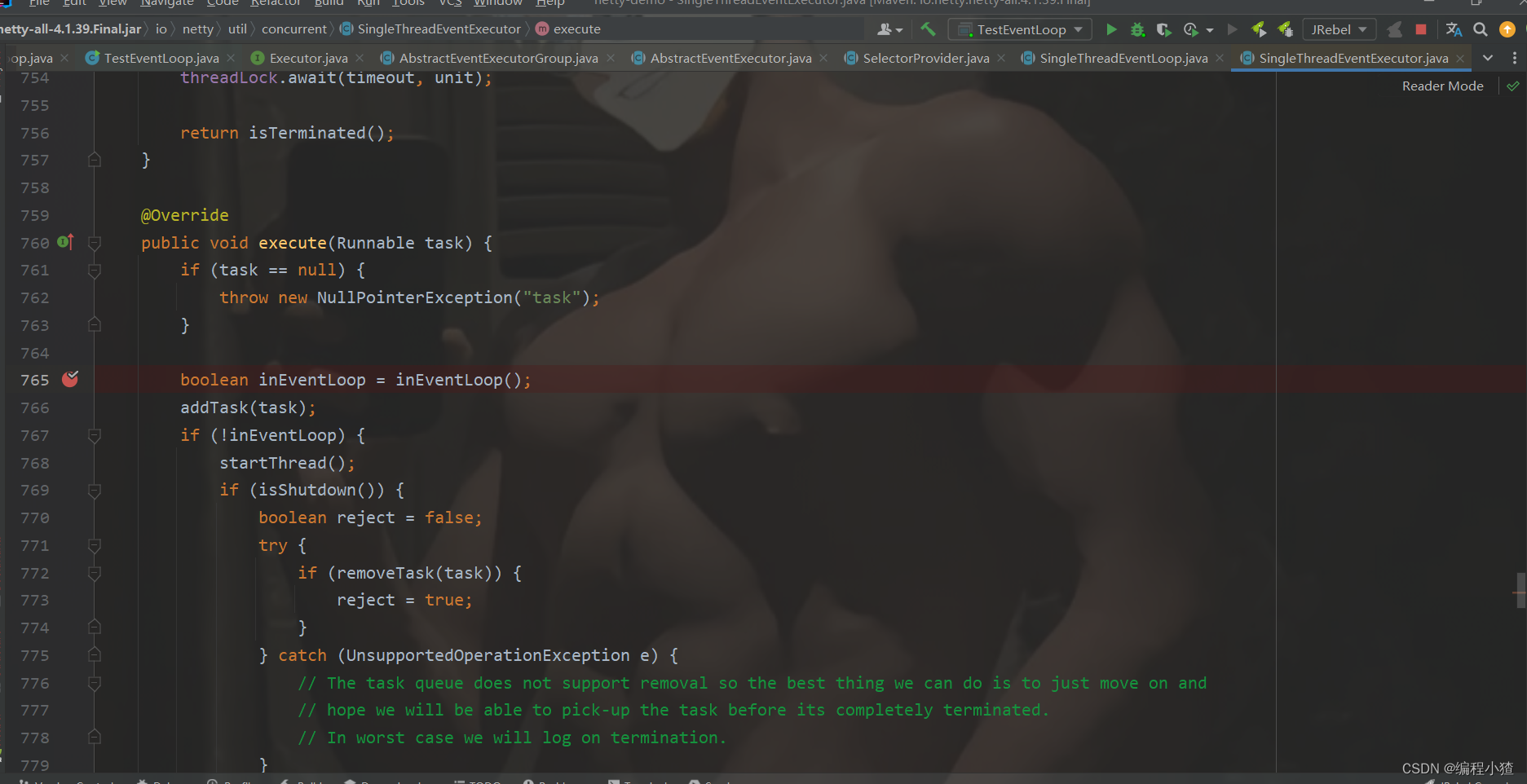
我们看到先是做了一个非空判断,然后调用inEventLoop()方法。我们去看一下inEventLoop()的源码。

我们可以看到就是用于判断当前线程是否为EventLoop线程,刚开始EventLoop中的线程为空,所以肯定返回false。

之后把任务加入到任务队列里面,之后进入到一个if判断中进行首次调用,启动线程。
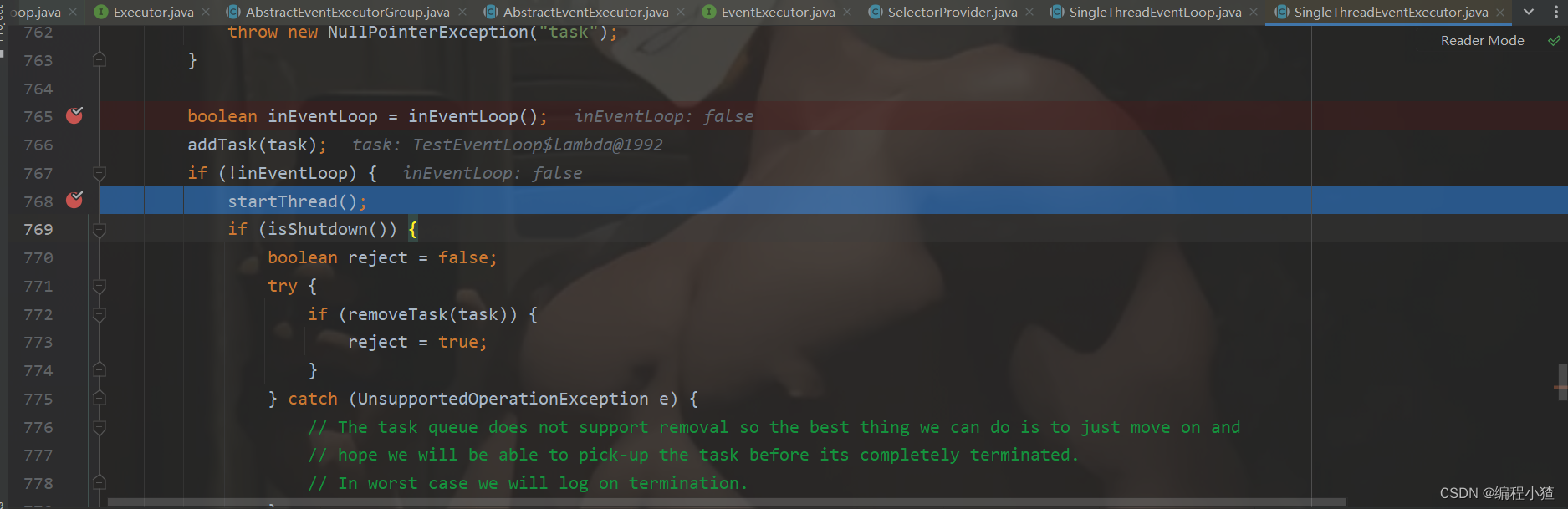
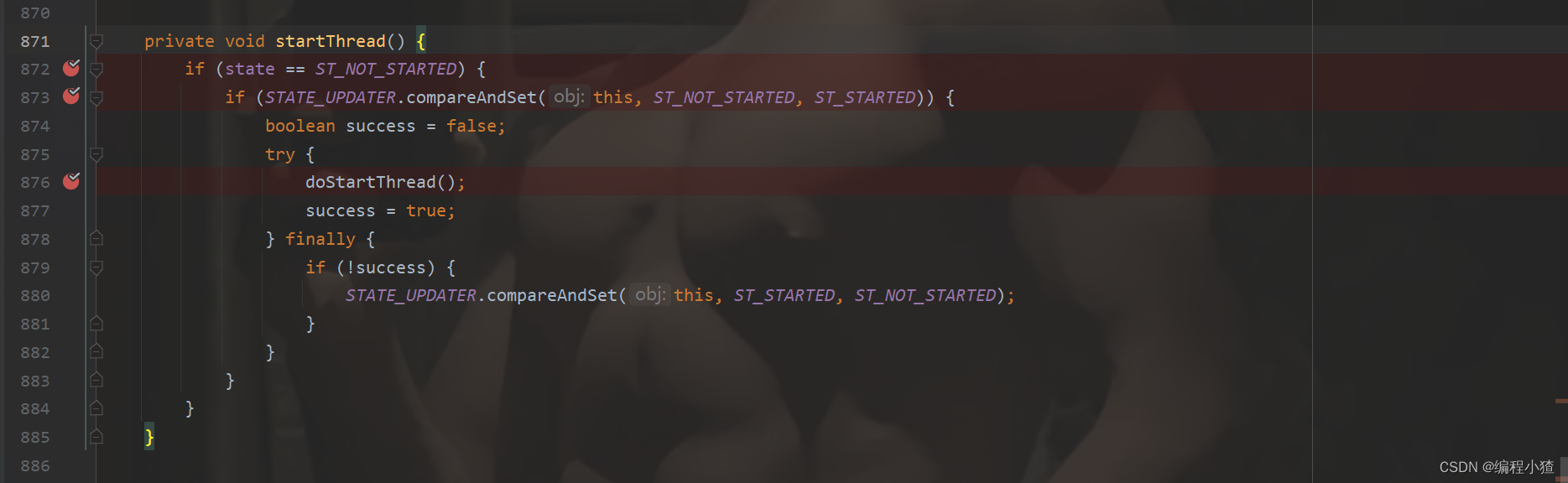
进入到startThread()方法,这里修改了state状态后进入方法,确保EventLoop线程开启只被调用一次。

进入到doStartThread();这里面就是真正地开启EventLoop线程
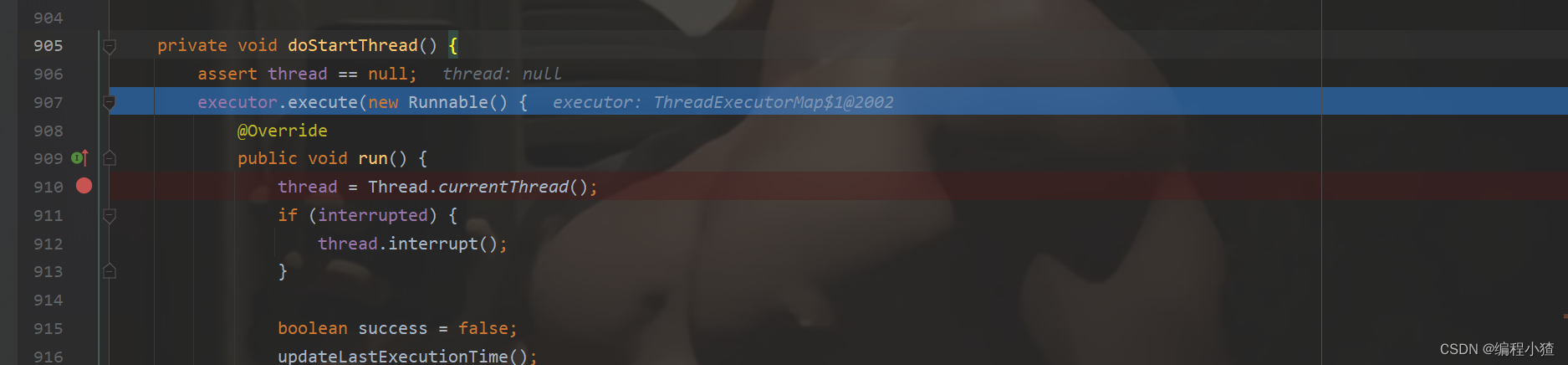
thread = Thread.currentThread(),在executor执行器中创建了线程,并把当前线程赋值给了EventLoop的thread成员变量中,此时一个nio线程就初始化成功了。

进入到SingleThreadEventExecutor.this.run();

我们可以看到这是一个死循环,这个死循环里不断地寻找IO事件以及是否有要处理地Task任务。
看完源码之后我们就可以回答上面的问题了
当首次调用execute方法时,会启动EventLoop的Nio线程,通过一个state状态位来控制线程只会启动一次。
每次循环时什么时候会进入SelecStrategy.SELECT分支
源码位置
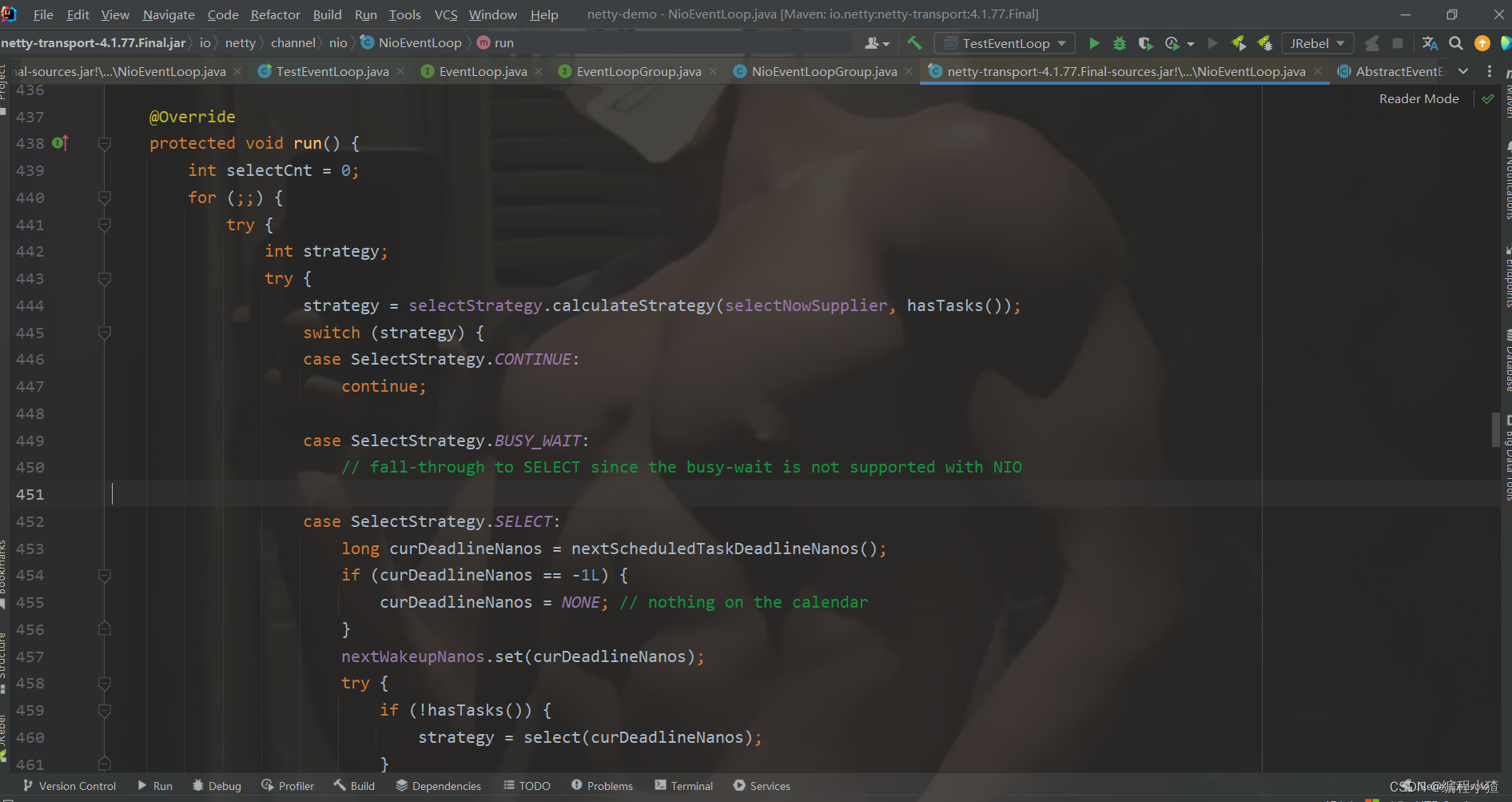
决定是否进入分支的代码如下:
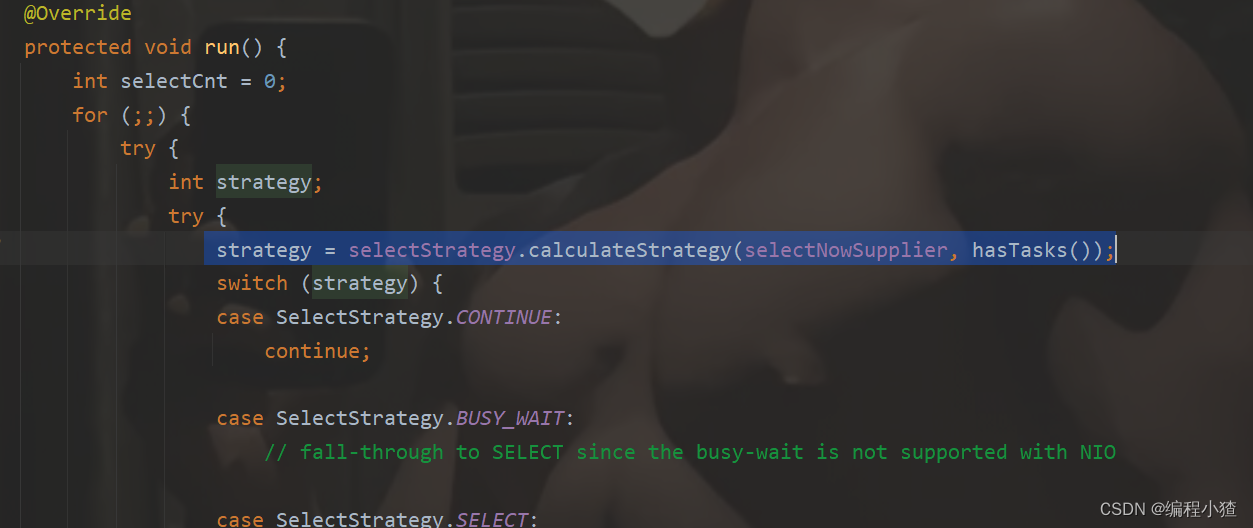
选中calculateStrategy方法,由于是一个接口,因此使用快捷键ctrl+alt+b进入到这个接口的实现类中

看到这里可以知道当hasTasks变量为false时(没有任务要执行时才会进入SelecStrategy.SELECT分支);当有任务时会调用selectNow方法顺便拿到io事件,连同普通任务一起交给下面的逻辑去执行。
何时会select阻塞,阻塞多久?
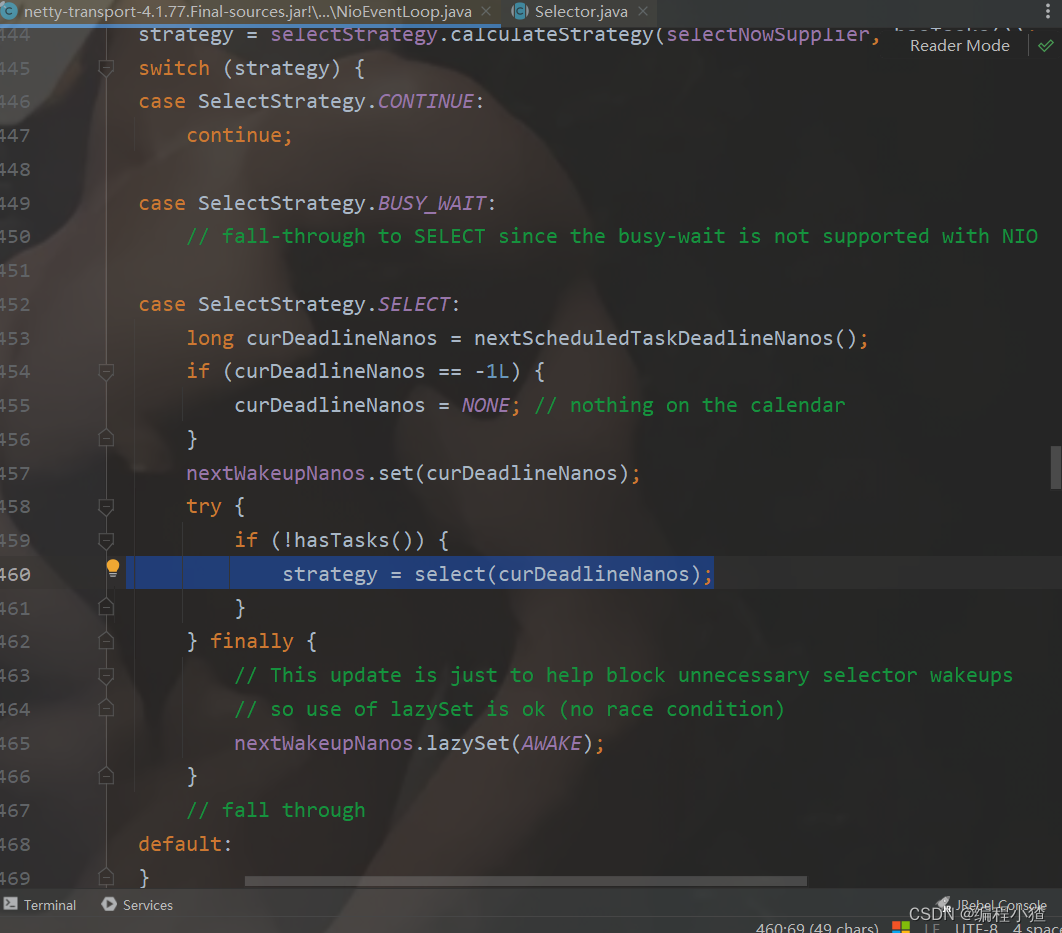
当进入到SelectStrategy.SELECT分支后,我们发现不会一直阻塞,有一个阻塞时间curDeadlineNanos。
以下是Netty中NioEventLoop类的select方法的一部分源码,用于说明阻塞时间的计算:
private int select(long deadlineNanos) throws IOException {if (deadlineNanos == NONE) {// 无定时任务,直接阻塞return selector.select();}// 计算阻塞时间long timeoutMillis = deadlineNanos - System.nanoTime();if (timeoutMillis <= 0) {return selector.selectNow();}// 阻塞指定的毫秒数return selector.select(timeoutMillis);
}
在这个方法中,deadlineNanos表示下一次定时任务的到期时间(以纳秒为单位)。如果deadlineNanos是NONE,表示没有定时任务,select方法会无限期地阻塞,直到至少有一个通道的I/O事件就绪。如果deadlineNanos是一个具体的值,Netty会计算当前时间和deadlineNanos之间的差值,得到阻塞时间timeoutMillis。
如果timeoutMillis小于或等于0,表示定时任务已经到期,selectNow()方法会被调用,这个方法不会阻塞,立即返回就绪的通道。如果timeoutMillis大于0,select方法会阻塞最多timeoutMillis毫秒,直到有I/O事件就绪或者阻塞时间超过timeoutMillis。
这个设计确保了select方法的阻塞时间是根据下一次定时任务的到期时间来动态调整的,这样可以在保证I/O事件得到及时处理的同时,也能按时执行定时任务。
nio空轮询bug在哪里体现,Netty如何解决的?
NIO(New I/O)的“空轮询”Bug是指在某些操作系统和JDK版本中,Selector可能会错误地唤醒,即使没有实际的I/O事件发生,这会导致CPU 100%的问题。这个问题通常发生在Linux系统上,尤其是在Epoll模式下,且在使用old-style (poll(2)) epoll events的Linux内核版本中。
在Netty中,这个问题体现为EventLoop线程会不断地被唤醒,即使没有新的I/O事件需要处理,从而导致不必要的CPU消耗。
Netty解决这个问题的方法是使用一个称为“时间轮询检测”的机制。Netty会记录连续的空轮询次数,当空轮询次数达到一个阈值时,它会重建Selector,这样就可以避免这个问题。重建Selector意味着创建一个新的Selector实例,并将所有的通道注册到新的Selector上。
以下是Netty中处理空轮询的简化代码片段:
int selectCnt = 0;
for (;;) {selectCnt++;int selectedKeys = selector.select(timeoutMillis);if (selectedKeys != 0 || oldWakenUp || wakenUp.get() || hasTasks()) {// 处理就绪的I/O事件}if (selectCnt >= SELECTOR_AUTO_REBUILD_THRESHOLD) {// 重建Selectorselector = selectRebuildSelector(selector);selectCnt = 0;}
}
ioRatio控制什么,设置为100有什么作用
ioRatio是一个用于控制I/O操作和非I/O任务执行时间的比例的参数。这个参数是在EventLoop中设置的,用于调整在事件循环中处理I/O事件和执行非I/O任务的时间比例。
ioRatio的值是一个百分比,表示在事件循环的一次迭代中,用于处理I/O事件的最大时间比例。例如,如果ioRatio设置为50,那么在每次事件循环迭代中,Netty会尽量保证至少50%的时间用于处理I/O事件,而剩余的50%的时间用于执行非I/O任务。

阅读上面的源码我们可以看到runAllTasks(ioTime * (100 - ioRatio) / ioRatio),通过ioRatio控制非io事件的执行时间。
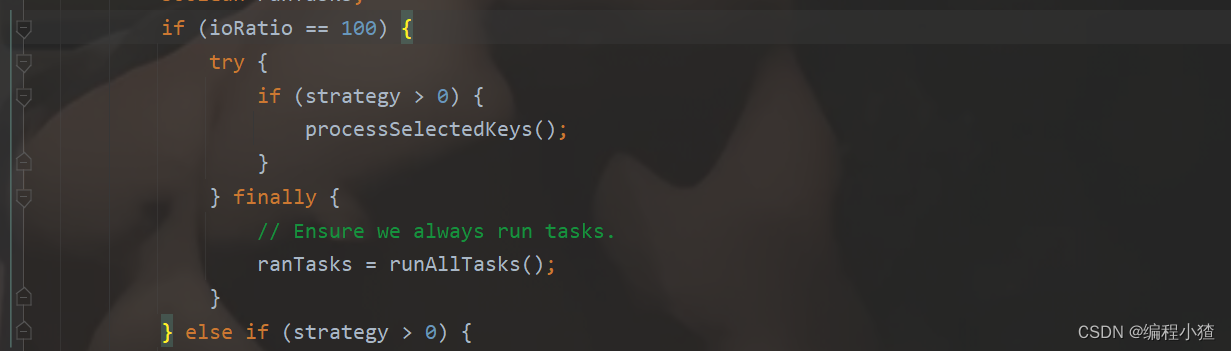
如果ioRatio设置为100,那么Netty将不会限制非I/O任务的执行时间。这意味着在每次事件循环迭代中,Netty会尽可能快地执行所有的非I/O任务,而不会根据ioRatio来调整I/O事件处理时间。
Netty中对selectKeys优化是怎么回事
Netty中对selectedKeys的优化主要是针对Java NIO中Selector的selectedKeys()方法返回的SelectionKey集合的性能问题。在Java NIO中,每次调用Selector的select()方法后,都需要处理selectedKeys()方法返回的集合中的每个SelectionKey,以确定哪些通道准备进行I/O操作。
在早期的Java版本中,selectedKeys()返回的集合是HashSet,这意味着每次调用selectedKeys()都会创建一个新的集合实例,并且在处理完选中的键后,需要手动清除已处理的键,以避免在下次选择操作时重复处理。这种操作方式在性能上是有开销的,尤其是在高负载下,频繁的集合创建和清除操作会显著影响性能。
Netty为了优化这一过程,采取了以下措施:
-
使用优化的集合:Netty使用了一个自定义的集合
SelectedSelectionKeySet来替代JDK默认的HashSet。这个集合是一个数组,它避免了HashSet的性能开销,并且可以更快地遍历选中的键。 -
避免不必要的集合创建:Netty通过反射的方式将
Selector的selectedKeys和publicSelectedKeys字段替换为自定义的SelectedSelectionKeySet实例,这样在每次调用select()方法后,不需要创建新的集合实例。 -
清除已处理键的优化:由于
SelectedSelectionKeySet是专门为Netty的用途设计的,它可以在处理完选中的键后自动清除,无需手动操作,这进一步减少了性能开销。
以下是Netty中相关优化的简化代码示例:
if (selectedKeys != null && !selectedKeys.isEmpty()) {for (Iterator<SelectionKey> i = selectedKeys.iterator(); i.hasNext(); ) {SelectionKey k = i.next();// 处理选中的键processSelectedKey(k);i.remove();}
}
在这个示例中,selectedKeys是SelectedSelectionKeySet的实例,它在迭代过程中会自动清除已处理的键,这样在下一次select()调用时,就不会重复处理这些键。
通过这些优化,Netty显著提高了在高负载下处理selectedKeys的性能,减少了内存分配和垃圾收集的压力,从而提高了整个网络应用框架的性能和可扩展性。
这篇关于Netty源码分析二NioEventLoop 剖析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






