本文主要是介绍关于Speech processing Universal PERformance Benchmark (SUPERB)基准测试及衍生版本,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Speech processing Universal PERformance Benchmark (SUPERB)是由台湾大学、麻省理工大学,卡耐基梅隆大学和 Meta 公司联合提出的评测数据集,其中包含了13项语音理解任务,旨在全面评估模型在语音处理领域的表现。这些任务涵盖了语音信号的各个方面,包括语言学、说话人、韵律和语义元素。
具体来说,SUPERB包含以下13项任务:Speaker Identification(说话人识别)、Automatic Speaker Verification(说话人验证)、Speaker Diarization(说话人日志)、Phoneme Recognition(音素识别)、Automatic Speech Recognition(语音识别)、Keyword Spotting(关键词检测)、Query by Example Spoken Term Detection(QbE)、Intent Classification(意图分类)、Slot Filling(对话理解槽填充)、Emotion Recognition(情绪识别)、Speech Separation(语音分离)、Speech Enhancement(语音增强)和 Speech Translation(语音翻译)。
1、衍生版本
SUPERB-SG是SUPERB的一个扩展,它专注于评估预训练模型在语义和生成能力方面的表现,通过增加任务多样性和难度来实现这一点。这表明,通过使用轻量级方法,可以测试预训练模型在不同类型的任务中的表现,这些任务涵盖了从数据域和质量的变化。
ML-SUPERB是SUPERB的一个多语言版本,它覆盖了154种语言,并考虑到自动语音识别和语言识别,而不是仅限于英语。这表明,尽管多语言模型通常不比单一语言模型表现得更好,但在某些任务上,它们仍然可以提供有用的表示。
Dynamic-SuperB则是一个动态、协作和综合指导调整的基准,旨在构建能够利用指令调整执行多个任务的通用语音模型。这个基准通过结合33个任务和22个数据集来实现,覆盖了广泛的语音任务,并提出了几种方法来建立基准基线。
2、评估指标
Phoneme Recognition (PR) - 评估指标是电话错误率(Phone Error Rate, PER),旨在将话语转录为最小的内容单元。
Automatic Speech Recognition (ASR) - 评估指标是词错误率(Word Error Rate, WER),目的是将话语转录为单词。
Keyword Spotting (KS) - 评估指标是准确率(Accuracy, ACC),任务是检测预注册的关键词。
Query by Example Spoken Term Detection (QbE) - 评估指标是最大术语加权值(Maximum Term Weighted Value, MTWV),用于在音频数据库中通过二进制区分查询和文档是否匹配。
Speaker Identification (SID) - 评估指标是准确率(Accuracy, ACC),任务是将话语分类为其说话者身份的多类分类。
Automatic Speaker Verification (ASV) - 评估指标是等错误率(Equal Error Rate, EER),验证一对话语的说话者是否匹配。
Speaker Diarization (SD) - 评估指标是分诊错误率(Diarization Error Rate, DER),预测每个时间戳的说话者。
Intent Classification (IC) - 评估指标是准确率(Accuracy, ACC),将话语分类为预定义的类别以确定说话者的意图。
Slot Filling (SF) - 评估指标包括槽类型F1分数和槽值字符错误率(Character Error Rate, CER),从话语中预测一系列语义槽类型。
Emotion Recognition (ER) - 评估指标是准确率(Accuracy, ACC),预测每个话语的情绪类别。
3、SUPERB-SG-专注于更难的语义和生成任务
3.1 SUPERB-SG中新增加的任务
3.1.1 Speech Translation
语音翻译(ST)用它来评估SSL模型的语义能力,并且研究它们如何提升翻译任务的能力。我们使用CoVoST En → De作为训练集,并按照官方的切分方法分为训练集、测试集和验证集,同时删除所有含有"REMOVE"的样本,其训练集、验证集和测试集分别包括425.8小时、25.9小时和24.5小时的数据。对于文本,我们保持原始的大小写、规范化标点符号,并建立具有100%训练集覆盖率的字符语料库。我们使用sacreBLEU作为评价标准,它是一个大小写敏感且去符号化的BLEU。我们的下游模型使用一个三层Transformer的编码器-解码器架构,每层的隐藏维度为512。并且还使用了一个卷积子采样器(convolutional subsampler)来减少输入的序列长度,然后再将其送入编码器。我们使用0.1的概率对我们的模型进行标签平滑的训练。
3.1.2 Out-of-Domain ASR
虽然SUPERB中包含了ASR,但它只在英语语料库LibriSpeech上检验了SSL模型。因此,我们引入了域外ASR(OOD-ASR),旨在评估模型的跨语言能力,以及域外场景。OOD-ASR任务被分为跨语言任务(cross-lingual task)和自发语音任务(spontaneous speech task)。对于跨语言任务,我们从Common Voice 7.0中选取墨西哥西班牙语(es)、普通话(zh)和阿拉伯语(ar)子集,其分别包含21.5、31.2和30.7小时的训练数据,1.2小时、14.4小时和12.24小时大小的验证数据,0.6小时、15.3小时和12.5小时大小的测试数据。对于自发语音任务(spon),我们使用了Santa Barbara Corpus of Spoken American English (SBCSAE) ,其中包括60个不同主题的对话,16.7小时的数据。验证和测试集的大小分别为1.6小时和2.2小时。除普通话使用字符错误率(CER)作为标准之外,其余任务我们使用单词错误率(WER)作为衡量标准。错误率是所有子任务错误率的平均数。ASR模型是一个2层的BLSTM,其隐藏状态维度为1024。训练目标是CTC(Connectionist Temporal Classification)损失。在推理过程中,我们使用CTC贪婪解码,不对语言模型进行重新评分,来简化过程并突出所学到的声学表征的影响。
3.1.3 Voice Conversion
对于语音转换(VC),我们考虑在任意对一(A2O)设置下的VCC2020的内语言VC任务。A2O VC的目的是将任意说话人的语音转换成预定的目标说话人的语音。我们用这个任务来评估说话人的可转移性以及SSL模型的可推广性。我们使用目标说话人的60个时间跨度为5分钟的语料用于训练,25个时间跨度为2分钟的语料用于测试,没有使用验证集。我们使用常用的MCD(mel-cepstrum distortion)、单词错误率(WER)和来自现成的ASR和ASV模型的声纹识别(ASV)接受率作为评价指标。下游模型依赖目标说话人的方式从上游表征中重构声学特征。在转换阶段,将上游提取的表征作为输入,由模型生成转换后的声学特征,然后将其发送到神经声码器合成转换后的波形。我们采用Tacotron2作为下游模型,Tacotron2是一个由卷积层和LSTM层组成的自回归网络。使用Hifi-GAN作为神经声码器。
3.1.4 Speech Separation
语音分离(SS)是将目标语音从背景干扰中分离出来。它是语音处理中的一个重要步骤,尤其是对于嘈杂和多语者的场景十分重要。我们在一个由LibriSpeech和WHAM!噪声模拟的数据集上研究语音分离问题。我们使用包含2个发言人的16kHz版本的数据集,并专注于mix_clean条件。训练和评估集包含43.3和4.2小时的模拟语音,这些语音来自LibriSpeech的train-clean-100和test-clean。这个任务是用来评估SSL模型在输入为混合声学信号时的生成能力。我们使用标度不变的信号失真率改善情况(SI-SDRi)作为评价指标。对于下游模型,我们了使用3层的BLSTM模型,每个方向的维度为896,来预测每个说话人的短时傅里叶变换(STFT)掩码,并使用反短时傅里叶变换(iSTFT)将预测结果转换回时域。并且进行了PIT(Permutation invariant training),以优化预测掩码和理想非负相位敏感掩码(INPSM)之间的均方误差。由于跨度大小的限制和计算成本,我们选择了频域方法而不是基于时域的方法。
3.1.5 Speech Enhancement
语音增强(SE)是指从退化的语音信号中去除背景噪声的任务,其目的是提高信号的感知质量和可懂度。我们使用这个任务评估模型在嘈杂条件下的生成能力。训练、验证和测试集分别包含8.8、0.6和0.6小时的语音。评估指标为语音质量感知评估(PESQ)和短时客观可懂度(STOI)。一个类似于语音分离任务的3层BLSTM模型被训练来预测干净信号的光谱掩码。预测的掩码和INPSM之间的均方误差被作为目标。
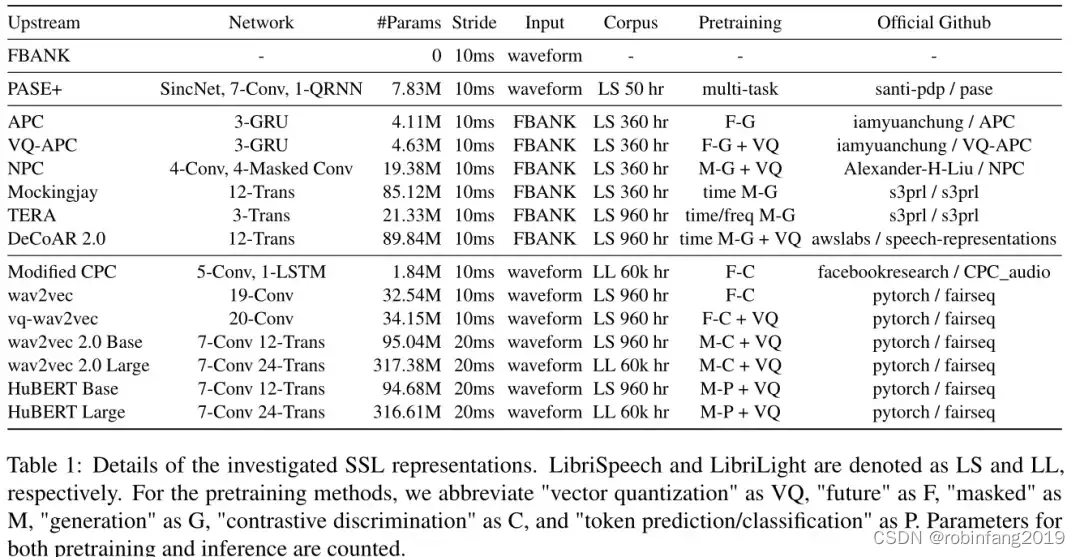
3.2 15个上游模型基本属性
15个上游模型有着不同的架构、规模和学习目标。一些模型还使用了矢量量化,这有一个额外的好处,就是信号压缩。下图展示了上游模型的详细属性。
4、ML-SUPERB-支持多语言语音处理
SUPERB通过其多语言版本ML-SUPERB支持多语言语音处理。ML-SUPERB是一个扩展的基准测试,旨在评估跨语言语音表示学习的能力。这个挑战赛包括了54个语言数据集,涵盖了154种语言。这表明SUPERB能够支持广泛的语言范围,从而使得研究人员可以在多种语言环境下比较不同语音相关任务的性能。
总结来说,SUPERB通过其多语言版本ML-SUPERB支持包括英语、法语、德语、阿拉伯语、中文以及其他154种语言在内的多语言语音处理。
更多信息可以参考官网:https://multilingual.superbbenchmark.org/
5、Dynamic-SUPERB-支持多语言语音处理
Dynamic-SUPERB是一个动态的协作基准测试,旨在构建通用语音模型,能够利用指令调整以零触发的方式执行多项任务。它为研究人员和开发人员提供了一个平台来评估和比较各种语音处理任务中的不同模型。
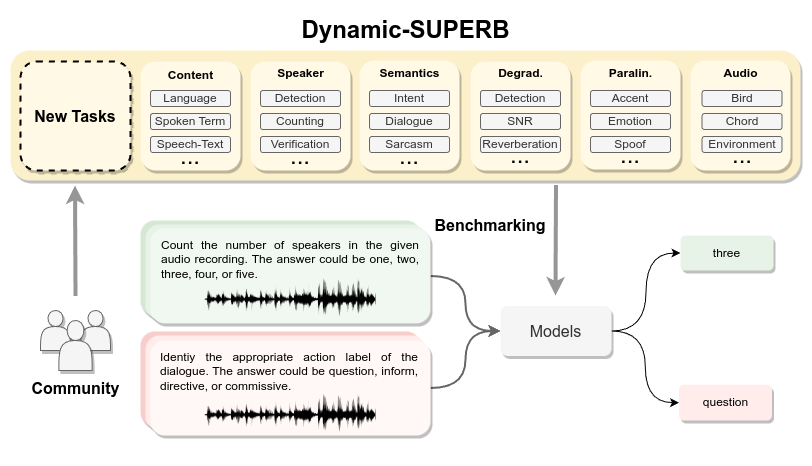
官方仓库包含了55个评估实例,这些实例是通过结合33个任务和22个数据集创建的,涵盖了广泛的维度,为评估提供了全面的平台。
下载地址:https://github.com/dynamic-superb/dynamic-superb
这篇关于关于Speech processing Universal PERformance Benchmark (SUPERB)基准测试及衍生版本的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







