本文主要是介绍从头理解transformer,注意力机制(上),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深入理解注意力机制和Transformer架构,及其在NLP和其他领域的突破。
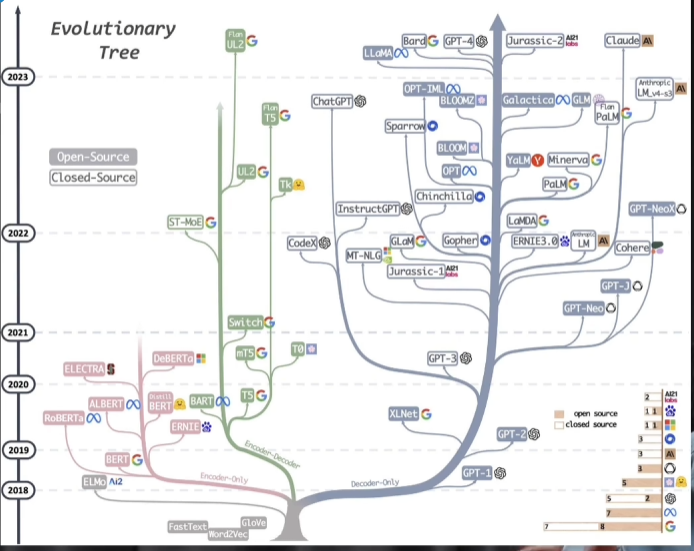
要想理解transformer,先从编码器解码器结构开始理解
基于transformer发展起来的llm
右边:只有解码器,强项是生成内容
左边:只有编码器,强项是学习和理解语言的内容
编码和解码的码究竟是什么码
图像领域 CNN
文字领域 RNN
从数学角度看,transformer和RNN是一致的,和CNN也是一致的
transformer和RNN从结构上都保留了编码和解码结构
码就是把语言中符号发音等形式不同剥离后的语义关系
编码的两个标准
1.可以数字化
2.数字化的数值可以体现语义之间的相对关系
tokenizer标记器(分词器)和one hot 独热编码
作用都是对最基础的语义单元token进行数字化
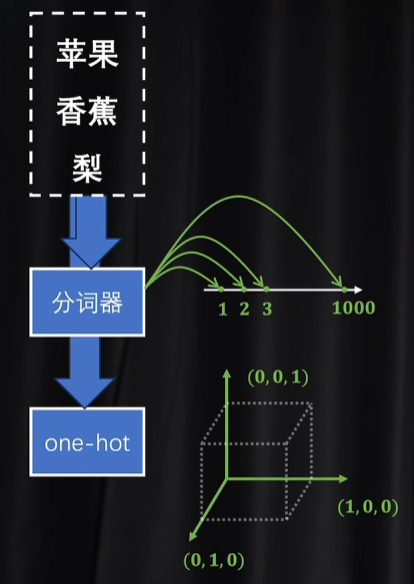
标记器和独热编码都能很好达到第一个标准,但第二个标准会出现问题
-
标记器信息密度过高 一维
-
独热编码密度过低 高维
潜空间
所以找一个维度高,但是又没那么高的空间,协助完成编码和解码的工作。他就是一个纯粹的语义空间
有两个方向
- 基于分词后的ID去升维
- 基于独热编码降维、
显然降维是更易操作的。这里会用到向量和矩阵相乘的相关知识 https://blog.csdn.net/qq_36372352/article/details/138669909?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22138669909%22%2C%22source%22%3A%22qq_36372352%22%7D以及神经网络与空间变换的关系https://blog.csdn.net/qq_36372352/article/details/138671246?csdn_share_tail=%7B%22type%22%3A%22blog%22%2C%22rType%22%3A%22article%22%2C%22rId%22%3A%22138671246%22%2C%22source%22%3A%22qq_36372352%22%7D
词嵌入embedding
编码就是先把一个文本里的token都先编成独热码,然后进行降维,相当于是把输入额一句话根据语义投射到一个潜空间中,把高维空间对象投射到低维空间
使用矩阵乘法实现embedding,所以把token投入到潜空间的矩阵叫做嵌入矩阵。
一个token被嵌入以后,就变成了多维的向量,每一个维度都代表一个独立的基础语义
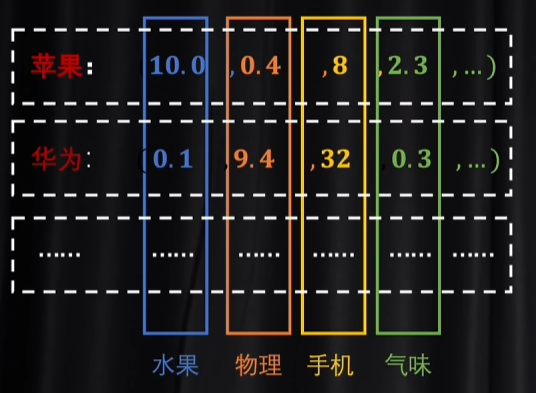
这个token具体的语义是什么要看各个维度分配的值是多少
Word2Vec
像是编词典,里面不需要激活函数,因为只涉及向量求和与向量分解,计算起来更简单。生成的潜空间就是用其他词向量合成目标词向量。只是提供了一个对语义的最初理解,体现了单个token之间的联系。这个潜空间里面词向量对应的词意不依赖作者主观意图。
不同词和不同顺序体现了主观性,这就需要注意力机制了
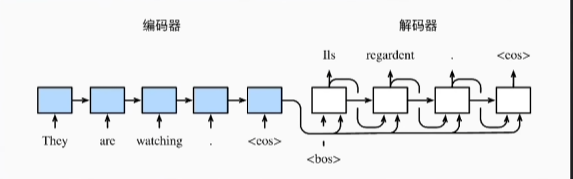
编码和解码原理:
token经过矩阵编码位词向量,词向量可以解码回token
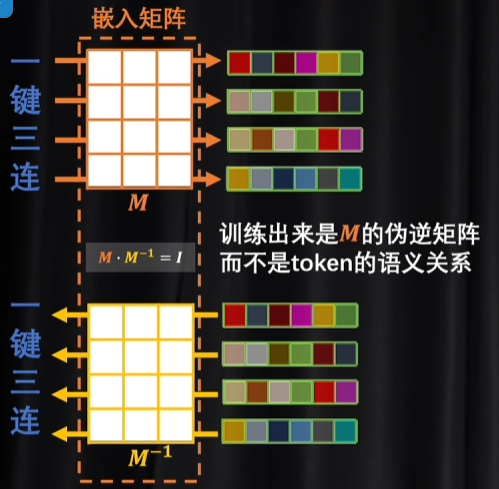
但采取这种形式是不能训练的
训练有两种方式
CBOW
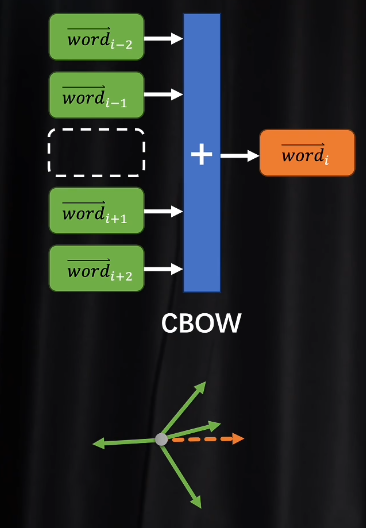
准备奇数个token,拿掉一个,剩下的分别给同一个嵌入矩阵相乘,把他们变成词向量之后,再把四个向量加在一起合成一个向量.再对和向量进行解码,损失函数会定量去看,和向量解码后得到的token和挖掉的中间token是不是一样的。如果不一样需要修改参数.
目的是训练出体现语义的嵌入矩阵
skip-gram
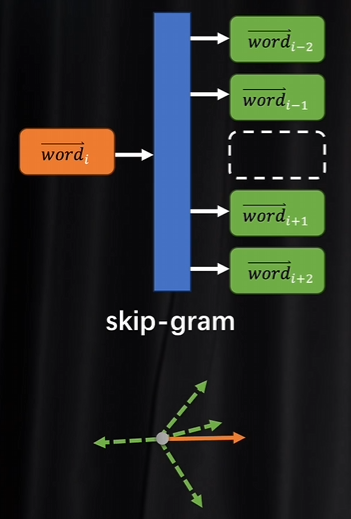
与CBOW反过来,已知一个token根据他的词向量求出上下文对应的token分量 ,看是不是和训练数据一致
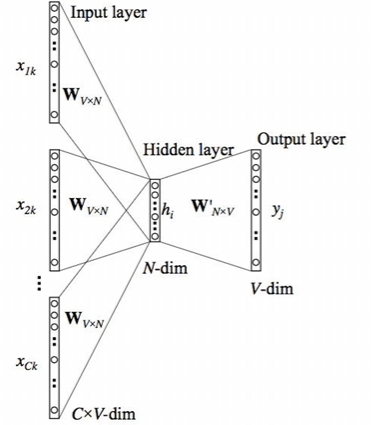
这两种方法可以自监督学习,不需要人为打标签,只要给文本就可以用文本自己挖掉一些空自己训练
注意力
transformer架构
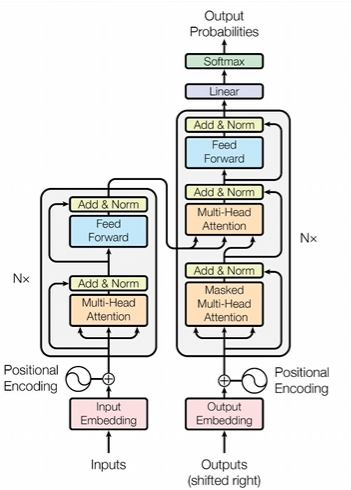
现在的各大模型都是为了适应各种需求对他进行了各种变化和优化
把词和词组合后的语义进行理解,靠的就是注意力机制,图中的multi-head attention
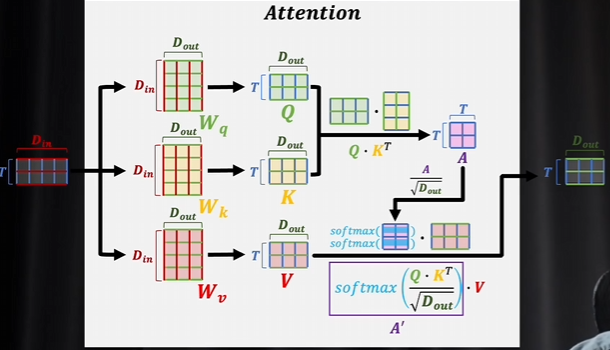
一组词向量经过三个矩阵相乘以后,分别得到Q,K, V三个矩阵,再进行运算最后还是会输出一组词向量。词嵌入已经解决了单个词的语义问题,
输入一组词向量,词向量组成了数据矩阵,输入的是t行的矩阵, 输出也是t行矩阵,输出的列数是一个词向量上它的维度的个数。
Wq,Wk,Wv这三个矩阵按照注意力机制的要求,输入的词向量矩阵都需要先和这三个矩阵相乘之后,才会得到QKV 。
Dout决定了输出的词向量是多少列,也就是多少维度。
注意力机制最值得关注的是得到QKV之后的操作
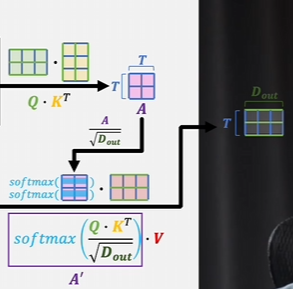
- 先把K进行转置,然后让Q和K的转置相乘,也可以是Q转置和K相乘,会得到一个T行T列的矩阵A,A被称作注意力得分
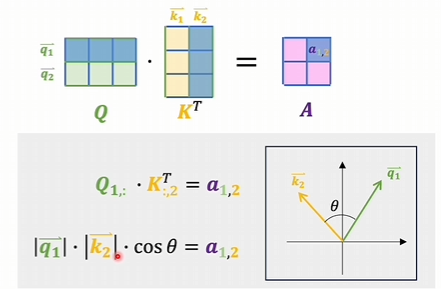
向量内积a12的大小某种程度能体现出q1和k2两个向量的关系,也就是说Q和K的转置相乘存在A里的数值代表这两组向量他们互相之间的关系是大还是小
每一个词向量都要和包括自己在内的所有其他词向量进行内积运算,如果是垂直他们之间无关。
- 对A的每一项进行缩放,除以根号下Dout,让这些数值尽量分散一点,而不是集中在0和1的饱和区。为什么要除是从概率分布考虑的
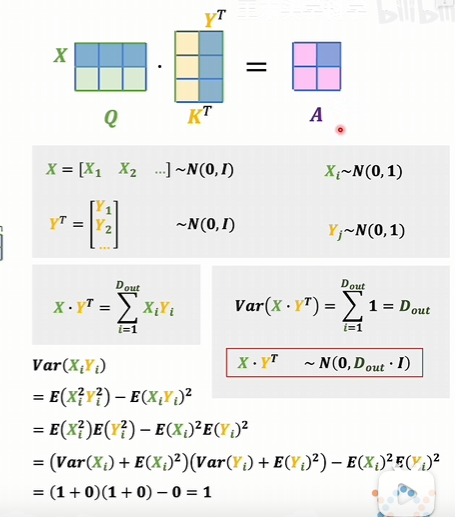
每一项都除以根号Dout,方差就又变成1,A里面每一项又变成标准正态分布了
-
按行计算softmax,得到按行归一的注意力得分A’,再和V进行矩阵相乘。V其实就是表示从词典里查出的token的客观语义,A‘相当于是因为上下文关联而产生的修改系数
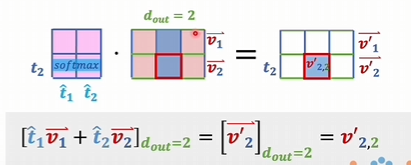
能对v22’产生影响的 是所有词向量的一个维度。
总结:
Q和K是得到了这一组词向量自己和自己之间的相互关系,再用这个相互关系来修正词向量,让词向量的每一个维度都能得到修正,和V相比,这里修正之后得到的词向量,都会根据上下文进行修正,这些词向量,除了词典里那个客观的语义外,还会根据上下文对语义本身进行一些校准
而以上也就为一句话一段话多个词向量叠在一起这些内容增加了主观性,让你说的话和我说的话可以表达不同意思
这些计算的意义
在没有使用注意力机制之前,词向量虽然具备了词意,词意是字典里的词意,客观词意
当按自己想法将客观词意按不同顺序组合到一起以后,就变成了表达不同语义的文章了,这个时候具备了主观性
注意力需要识别出那些因为上下文关联,而对词典中客观的语义进行调整和改变的幅度。
这篇关于从头理解transformer,注意力机制(上)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




