本文主要是介绍深度学习之前馈神经网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.导入常用工具包
#在终端中输入以下命令就可以安装工具包
pip install numpy
pip install pandas
Pip install matplotlib
注:
numpy是科学计算基础包
pandas能方便处理结构化数据和函数
matplotlib主要用于绘制图表。
#导包的代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2.导入数据集
2.1.数据集的下载与转换
数据集下载地址:http://yann.lecun.com/exdb/mnist/

注:下载这四个文件,但由于不是csv的格式,所以我们要将这四个文件转换成csv格式。
import struct
import numpy as np
import pandas as pd#以二进制读取模式。struct.unpack('>IIII', f.read(16))从文件中读取前16个字节,并按照大端字节序解析出魔数、图像数量、行数和列数。
def read_mnist_image(filename):with open(filename, 'rb') as f:magic_number, num_images, num_rows, num_cols = struct.unpack('>IIII', f.read(16))image_data = np.fromfile(f, dtype=np.uint8).reshape(num_images, num_rows * num_cols)return image_data#读取MNIST数据集中的标签数据。与读取图像数据类似,它打开文件,解析魔数和标签数量,然后读取剩余的数据,将其转换为NumPy数组。
def read_mnist_labels(filename):with open(filename, 'rb') as f:magic_number, num_labels = struct.unpack('>II', f.read(8))label_data = np.fromfile(f, dtype=np.uint8)return label_data# 读取图像和标签文件
image_filename = 'train-images.idx3-ubyte'
label_filename = 'train-labels.idx1-ubyte'
images = read_mnist_image(image_filename)
labels = read_mnist_labels(label_filename)# 将图像和标签合并为一个DataFrame
train_Data = pd.DataFrame(images)
train_Data['label'] = labels# 保存为CSV文件
train_Data.to_csv('mnist_train.csv', index=False)# 对测试数据进行相同的操作
image_filename = 't10k-images.idx3-ubyte'
label_filename = 't10k-labels.idx1-ubyte'
images = read_mnist_image(image_filename)
labels = read_mnist_labels(label_filename)
test_Data = pd.DataFrame(images)
test_Data['label'] = labels
test_Data.to_csv('mnist_test.csv', index=False)
数据集图片:

2.2.数据观察
import pandas as pd
train_Data = pd.read_csv('mnist_train.csv',header = None)
test_Data = pd.read_csv('mnist_test.csv',header = None)
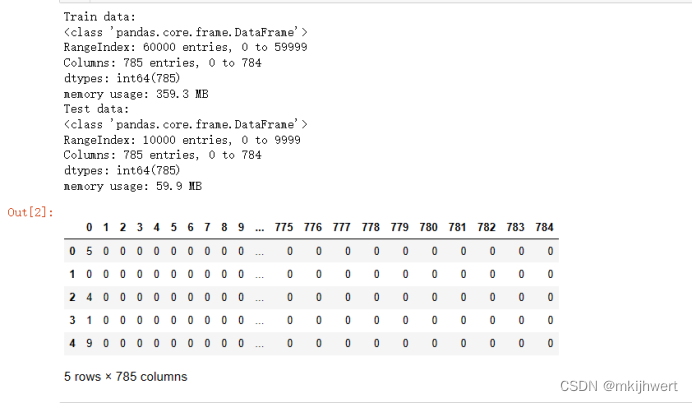
print("Train data:")
train_Data.info()
print("Test data:")
test_Data.info()
#继续观察训练数据前五行
train_Data.head(5)
注:可以发现训练数据中包含60000个数据样本,维度785,包括标签信息与784个特征维度;测试数据中包含10000个样本,维度785,包括标签信息与784个特征维度。
运行结果:
2.3.读取第一行数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
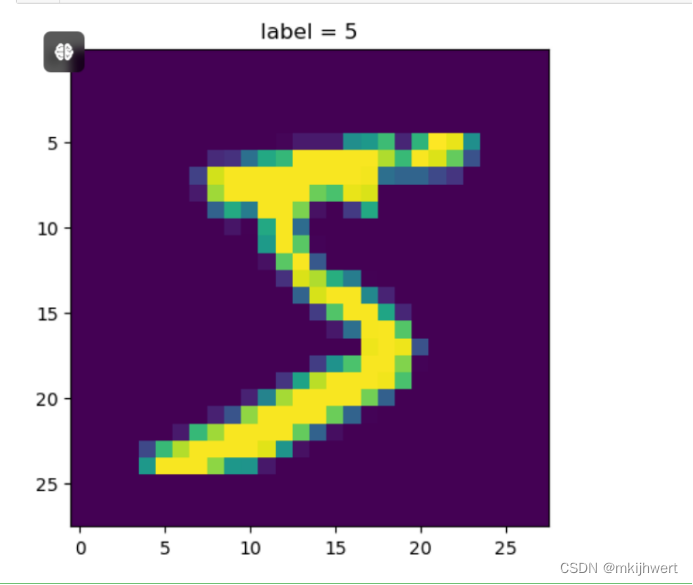
#取第一行数据
x = train_Data.iloc[0]
#标签信息
y = x[0]
#将1*784转换成28*28
img = x[1:].values.reshape(28,28)
#画图
plt.imshow(img)
plt.title('label = ' + str(y))
plt.show()
注:这段代码的主要作用是从训练数据集中取出第一行数据,将其中的图像数据转换为28x28的二维数组,并使用matplotlib库显示这个图像。同时,它还展示了图像对应的标签(即手写数字的类别)。
运行结果:
2.4.从sklearn中导入数据并观察
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
mnist.keys()
运行结果:

2.5.打印维度信息
data, label = mnist["data"], mnist["target"]
print("数据维度:", data.shape)
print("标签为度:", label.shape)
注:这段代码从之前使用fetch_openml函数获取的MNIST数据集字典中提取出图像数据(data)和标签(label),并打印它们的维度信息。
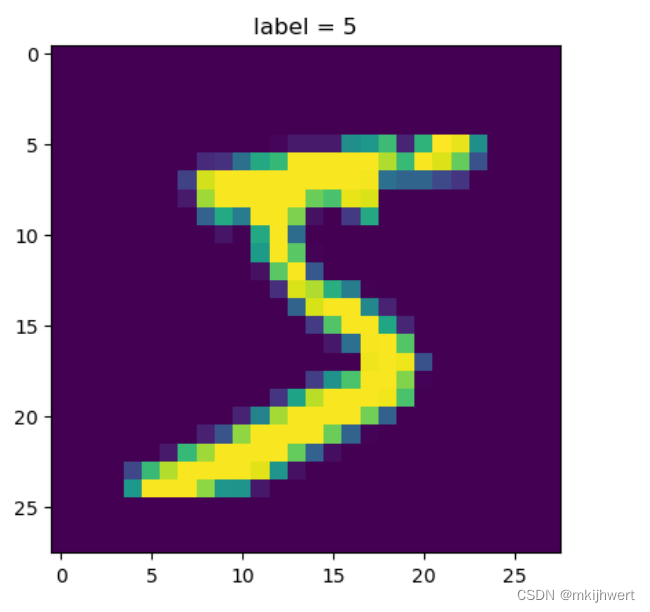
2.6.显示第一幅图像及其对应的标签
x = data.iloc[0]
y = label[0] #从label数组中取出第一个元素,即第一幅图像的标签
img = x.values.reshape(28,28)
plt.imshow(img)
plt.title('label = ' + str(y))
plt.show()
运行结果:
3.数据预处理
X = train_Data.iloc[:,1:].values#样本数据
y = train_Data.iloc[:,0].values#样本标签
print("数据X中最大值:",X.max())
print("数据X中最小值:",X.min())
运行结果:

3.1.对X进行归一化处理
#归一化
X = X/255
#此时将数值大小缩小在[0,1]范围内,重现观察数据中的最大、最小值
print("数据X中最大值:",X.max())
print("数据X中最小值:",X.min())
注:这段代码的目的是对数据集X进行归一化处理,并将处理后的数据范围缩放到[0, 1]之间。
运行结果:

3.2.分类
X_valid, X_train = X[:5000], X[5000:]
y_valid, y_train = y[:5000], y[5000:]X_test,y_test = test_Data.iloc[:,1:].values/255, test_Data.iloc[:,0].values
注:将数据集分割为训练集、验证集和测试集,并对这些数据集进行归一化处理。
4.前馈全连接神经网络(Sequential模型)
4.1.创建模型
import tensorflow as tf
from tensorflow import keras
model = keras.models.Sequential([keras.layers.Flatten(input_shape=[784]),#输入层784个神经元keras.layers.Dense(300, activation="relu"),#隐藏层300个神经元keras.layers.Dense(100, activation="relu"),#隐藏层100个神经元keras.layers.Dense(10, activation="softmax")#输入层10个神经元
])
model.layers[1]
weight_l,bias_l = model.layers[1].get_weights()
print(weight_l.shape)
print(bias_l.shape)
注:通过打印权重和偏置的形状,可以确认模型的第一个隐藏层是否正确地连接到输入层,并且可以了解该层的参数数量。这对于调试和理解模型的结构非常重要。在实际应用中,这些权重和偏置会在模型训练过程中通过反向传播算法自动调整,以最小化预测误差。
运行结果:

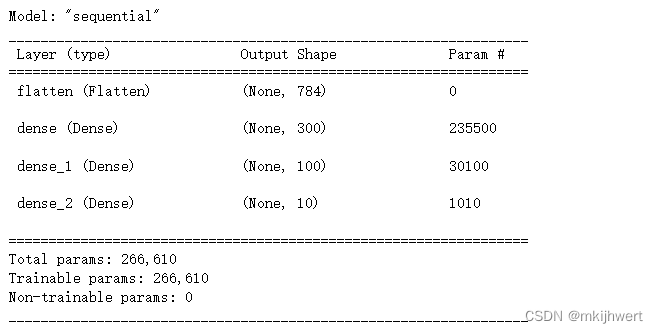
4.2.通过.summary()观察神经网络的整体情况
model.summary()
注:model.summary()是Keras模型的一个方法,它用于打印出模型的概述信息。
运行结果:
4.3.训练网格
#编译网络
model.compile(loss="sparse_categorical_crossentropy",optimizer="sgd",metrics=["accuracy"])
注:是Keras中的一个重要步骤,它用于编译刚刚创建的神经网络模型。编译过程定义了模型训练时需要使用的损失函数、优化器和评估指标。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
h = model.fit(X_train,y_train,batch_size=32,epochs=30,validation_data=(X_valid,y_valid))
注:epochs=30:训练过程中遍历整个训练数据集的次数。每个时期包含一次完整的训练数据遍历。
运行结果:

4.4.将Keras的History对象转换为Pandas的DataFrame
pd.DataFrame(h.history)
注:h.history属性是一个字典,其中包含了训练过程中的损失值和评估指标值。
运行结果:

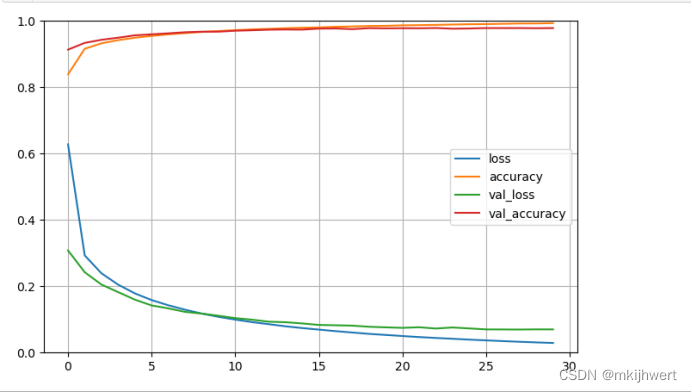
4.5.绘图
#绘图
pd.DataFrame(h.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)#set the vertical range to [0-1]
plt.show()
注:
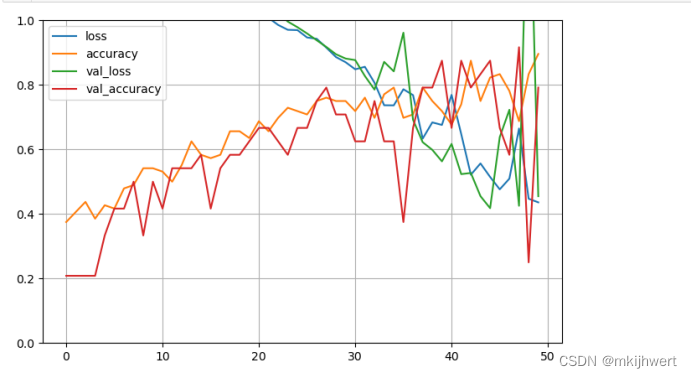
Loss(损失):损失函数的值越低,表示模型的预测越接近实际值。
Accuracy(准确率):准确率是指模型正确预测的样本数与总样本数之间的比例。
Val Loss(验证损失):如果训练损失持续下降,但验证损失开始上升,这可能表明模型出现了过拟合。
Val Accuracy(验证准确率):用于评估模型的泛化能力,并且是模型性能的一个重要指标。
运行结果:
4.6.识别准确率
model.evaluate(X_test, y_test, batch_size = 1)
注:使用Keras模型的evaluate方法来评估模型在测试集上的性能。evaluate方法会计算并返回模型在给定测试数据上的损失和评估指标。
运行结果:
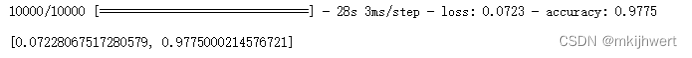
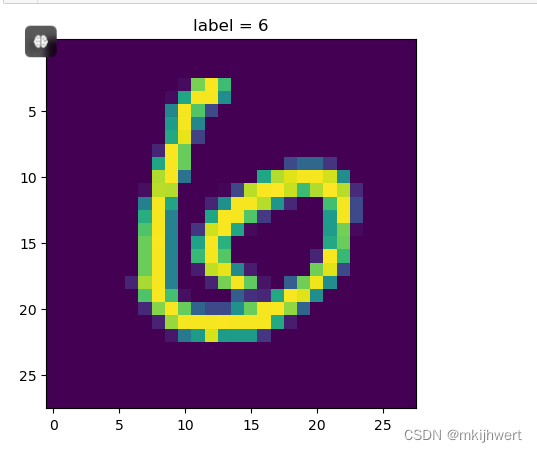
4.7.对样本进行预测
x_sample, y_sample = X_test[11:12], y_test[11]
y_prob = model.predict(x_sample).round(2)
y_probimg = x_sample.reshape(28,28)
plt.imshow(img)
plt.title('label = ' + str(np.argmax(y_prob)))
plt.show()
注:从测试数据集中选取索引为11的单个样本,并将其特征和标签分别存储在x_sample和y_sample中。这里使用切片[11:12]来确保x_sample是一个二维数组,符合模型的输入要求。
运行结果:
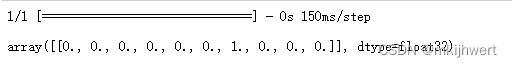
5.使用Sequential()方法,对鸢尾花数据集进行分类
5.1划分
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitiris = load_iris() #鸢尾花数据集x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=23)X_train,X_valid,y_train,y_valid = train_test_split(x_train,y_train,test_size=0.2,random_state=12)print(X_valid.shape)
print(X_train.shape)
注:从Scikit-learn的model_selection模块中导入train_test_split函数,用于分割数据集。
运行结果:

5.2. 构建模型
import tensorflow as tf
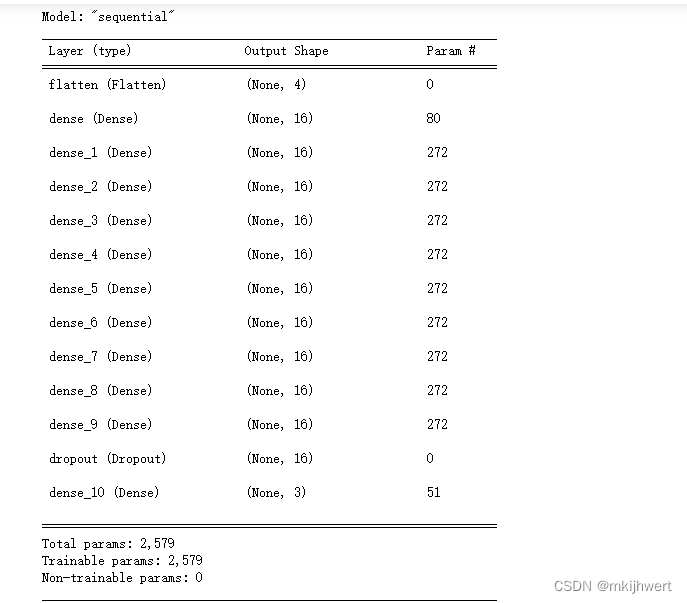
from tensorflow import kerasmodel = keras.models.Sequential([keras.layers.Flatten(input_shape=[4]),keras.layers.Dense(16,activation='relu'),keras.layers.Dense(16,activation='relu'),keras.layers.Dense(16,activation='relu'),keras.layers.Dense(16,activation='relu'),keras.layers.Dense(16,activation='relu'),keras.layers.Dense(16,activation='relu'),keras.layers.Dense(16,activation='relu'),keras.layers.Dense(16,activation='relu'),keras.layers.Dense(16,activation='relu'),keras.layers.Dense(16,activation='relu'),keras.layers.Dropout(rate=0.2),keras.layers.Dense(3,activation='softmax'),
])model.summary()
注:这段代码使用TensorFlow和Keras库创建了一个神经网络模型,用于分类鸢尾花数据集。模型的结构是顺序的,包含了多个全连接层(Dense layers)和一个Dropout层。
运行结果:
5.3.提高准确率添加方式:keras.layers.Dropout(rate=0.2)
model.layers[1]
注:从之前定义的Keras模型中获取第二个层的对象。在Keras模型中,层是按照它们添加到模型中的顺序存储在一个列表中的,索引从0开始。因此,model.layers[1]将返回模型中第一个隐藏层的对象。
weight_1,bias_1 = model.layers[1].get_weights()print(weight_1.shape)
print(bias_1.shape)
运行结果:

注:从之前定义的Keras模型中获取第一个隐藏层的权重和偏置,并打印它们的形状。
model.compile(loss='sparse_categorical_crossentropy',optimizer='sgd',metrics=["accuracy"])h = model.fit(X_train,y_train,batch_size=10,epochs=50,validation_data=(X_valid,y_valid))
注:optimizer=‘sgd’:这是模型训练时使用的优化器。sgd代表随机梯度下降(Stochastic Gradient Descent),它是一种简单的优化算法,用于在训练过程中更新模型的权重。
运行结果:

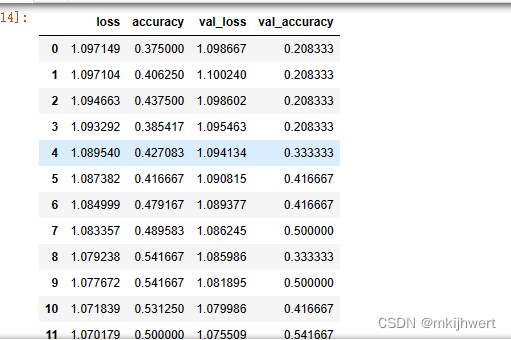
pd.DataFrame(h.history)
运行结果:
pd.DataFrame(h.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
运行结果:
model.evaluate(x_test,y_test,batch_size = 1)
注:
x_test:测试数据集的特征,通常是NumPy数组或TensorFlow张量。
y_test:测试数据集的标签,与x_test中的每个样本相对应。
batch_size = 1:评估过程中每次前向传播所使用的数据样本数量。
运行结果:

这篇关于深度学习之前馈神经网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





