本文主要是介绍LeNet-5上手敲代码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LeNet-5
LeNet-5由Yann LeCun在1998年提出,旨在解决手写数字识别问题,被认为是卷积神经网络的开创性工作之一。该网络是第一个被广泛应用于数字图像识别的神经网络之一,也是深度学习领域的里程碑之一。
LeNet-5的整体架构:
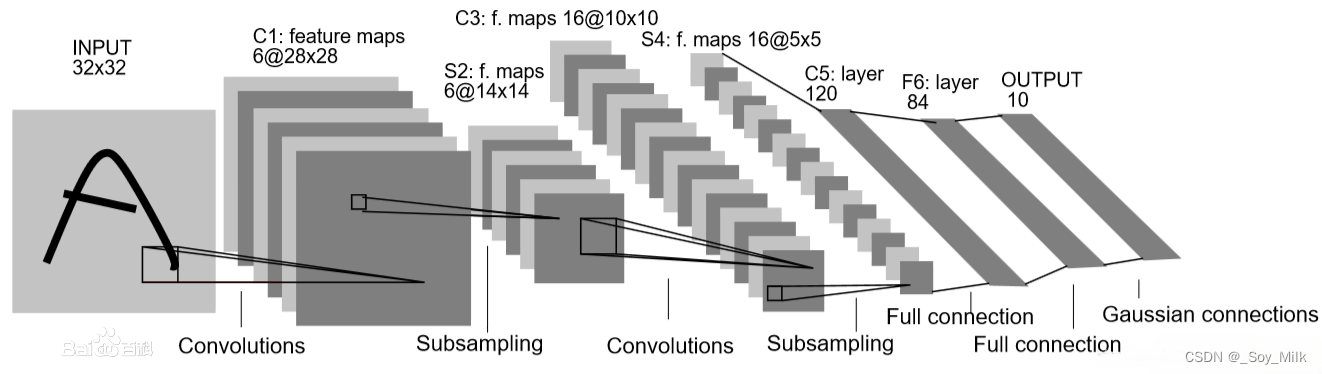
总体来看
LeNet-5由两个部分组成:
- 卷积编码器:由两个卷积层和两个下采样层组成;
- 全连接层密集块:由三个全连接层组成
特点:
1.相比MLP,LeNet使用了相对更少的参数,获得了更好的结果。
2.设计了MaxPool来提取特征
代码实现
1. 模型文件的实现
通过观察模型的整体架构,可以知到LeNet-5只用了三个基本的层——卷积层、下采样层、全连接层,因此我们很容易写出模型的基本框架。
其中
Gaussian connections也是一个全连接层。Gaussian Connections利用的是RBF函数(径向欧式距离函数),计算输入向量和参数向量之间的欧式距离。目前该方式基本已淘汰,取而代之的是Softmax。
为了提高模型的性能,我们会在卷积层与下采样层之间添加一个Relu激活函数,因此模型的整体流程架构为:
Convolutions->Relu->Subsampling->Convolutions->Relu->Subsampling->Full connection->Full connection->Full connection
在pytorch中,卷积层对应的是nn.Conv2d()方法, 下采样层可以使用pytorch中的最大池化下采样nn.MaxPool2d()方法来实现,全连接层可以使用nn.Linear()方法来实现。
确定参数:
卷积层:对于LeNet-5论文中输入的图片是 32 × 32 32 \times 32 32×32大小的图片(图片通道个数为3)。因此第一个卷积层的输入的通道个数为3,输出的通道个数为16,也就是说一共有16个卷积核。卷积核的个数等于通过卷积后图片的通道个数。
我们可以根据如下公式来计算出卷积核的大小。
计算卷积后图像宽和高的公式
I n p u t : ( N , C i n , H i n , W i n ) Input:(N, C_{in},H_{in},W_{in}) Input:(N,Cin,Hin,Win)
O u t p u t : ( N , C o u t , H o u t , W o u t ) Output:(N,C_{out},H_{out},W_{out}) Output:(N,Cout,Hout,Wout)
H o u t = [ H i n + 2 × p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] × ( k e r n e l _ s i z e [ 0 ] − 1 ) − 1 s t r i d e [ 0 ] + 1 ] H_{out} = [\frac{H_{in} + 2 \times padding[0] - dilation[0] \times (kernel\_size[0] - 1) - 1}{stride[0]} + 1] Hout=[stride[0]Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1+1]
W o u t = [ W i n + 2 × p a d d i n g [ 1 ] − d i l a t i o n [ 1 ] × ( k e r n e l _ s i z e [ 1 ] − 1 ) − 1 s t r i d e [ 1 ] + 1 ] W_{out} = [\frac{W_{in} + 2 \times padding[1] - dilation[1] \times (kernel\_size[1] - 1) - 1}{stride[1]} + 1] Wout=[stride[1]Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1+1]
公式中dilation我们没有使用,默认情况为1,输入的图片为 32 × 32 × 3 32 \times 32 \times 3 32×32×3输出为 28 × 28 × 6 28 \times 28 \times 6 28×28×6,通过公式,我们很容易算出 k e r n e l s i z e = ( 5 , 5 ) kernel_{size} = (5, 5) kernelsize=(5,5),【通常情况下如果通过卷积层后的图片的大小没有很明显的缩小(成倍数缩小),那么stride一般为默认值1】,通过以上公式,我们可以求得每一个卷积核的大小 。
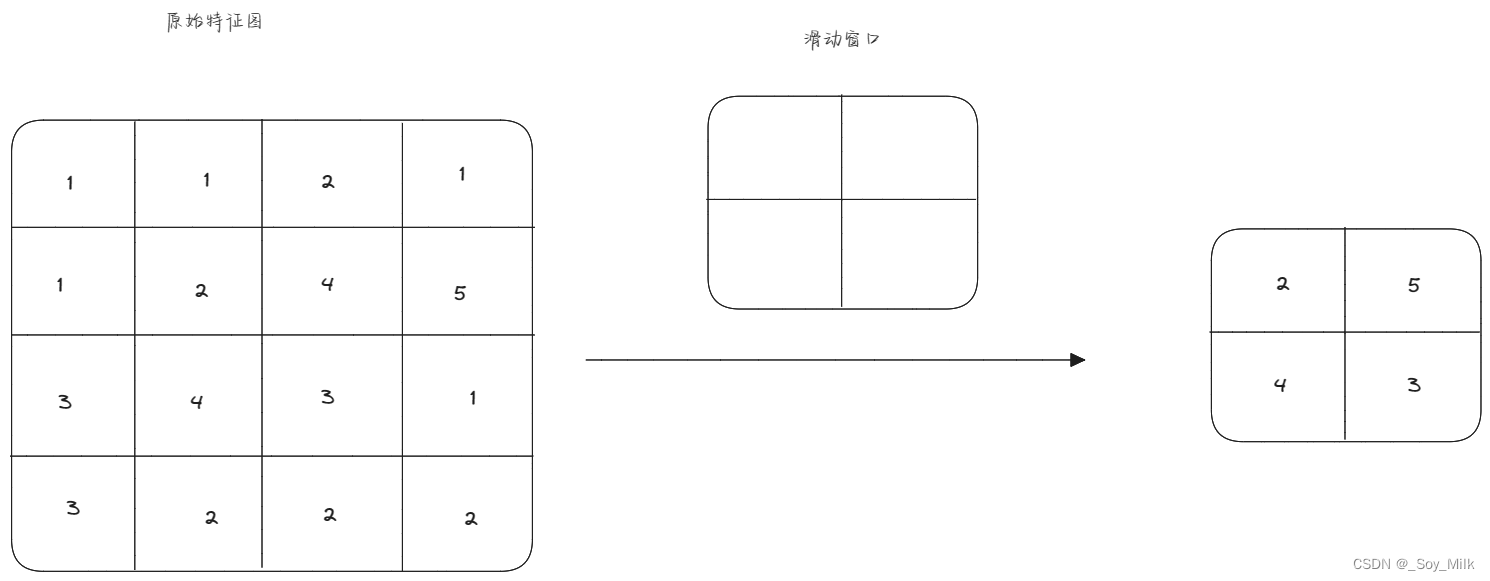
最大池化下采样:由于特征图通过最大池化下采样层之后,图片的大小变为原来的一半,因此我们知道在长度方向上每两个像素之间取一个最大值,这样才能将长度变为原来的一半,宽度方向上每两个像素之间取一个最大值,这样才能将宽度变为原来的一半。结合起来得到池化层的每一个滑动窗口的大小为 2 × 2 2 \times 2 2×2,也就是说,每四个像素取一个最大值。
全连接层:输入为上一个层的输出数据大小,输出为自定义大小,对于第一个全连接层,输入为下采样层的输出,即: 5 × 5 × 16 5 \times 5 \times 16 5×5×16 个矩阵值。输出为下一个全连接层单元的个数(第二个全连接层的单元个数为84个),可以推出所有全连接层的单元个数。
model.py
import torch
import torch.nn as nn
import torch.nn.functional as Fclass LeNet(nn.Module):def __init__(self):super(LeNet, self).__init__()self.conv1 = nn.Conv2d(3, 6, (5, 5))self.pool1 = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, (5, 5))self.pool2 = nn.MaxPool2d(2, 2)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = F.relu(self.conv1(x))x = self.pool1(x)x = F.relu(self.conv2(x))x = self.pool2(x)x = x.view(-1, 16 * 5 * 5) # 改变张量形状为一个二维张量,第一个维度是自动推断的,第二个维度设定为16 * 5 * 5x = self.fc1(x)x = self.fc2(x)x = self.fc3(x)return xif __name__ == '__main__':model = LeNet()x = torch.randn((3, 32, 32))output = model(x)print(x)
2. 训练程序
写训练程序的基本步骤为:
- 加载训练数据
- 初始化模型
- 设定损失函数
- 设定优化器
- 设定迭代次数
- 根据情况保存模型权重文件
训练数据我们使用的是CIFAR10中的训练数据,验证集的数据也使用的是CIFAR10中的数据,同时将训练集和验证集的数据进行转换(转换为tensor类型,进行归一化)。设置dataloader,训练集的batch_size为64,并且进行随机打乱,设置num_workers为2,验证集的batch_size为5000,进行随机打乱,设置num_workers为2。
num_workers:用于设置是否使用多线程读取数据,开启后会加快数据读取速度,但是会占用更多内存,内存较小的电脑可以设置为2或者0
训练数据时,我们在每次的500步之后进行一次验证,验证的方式为,加载验证集,然后输入到网络中进行预测,得到输出的最大值的索引,然后再与真实标签进行比较,统计为True的个数,然后除以所有的标签的个数,得到最后的模型的正确率。
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, test_label).sum().item() / test_label.size(0) # .item() 方法将结果转换为标量,即 Python 中的普通数字类型。
在迭代完所有的步数之后进行保存模型的权重文件。
train.py
import torch
import torchvision
from torch import nn, optim
from torch.utils.data import DataLoaderfrom model import LeNetdef main():device = torch.device("cuda" if torch.cuda.is_available() else "cpu")transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 训练集train_set = torchvision.datasets.CIFAR10(root="./data", train=True, download=False, transform=transform)train_loader = DataLoader(dataset=train_set, batch_size=64, shuffle=True, num_workers=2)# 验证集test_set = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transform)test_loader = DataLoader(dataset=test_set, batch_size=5000, shuffle=True, num_workers=0)# 实例化网络,损失函数,优化器net = LeNet().to(device)net.load_state_dict(torch.load('LeNet_200.pth')) # 加载权重loss_function = nn.CrossEntropyLoss().to(device)optimizer = optim.Adam(net.parameters(), lr=0.001)epochs = 200epoch = 0# 开始训练print("training...")while epoch <= epochs:epoch += 1running_loss = 0.0for step, data in enumerate(train_loader):print(f"epoc: {epoch}, step: {step}")inputs, lables = datainputs, lables = inputs.to(device), lables.to(device) # 将数据移动到GPU上optimizer.zero_grad()output = net(inputs)loss = loss_function(output, lables)loss.backward()optimizer.step()running_loss += loss.item()if step % 500 == 499: # 每500个batch_size之后进行验证一次with torch.no_grad():test_image, test_label = next(iter(test_loader)) # iter(test_loader)作用是设定一个迭代器,这行代码的作用是取出验证集中的一个batch_size的图片和对应的标签。test_image, test_label = test_image.to(device), test_label.to(device) # 将数据移动到 GPU 上outputs = net(test_image)predict_y = torch.max(outputs, dim=1)[1]accuracy = torch.eq(predict_y, test_label).sum().item() / test_label.size(0) # .item() 方法将结果转换为标量,即 Python 中的普通数字类型。print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %(epoch + 1, step + 1, running_loss / 500, accuracy))running_loss = 0.0print(f"The epoc is {epoch}")print("Finish Training")save_path = "./LeNet.pth"torch.save(net.state_dict(), save_path)if __name__ == '__main__':main()3. 验证程序
验证程序,首先需要加载图片,然后进行转换(包括裁剪为模型的输入形状大小【这里为 32 × 32 32 \times 32 32×32】,然后转换为tensor类型,最后进行归一化),将预处理后的图片送入到模型中,模型输出的是一个batch_size个一维向量,每一个一维向量有10个数,表示输出的类别一共有10个,取10个中值最大的数的索引作为预测的类别,可以使用以下代码:predict = torch.max(outputs, dim=1)[1].numpy(),这表示在模型输出的结果中,取第一个维度上的10个数取最大值的索引,并将其转换为numpy类型的数据。然后将这个数对照标签的映射关系,可以得到最终预测的类别。
varify.py
import torch
import torchvision.transforms as transforms
from PIL import Imagefrom model import LeNetdef main():transform = transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')net = LeNet()net.load_state_dict(torch.load('LeNet_250.pth'))im = Image.open('2.jpg') # 加载图片im = transform(im) # [C, H, W]im = torch.unsqueeze(im, dim=0) # [N, C, H, W]with torch.no_grad(): # 用于设置在该上下文中不进行梯度计算,因为推断时不需要计算梯度,可以提高计算效率。outputs = net(im)predict = torch.max(outputs, dim=1)[1].numpy()print(classes[int(predict)])if __name__ == '__main__':main()这篇关于LeNet-5上手敲代码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




