本文主要是介绍细说夜莺监控系统告警自愈机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
虽说监控系统最侧重的功能是指标采集、存储、分析、告警,为了能够快速恢复故障,告警自愈机制也是需要重点投入建设的,所有可以固化为脚本的应急预案都可以使用告警自愈机制来快速驱动。夜莺开源项目从 v7 版本开始内置了告警自愈模块,本文将详细介绍告警自愈的原理和实现。
夜莺项目介绍
夜莺监控是一款开源云原生观测分析工具,采用 All-in-One 的设计理念,集数据采集、可视化、监控告警、数据分析于一体,与云原生生态紧密集成,提供开箱即用的企业级监控分析和告警能力。夜莺于 2020 年 3 月 20 日,在 github 上发布 v1 版本,已累计迭代 100 多个版本。
夜莺最初由滴滴开发和开源,并于 2022 年 5 月 11 日,捐赠予中国计算机学会开源发展委员会(CCF ODC),为 CCF ODC 成立后接受捐赠的第一个开源项目。夜莺的核心研发团队,也是 Open-Falcon 项目原核心研发人员,从 2014 年(Open-Falcon 是 2014 年开源)算起来,也有 10 年了,只为把监控这个事情做好。
夜莺项目的 Github 地址是:GitHub - ccfos/nightingale: An all-in-one observability solution which aims to combine the advantages of Prometheus and Grafana. It manages alert rules and visualizes metrics, logs, traces in a beautiful web UI.,国内用这个开源项目的公司也比较多了,我就不过多介绍了。直接开始正题。
告警自愈原理
夜莺告警引擎在产生告警事件之后,除了可以通过多种通知媒介通知相关人员,也可以自动化的执行某个动作。主要是通过两种方式来驱动这些自动化动作:
- Webhook:通过 Webhook 的方式把告警事件推送到外部系统,外部系统可以根据告警事件的内容来执行相应的动作
- 脚本:直接到告警的机器上(或者指定的中控机)执行脚本,脚本可以是 shell 脚本、python 脚本、bat 脚本等等
本文重点讲解的是第二种,通过脚本的方式。
要能够去告警的机器上执行脚本,机器上需要部署一个 agent,这个 agent 周期性和服务端发起心跳,拉取要执行的脚本,并把脚本的执行结果上报给服务端。在夜莺的生态里,这个 agent 就是 categraf。
告警事件产生之后,告警引擎发现这个事件需要执行自愈动作,就会在服务端创建一个脚本任务,等着 agent 来拉取执行。所以本质上,是告警引擎 + 命令执行通道共同协作达成了告警自愈的效果。
部署配置
首先需要夜莺 v7.0.0-beta.2.0.1 以上的版本,之前的版本也有告警自愈的能力,但之前的版本需要额外安装部署 ibex 模块,从这个版本开始就不需要单独的 ibex 模块了。
修改夜莺服务端的配置
在夜莺的配置文件:etc/config.toml 中搜索 Ibex,把 Enable 设置为 true:
[Ibex]
Enable = true
RPCListen = "0.0.0.0:20090"
重启夜莺,让配置生效。此时通过 ss 或 netstat 命令可以看到夜莺服务端监听了 20090 端口。这是 categraf 拉取脚本任务、上报脚本结果的端口。
ss -tln|grep 20090
注意
如果夜莺使用的数据库连接账号是具备建表权限的,进程启动之后会自动创建 ibex 相关的表,就是告警自愈相关的表,如果夜莺使用的数据库连接账号没有建表权限,就需要手工建表了,建表 sql 在这里:https://github.com/flashcatcloud/ibex/blob/master/sql/ibex.sql 注意,从第 7 行开始复制,把这些表建到夜莺的库(默认是 n9e_v6)里,不要建到 ibex 库里了。老版本的告警自愈依赖单独的 ibex 模块,ibex 模块用的库是 ibex 库,现在夜莺新版本内置了 ibex 的能力,数据库也就合并到一起了。
如果你是从老版本的夜莺升级上来的,需要把之前的 ibex 库中的表迁移到 n9e_v6 库中,迁移命令如下:
mysqldump -u username -p ibex > ibex.sql
mysql -u root -p n9e_v6 < ibex.sql
修改 categraf 的配置
categraf 的配置文件是 conf/config.toml。在 conf/config.toml 中搜索 ibex,把 enable 设置为 true,并正确配置夜莺服务端的地址和端口:
[ibex]
enable = true
interval = "1000ms"
servers = ["127.0.0.1:20090"]
meta_dir = "./meta"
如果你的机器量比较大,比如超过 10000 台,建议把 interval 调整的稍微大一些,比如 2500ms,要不然容易给服务端造成太大压力。servers 配置是个数组,配置所有的夜莺服务端的地址,如果你有多个夜莺服务端实例,categraf 启动的时候会自动探测,连到那个网络延迟最小的实例上,如果夜莺服务端实例挂了,categraf 会自动切换到另外一个实例上,保证高可用。
改完配置之后重启 categraf,让配置生效。
注意
如果使用了夜莺的边缘部署模式,这里的 servers 就配置为 n9e-edge 的地址即可。当然,边缘模式的话 n9e-edge 的配置文件中要开启 Ibex。
测试命令通道
告警自愈依赖命令通道,我们先来测试一下命令通道是否正常。其实即便不用告警自愈,命令通道也是很有用的,可以用来批量远程执行命令,比如批量重启服务、批量清理日志、批量执行命令查看输出、批量安装个软件等等。
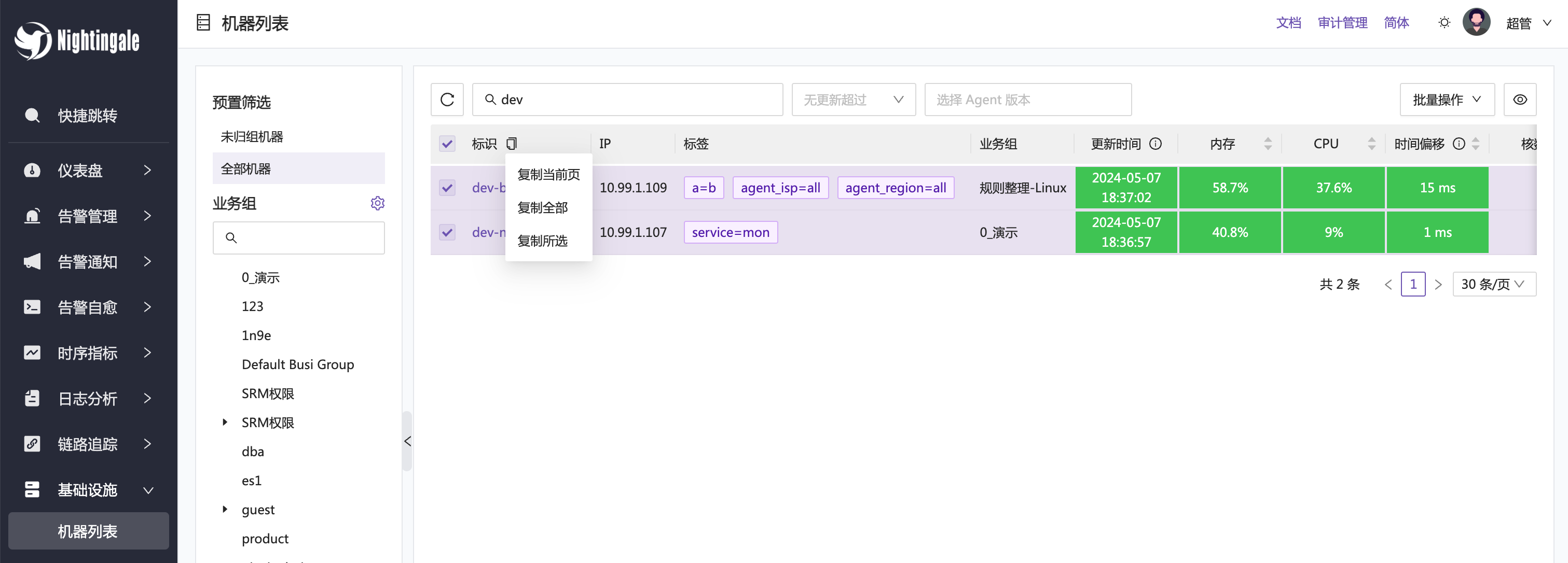
去机器列表里,选中要执行命令的机器,点击标识栏上面的复制按钮,复制相关的机器标识,然后去【告警自愈】-【任务】页面,创建临时任务。把刚才复制的机器列表填写到 Host 框中,然后在 Script 中填写要执行的脚本内容即可。默认 Script 中已经有一个 ss -tln 的命令了,可以不用修改直接执行。
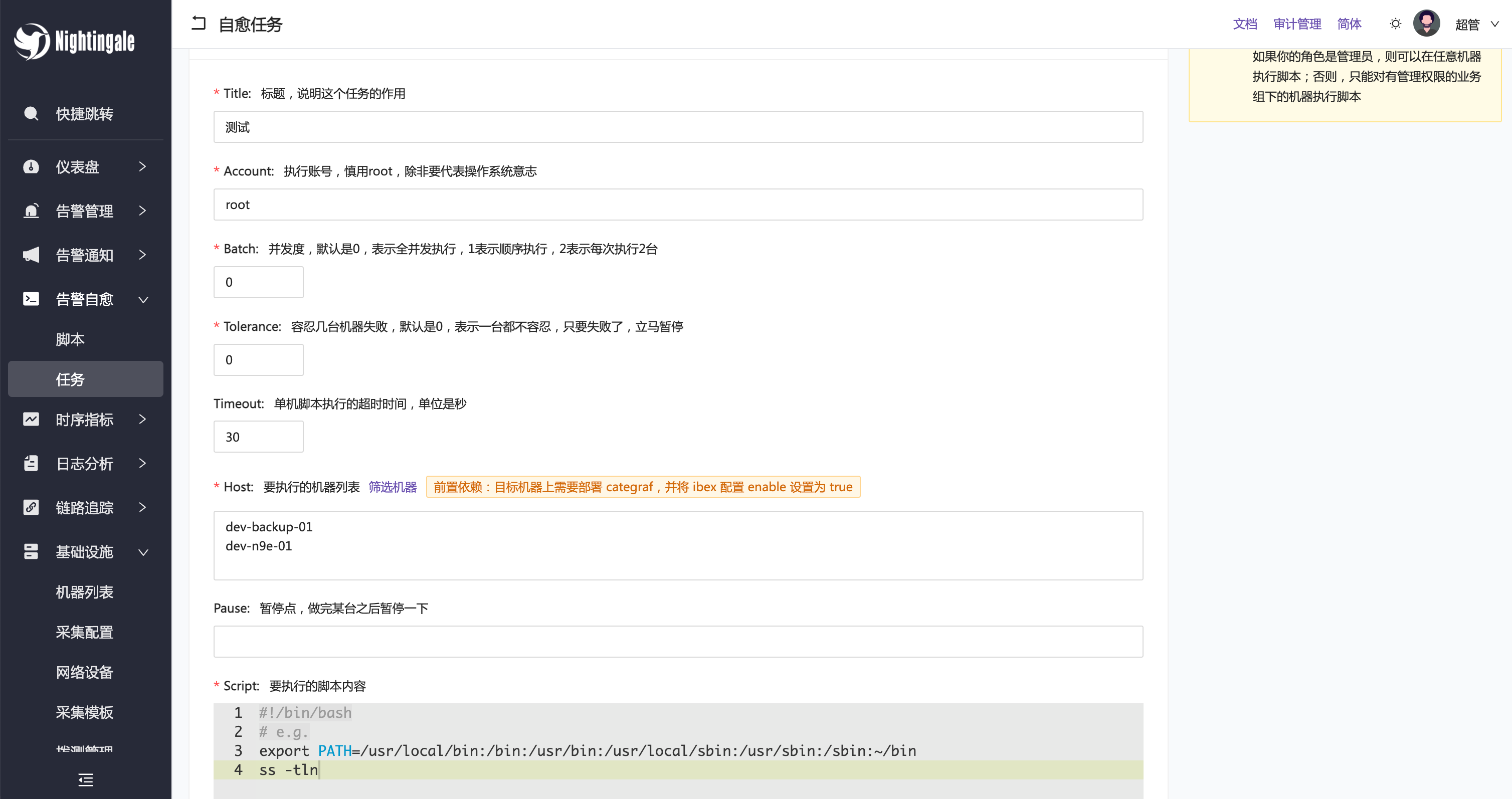
执行完成之后,结果如下,可以点击 stdouts 查看所有机器的脚本执行的 stdout 结果:
创建任务的时候,字段内容比较多,各个字段都有说明,我这里就不赘述了。核心就是去一批机器上跑个脚本。因为要跑脚本,需要控制权限,如果是 Admin 账号,所有机器都可以执行命令,如果是普通账号,只能去有权限的机器上执行脚本,哪些机器有权限?就看我管理了哪些业务组,我管理的这些业务组下的机器我就有权限。
创建自愈脚本
命令通道测通了。接下来就是和监控告警引擎联动,让告警事件产生的时候自动创建一个脚本任务,让 agent 去执行这个脚本任务。创建自愈脚本的菜单入口:【告警自愈】-【脚本】,比如我创建了如下脚本:
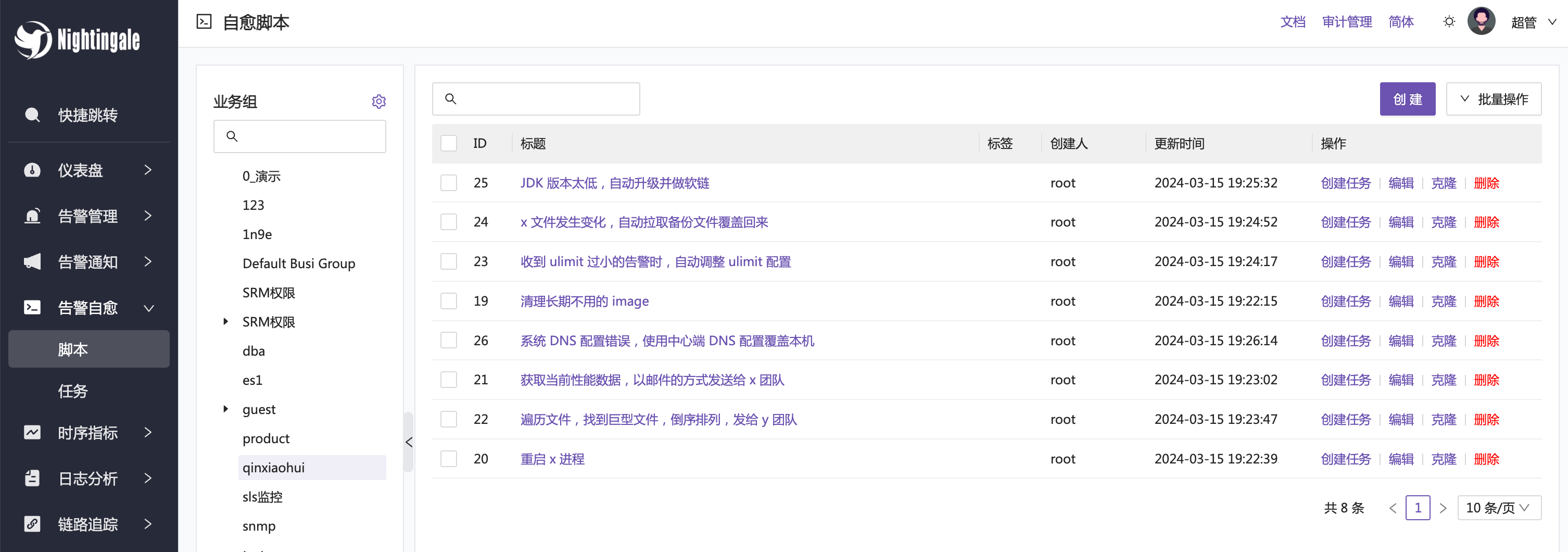
自愈脚本创建的时候,Host 字段留空即可。因为告警的时候才知道具体是哪个机器触发告警,Host 字段会被告警引擎动态填充。自动创建脚本任务。
当然,上面这些脚本都是我随便写的,仅做演示用。假设我现在要创建一个告警规则:“机器磁盘快满了”,如果触发告警,就自动执行 ID 为 19 的脚本,此时要怎么做呢?很简单,在告警规则里配置一个回调地址 ${ibex}/19 即可:
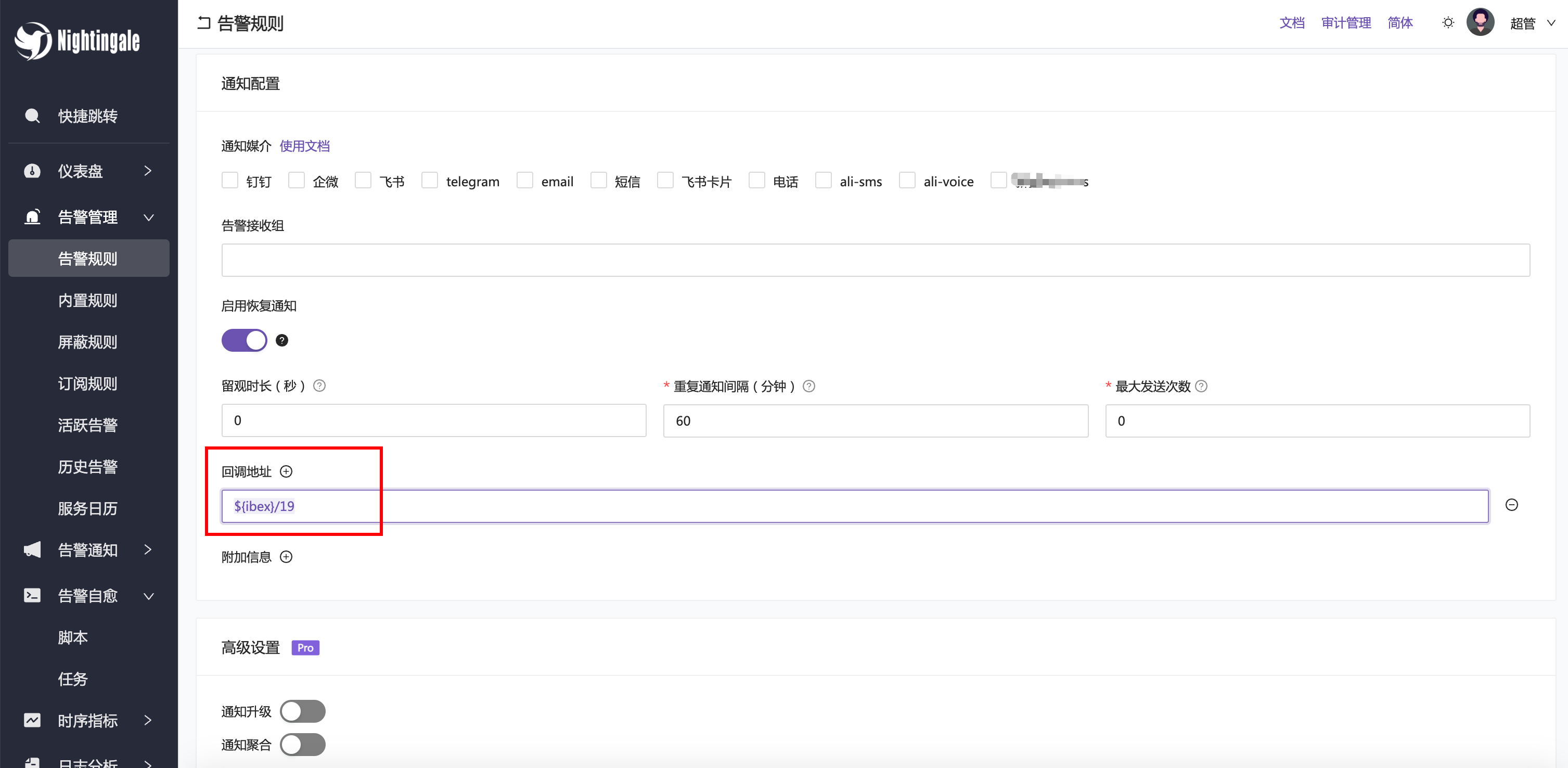
这样,当告警事件产生的时候,告警引擎会自动创建一个脚本任务,让 agent 去执行这个 ID 为 19 的脚本。这个脚本任务的执行结果会上报给服务端,你可以在【告警自愈】-【任务】页面查看这个任务的执行结果。
通常一个告警规则对应一个自愈脚本,如果想把脚本做的很通用,想用一个脚本干很多事,应对不同的场景。那就需要在脚本里拿到告警事件的详情,然后根据告警事件中的信息来做不同的处理。这个夜莺也是支持的,夜莺会把告警事件的关键信息放到脚本的 stdin 中传给脚本,你就可以在脚本里通过 stdin 拿到告警事件的内容了,比如我们准备一个这样的告警自愈脚本:
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
import sys
import jsonpayload = json.load(sys.stdin)
print(payload)
这是一个很简单的 Python 脚本,从 stdin 中读取内容,json decode(夜莺把告警事件关键信息组装成一个 json map 塞入 stdin,所以脚本这里要 json decode 一下) 一下放到 payload 变量里,然后用 print 把 payload 打印出来。打印的结果如下:
{'__name__': 'system_load_norm_1', 'alert_severity': '2', 'alert_trigger_value': '0.195', 'env': 'ENV', 'ident': 'dev-n9e-01', 'rulename': '测试告警自愈参数-勿删23'}
嗯,nice~ 这样我们就可以在脚本里根据告警事件的内容来做不同的处理了。
注意:告警事件中需要有 ident 标签(表示是哪个机器告警了),ident 对应的机器需要在机器列表里,且告警规则的最后修改人对这个机器有操作权限,夜莺才会去对应的机器执行脚本。
参考资料
- 夜莺监控官方文档: 告警自愈 - 快猫星云
- categraf 项目地址: https://github.com/flashcatcloud/categraf
- ibex 项目地址:GitHub - flashcatcloud/ibex
这篇关于细说夜莺监控系统告警自愈机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




