本文主要是介绍基于docker安装flink,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 环境准备
- Flink
- docker-compose方式
- 二进制部署
- Kafka
- Mysql
- Flink 执行 SQL命令
- 进入SQL客户端CLI
- 执行SQL查询
- 表格模式
- 变更日志模式
- Tableau模式
- 窗口计算
- 窗口计算
- 滚动窗口demo
- 滑动窗口
- 踩坑
环境准备
Flink
docker-compose方式
version: "3"
services:jobmanager:image: flink:latestexpose:- "6123"ports:- "8081:8081"command: jobmanagerenvironment:- JOB_MANAGER_RPC_ADDRESS=jobmanagertaskmanager:image: flink:latestexpose:- "6121"- "6122"depends_on:- jobmanagercommand: taskmanagerlinks:- "jobmanager:jobmanager"environment:- JOB_MANAGER_RPC_ADDRESS=jobmanager前端访问地址: http://192.168.56.112:8081/#/overview
二进制部署
wget https://archive.apache.org/dist/flink/flink-1.13.3/flink-1.13.3-bin-scala_2.11.tgzvim conf/flink-conf.yamljobmanager.rpc.address: 192.168.56.112 # 修改为本机ip./bin/start-cluster.shKafka
version: '2'
services:zookeeper:image: wurstmeister/zookeeper ## 镜像ports:- "2181:2181" ## 对外暴露的端口号kafka:image: wurstmeister/kafka ## 镜像volumes:- /etc/localtime:/etc/localtime ## 挂载位置(kafka镜像和宿主机器之间时间保持一直)ports:- "9092:9092"environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.56.112 ## 修改:宿主机IPKAFKA_ZOOKEEPER_CONNECT: 192.168.56.112:2181 ## 卡夫卡运行是基于zookeeper的kafka-manager:image: sheepkiller/kafka-manager ## 镜像:开源的web管理kafka集群的界面environment:ZK_HOSTS: ## 修改:宿主机IPports:- "9000:9000"
Mysql
docker run -d -p3306:3306 --name=mysql57 -e MYSQL_ROOT_PASSWORD=111111 mysql:5.7
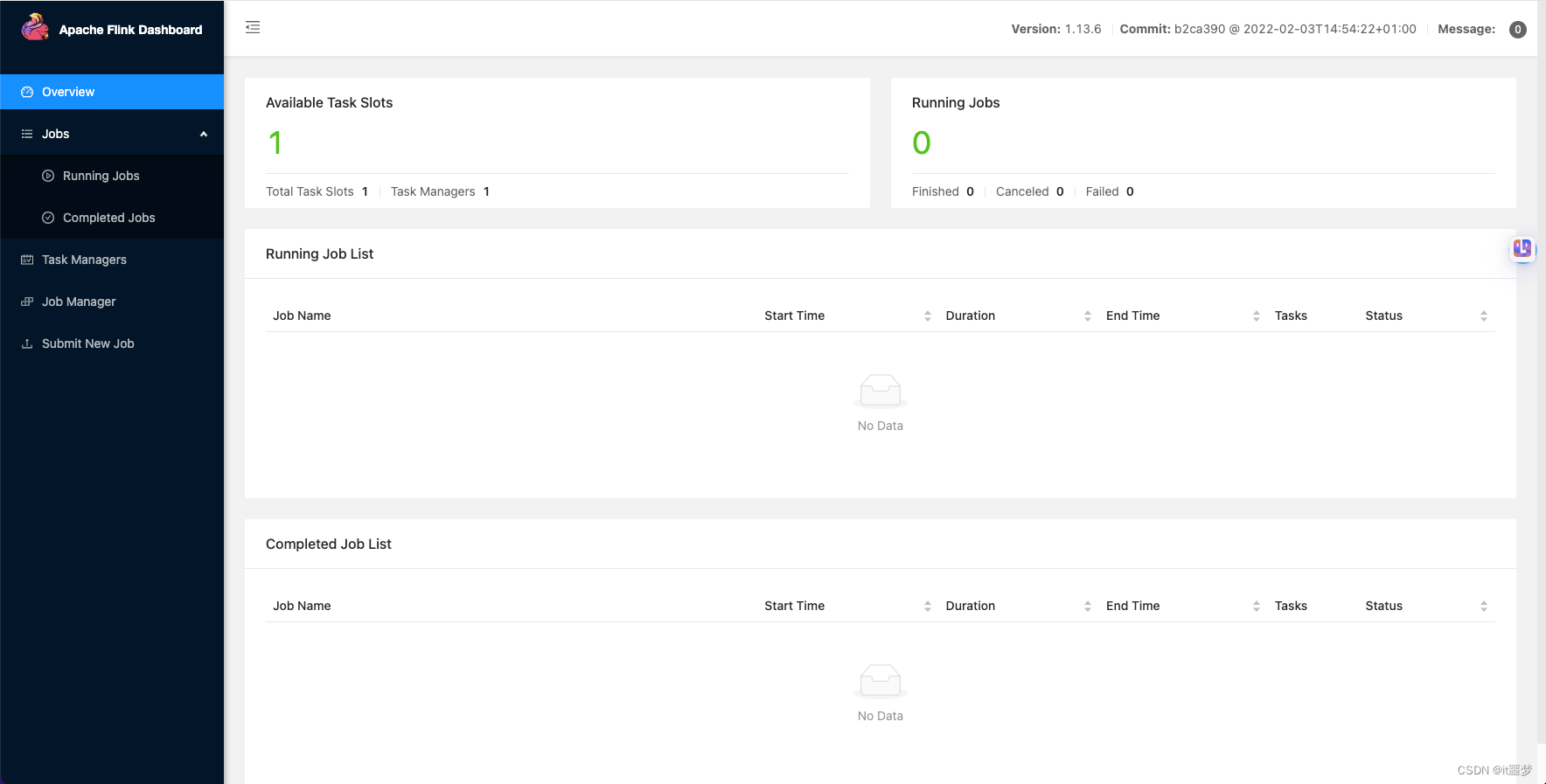
Flink 执行 SQL命令
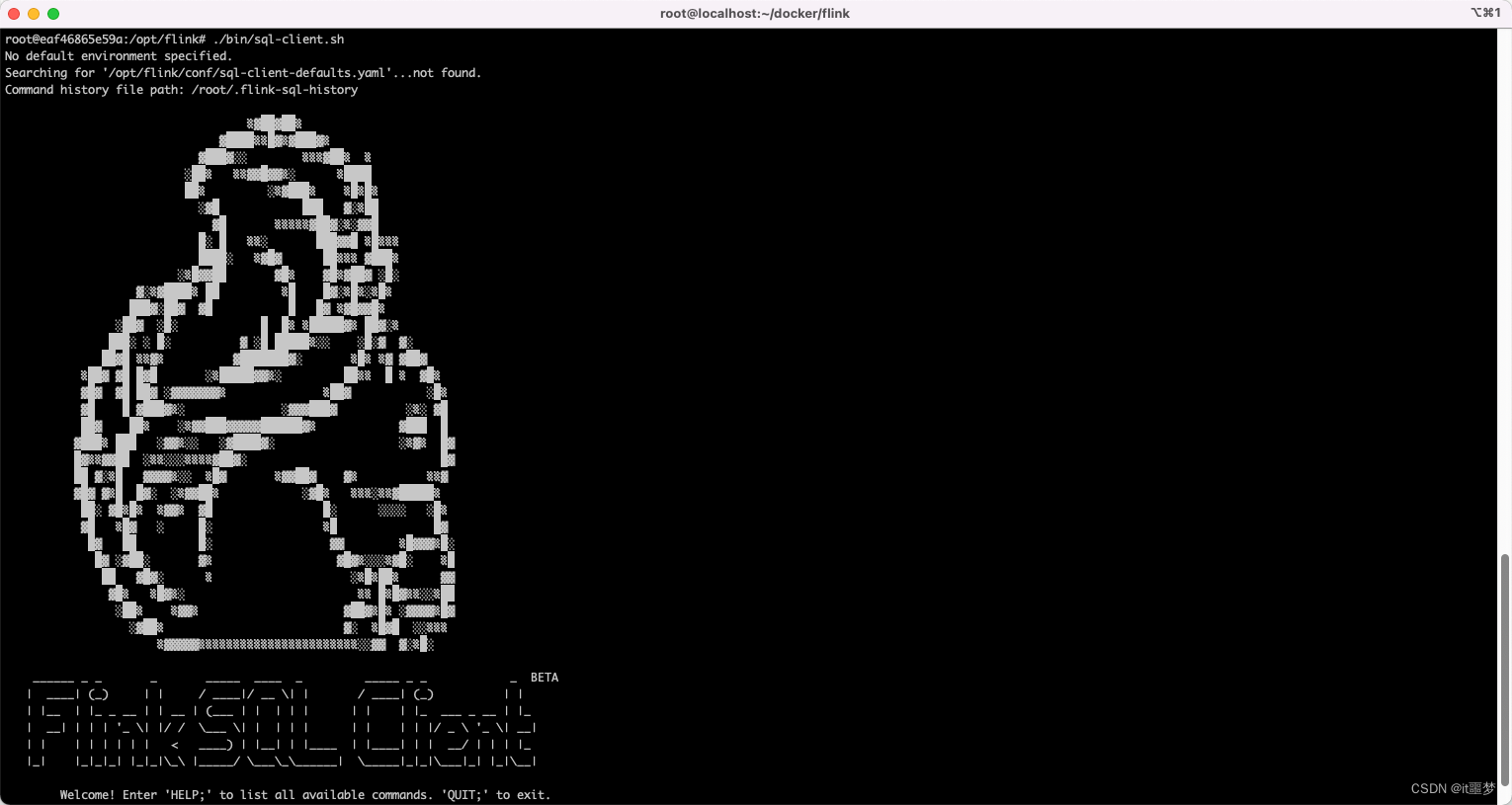
进入SQL客户端CLI
docker exec -it flink_jobmanager_1 /bin/bash./bin/sql-client.sh
执行SQL查询
SELECT 'Hello World';
表格模式
表格模式(table mode)在内存中物化结果,并将结果用规则的分页表格的形式可视化展示出来。执行如下命令启用:
SET sql-client.execution.result-mode = table;
可以使用如下查询语句查看不同模式的的运行结果:
SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;

变更日志模式
变更日志模式(changelog mode)不会物化结果。可视化展示由插入(+)和撤销(-)组成的持续查询结果流。
SET sql-client.execution.result-mode = changelog;

Tableau模式
Tableau模式(tableau mode)更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上。具体显示的内容取决于作业执行模式(execution.type):
SET sql-client.execution.result-mode = tableau;
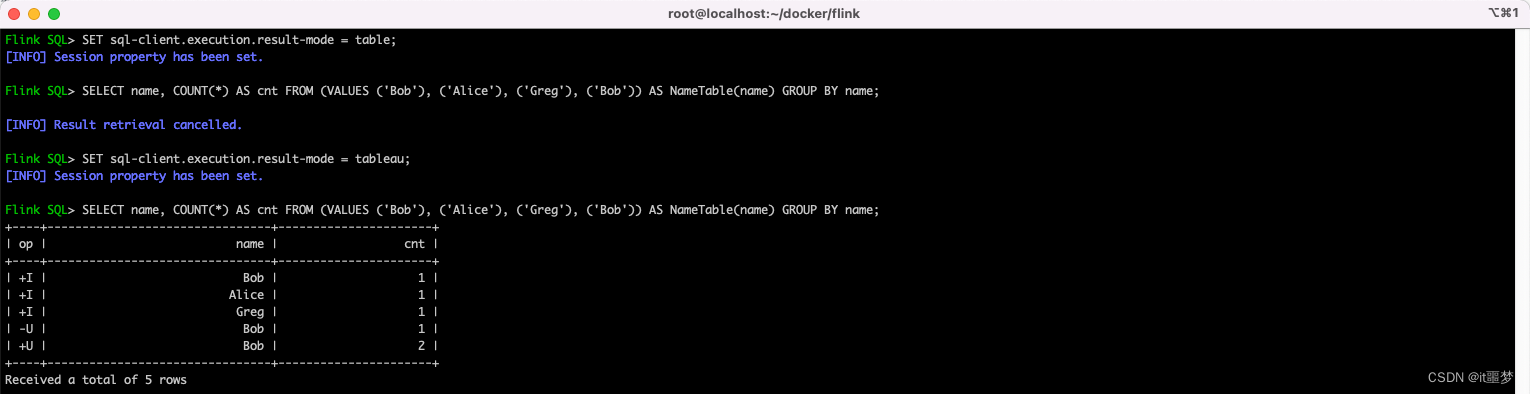
注意:当你在流式查询上使用这种模式时,Flink 会将结果持续的打印在当前的控制台上。如果流式查询的输入是有限数据集,那么 Flink 在处理完所有的输入数据之后,作业会自动停止,同时控制台上的打印也会自动停止。如果你想提前结束这个查询,那么可以直接使用 CTRL-C 按键,这个会停止作业同时停止在控制台上的打印。
窗口计算
TUMBLE(time_attr, interval) 定义一个滚动窗口。滚动窗口把行分配到有固定持续时间( interval )的不重叠的连续窗口。比如,5 分钟的滚动窗口以 5 分钟为间隔对行进行分组。滚动窗口可以定义在事件时间(批处理、流处理)或处理时间(流处理)上。
窗口计算
TUMBLE(time_attr, interval) 定义一个滚动窗口。滚动窗口把行分配到有固定持续时间( interval )的不重叠的连续窗口。比如,5 分钟的滚动窗口以 5 分钟为间隔对行进行分组。滚动窗口可以定义在事件时间(批处理、流处理)或处理时间(流处理)上。
滚动窗口demo
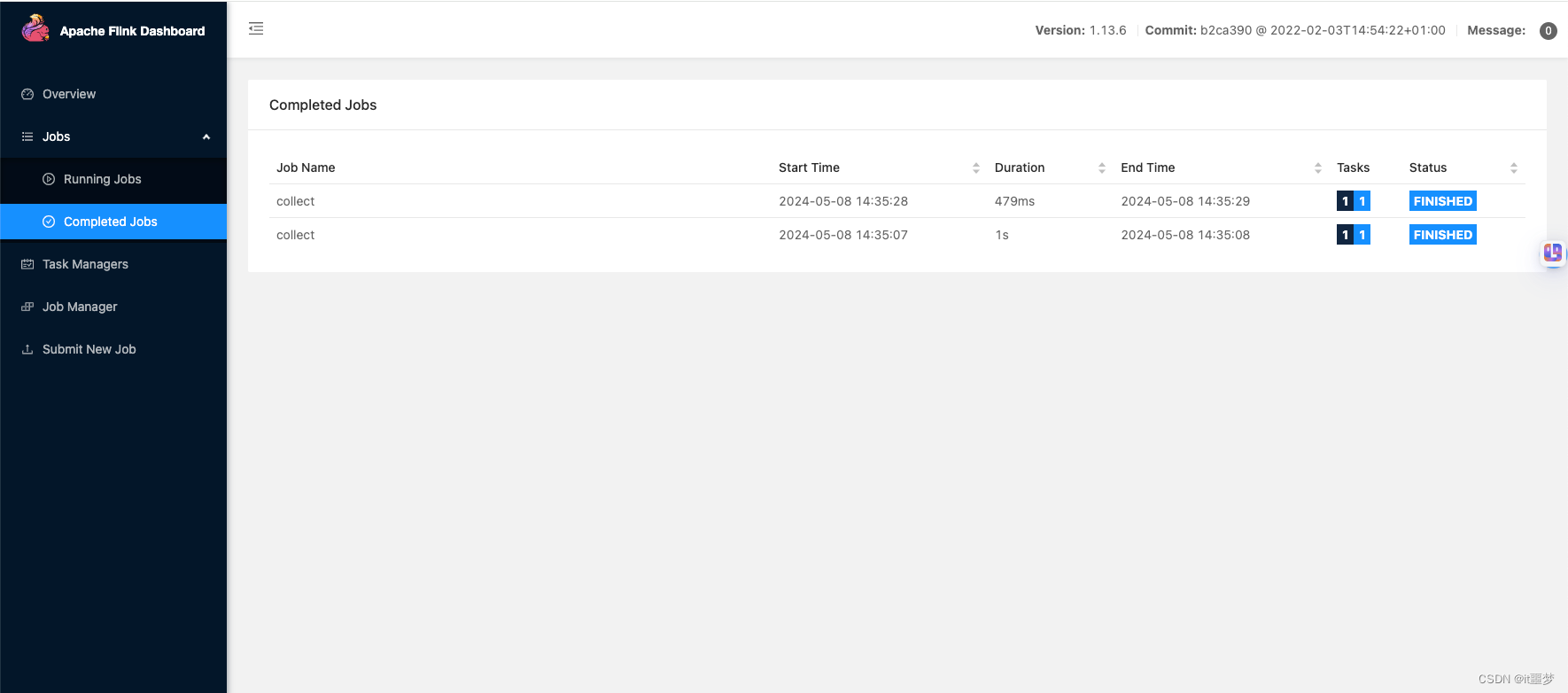
根据订单信息使用kafka作为数据源表,JDBC作为数据结果表统计用户在5秒内的订单数量,并根据窗口的订单id和窗口开启时间作为主键,将结果实时统计到JDBC中:
- 在MySQL的flink数据库下创建表order_count,创建语句如下:
CREATE TABLE `flink`.`order_count` (`user_id` VARCHAR(32) NOT NULL,`window_start` TIMESTAMP NOT NULL,`window_end` TIMESTAMP NULL,`total_num` BIGINT UNSIGNED NULL,PRIMARY KEY (`user_id`, `window_start`)
) ENGINE = InnoDBDEFAULT CHARACTER SET = utf8mb4COLLATE = utf8mb4_general_ci;
- 创建flink opensource sql作业,并提交运行作业
CREATE TABLE orders (order_id string,order_channel string,order_time timestamp(3),pay_amount double,real_pay double,pay_time string,user_id string,user_name string,area_id string,watermark for order_time as order_time - INTERVAL '3' SECOND
) WITH ('connector' = 'kafka','topic' = 'order_topic','properties.bootstrap.servers' = '192.168.56.112:9092','properties.group.id' = 'order_group','scan.startup.mode' = 'latest-offset','format' = 'json'
);CREATE TABLE jdbcSink (user_id string,window_start timestamp(3),window_end timestamp(3),total_num BIGINT,primary key (user_id, window_start) not enforced
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://192.168.56.112:3306/flink','table-name' = 'order_count','username' = 'root','password' = '111111','sink.buffer-flush.max-rows' = '1'
);SELECT 'WINDOW',-- window_start,window_end,group_key,record_num,create_time,SUM(record_num) OVER w AS sum_amount
FROM temp
WINDOW w AS (PARTITION BY group_keyORDER BY rowtimeRANGE BETWEEN INTERVAL '10' SECOND PRECEDING AND CURRENT ROW)select user_id,TUMBLE_START(order_time, INTERVAL '5' SECOND),TUMBLE_END(order_time, INTERVAL '5' SECOND),COUNT(*) from ordersGROUP BY user_id, TUMBLE(order_time, INTERVAL '5' SECOND) having count(*) > 3;SELECT 'WINDOW',user_id,order_id,real_pay,order_timeCOUNT(*) OVER w AS sum_amount
FROM orders
WINDOW w AS (PARTITION BY user_idORDER BY order_timeRANGE BETWEEN INTERVAL '60' SECOND PRECEDING AND CURRENT ROW) insert into jdbcSink select user_id,TUMBLE_START(order_time, INTERVAL '5' SECOND),TUMBLE_END(order_time, INTERVAL '5' SECOND),COUNT(*) from ordersGROUP BY user_id, TUMBLE(order_time, INTERVAL '5' SECOND) having count(*) > 3;
- Kafka 相关操作
bin/kafka-topics.sh --zookeeper 192.168.56.112:2181 --listbin/kafka-topics.sh --zookeeper 192.168.56.112:2181 --create --replication-factor 1 --partitions 1 --topic order_topicbin/kafka-console-producer.sh --broker-list 192.168.56.112:9092 --topic order_topicbin/kafka-console-consumer.sh --bootstrap-server 192.168.56.112:9092 --topic order_topic --from-beginningbin/kafka-topics.sh --zookeeper 192.168.56.112:2181 --describe --topic order_topic bin/kafka-topics.sh --zookeeper 192.168.56.112:2181 --delete --topic order_topic
发送数据样例
{"order_id":"202103241000000001", "order_channel":"webShop", "order_time":"2023-09-26 15:20:11", "pay_amount":"100.00", "real_pay":"100.00", "pay_time":"2021-03-24 10:02:03", "user_id":"0001", "user_name":"Alice", "area_id":"330106"}
{"order_id":"202103241000000001", "order_channel":"webShop", "order_time":"2023-08-10 17:28:10", "pay_amount":"100.00", "real_pay":"100.00", "pay_time":"2021-03-24 10:02:03", "user_id":"0001", "user_name":"Alice", "area_id":"330106"}
{"order_id":"202103241000000001", "order_channel":"webShop", "order_time":"2023-08-10 17:29:10", "pay_amount":"100.00", "real_pay":"100.00", "pay_time":"2021-03-24 10:02:03", "user_id":"0001", "user_name":"Alice", "area_id":"330106"}
{"order_id":"202103241000000001", "order_channel":"webShop", "order_time":"2023-08-10 17:29:10", "pay_amount":"100.00", "real_pay":"100.00", "pay_time":"2021-03-24 10:02:03", "user_id":"0001", "user_name":"Alice", "area_id":"330106"}
{"order_id":"202103241000000001", "order_channel":"webShop", "order_time":"2023-08-10 17:29:10", "pay_amount":"100.00", "real_pay":"100.00", "pay_time":"2021-03-24 10:02:03", "user_id":"0001", "user_name":"Alice", "area_id":"330106"}
{"order_id":"202103241000000001", "order_channel":"webShop", "order_time":"2023-08-10 17:30:10", "pay_amount":"100.00", "real_pay":"100.00", "pay_time":"2021-03-24 10:02:03", "user_id":"0001", "user_name":"Alice", "area_id":"330106"}
{"order_id":"202103241000000001", "order_channel":"webShop", "order_time":"2023-08-10 17:30:10", "pay_amount":"100.00", "real_pay":"100.00", "pay_time":"2021-03-24 10:02:03", "user_id":"0001", "user_name":"Alice", "area_id":"330106"}
滑动窗口
SELECT * FROM TABLE(HOP(TABLE orders, DESCRIPTOR(order_time), INTERVAL '2' SECOND, INTERVAL '10' SECOND));SELECT * FROM TABLE(HOP(DATA => TABLE orders,TIMECOL => DESCRIPTOR(order_time),SLIDE => INTERVAL '5' MINUTES,SIZE => INTERVAL '10' MINUTES));SELECT window_start, window_end, SUM(pay_amount)FROM TABLE(HOP(TABLE orders, DESCRIPTOR(order_time), INTERVAL '2' SECOND, INTERVAL '10' SECOND))GROUP BY window_start, window_end;
踩坑
- Could not find any factory for identifier ‘kafka’ that implements ‘org.apache.flink.table.factories.DynamicTableFactory’ in the classpath.
查看flink version
flink-sql-connector-kafka-1.17.1.jar
https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-kafka/1.17.1
下载对应版本jar,放到lib目录下,重启
-
Could not find any factory for identifier ‘jdbc’ that implements 'org.apache.flink.table.factories.DynamicTableFactory
flink-connector-jdbc-3.1.0-1.17.jar
https://repo1.maven.org/maven2/org/apache/flink/flink-connector-jdbc/3.1.0-1.17/flink-connector-jdbc-3.1.0-1.17.jar -
Caused by: java.lang.ClassNotFoundException: com.mysql.jdbc.Driver
https://mvnrepository.com/artifact/com.mysql/mysql-connector-j/8.0.31
这篇关于基于docker安装flink的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







