本文主要是介绍Sarcasm detection论文解析 |CAT-BiGRU,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址
论文地址:CAT-BiGRU: Convolution and Attention with Bi-Directional Gated Recurrent Unit for Self-Deprecating Sarcasm Detection | Cognitive Computation
github:Ashraf-Kamal/Self-Deprecating-Sarcasm-Detection (github.com)
论文首页

笔记框架

CAT-BiGRU:使用双向门控循环单元进行卷积和注意力,用于自嘲讽刺检测
📅出版年份:2022
📖出版期刊:Cognitive Computation
📈影响因子:5.4
🧑文章作者:Kamal Ashraf,Abulaish Muhammad
📍 期刊分区:JCR分区: Q1 中科院分区升级版: 计算机科学3区 中科院分区基础版: 工程技术2区 影响因子: 5.4 5年影响因子: 4.8 EI: 是 南农高质量: A
🔎摘要:
背景 对于计算语言学研究人员来说,讽刺检测一直是一个研究得很透彻的问题。然而,有关不同类别讽刺语言的研究仍未得到广泛关注。自贬式讽刺(Self-Deprecating Sarcasm,SDS)是讽刺的一种特殊类别,即用户对自己进行讽刺,它被广泛应用于社交媒体平台,主要作为一种广告工具,用于品牌代言、产品宣传和数字营销,目的是提高销售量。
方法:在本文中,我们提出了一种用于检测 Twitter 上 SDS 的深度学习方法。我们提出了一种新颖的双向门控循环单元(CAT-BiGRU)的卷积和注意力模型,该模型由输入、嵌入、卷积、双向门控循环单元(BiGRU)和两个注意力层组成。卷积层从嵌入层中提取基于 SDS 的句法和语义特征,BiGRU 层从提取的特征中检索前后方向的上下文信息,注意力层用于从输入文本中检索基于 SDS 的综合上下文表示。最后,采用 sigmoid 函数将输入文本分类为自嘲或非自嘲讽刺。
结果和结论:在七个 Twitter 数据集上进行了实验,以使用标准评估指标评估所提出的 (CAT-BiGRU) 模型。实验结果令人印象深刻,并且明显优于许多基于神经网络的基线和最先进的方法。在本文中,我们强调了所提出的方法的生物学启发和心理动机基础,以检查其相对于 SeticNet 的情感能力。所提出模型的功效在两个基于 SenticNet 的情感计算资源——Amazon 词嵌入和 AffectiveSpace 上进行了评估。根据实验结果,我们得出结论,基于深度学习的方法有潜力准确检测社交媒体文本中的 SDS。
🌐研究目的:
研究一种用于检测 Twitter 上 SDS 的深度学习方法
📰研究背景:
对于计算语言学研究人员来说,讽刺检测一直是一个研究得很透彻的问题。然而,有关不同类别讽刺语言的研究仍未得到广泛关注。自贬式讽刺(Self-Deprecating Sarcasm,SDS)是讽刺的一种特殊类别,即用户对自己进行讽刺,它被广泛应用于社交媒体平台,主要作为一种广告工具,用于品牌代言、产品宣传和数字营销,目的是提高销售量。
🔬研究方法:
提出了一种新颖的双向门控循环单元(CAT-BiGRU)的卷积和注意力模型,该模型由输入、嵌入、卷积、双向门控循环单元(BiGRU)和两个注意力层组成。
自嘲推文识别
识别显式自嘲推文
旨在根据推文中是否存在某些显式模式来识别自引用推文。
-
特定模式
-
通用模式
从显式自嘲推文中聚类
以连接组件的形式对 Exps 的所有推文进行聚类。
仅当一对自引用推文(节点)之间的 Jaccard 相似度大于阈值 0.6 时,才会创建一对自引用推文(节点)之间的边,如 [28] 中给出的。
从集群中进行模式挖掘
在识别出显式自引用推文的集群后,在此步骤中从集群中挖掘频繁模式(三元组)。
隐式自嘲推文识别
考虑所有在上述步骤(i)中没有任何匹配的推文,并称为隐式推文。
这一步的主要目的是从低召回值中恢复过来。
与显式自嘲识别合并
将两组显式自引用推文和隐式自引用推文合并在一起,生成候选自引用推文列表 St,即 St = Exps ∪ Imps 。
🔩模型架构:
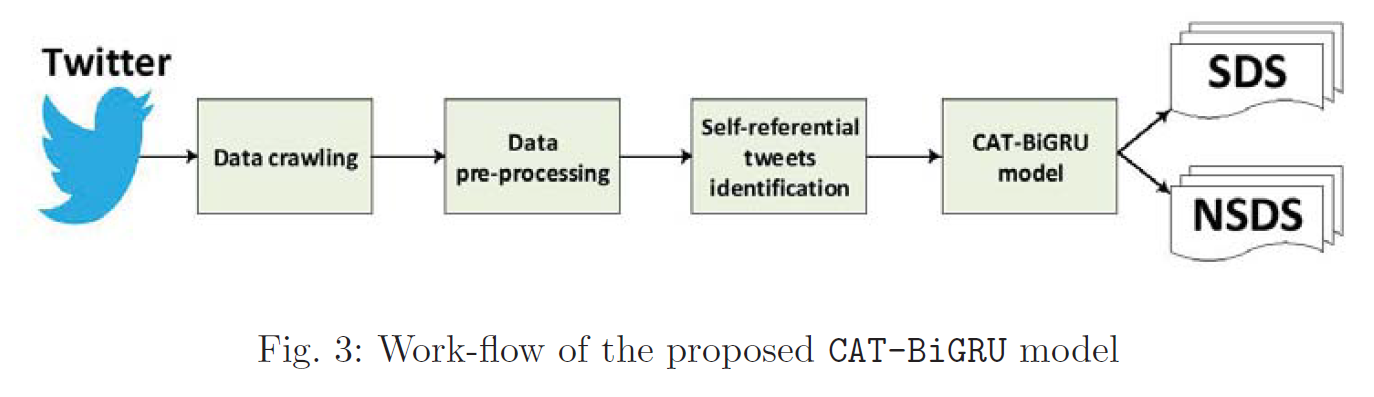
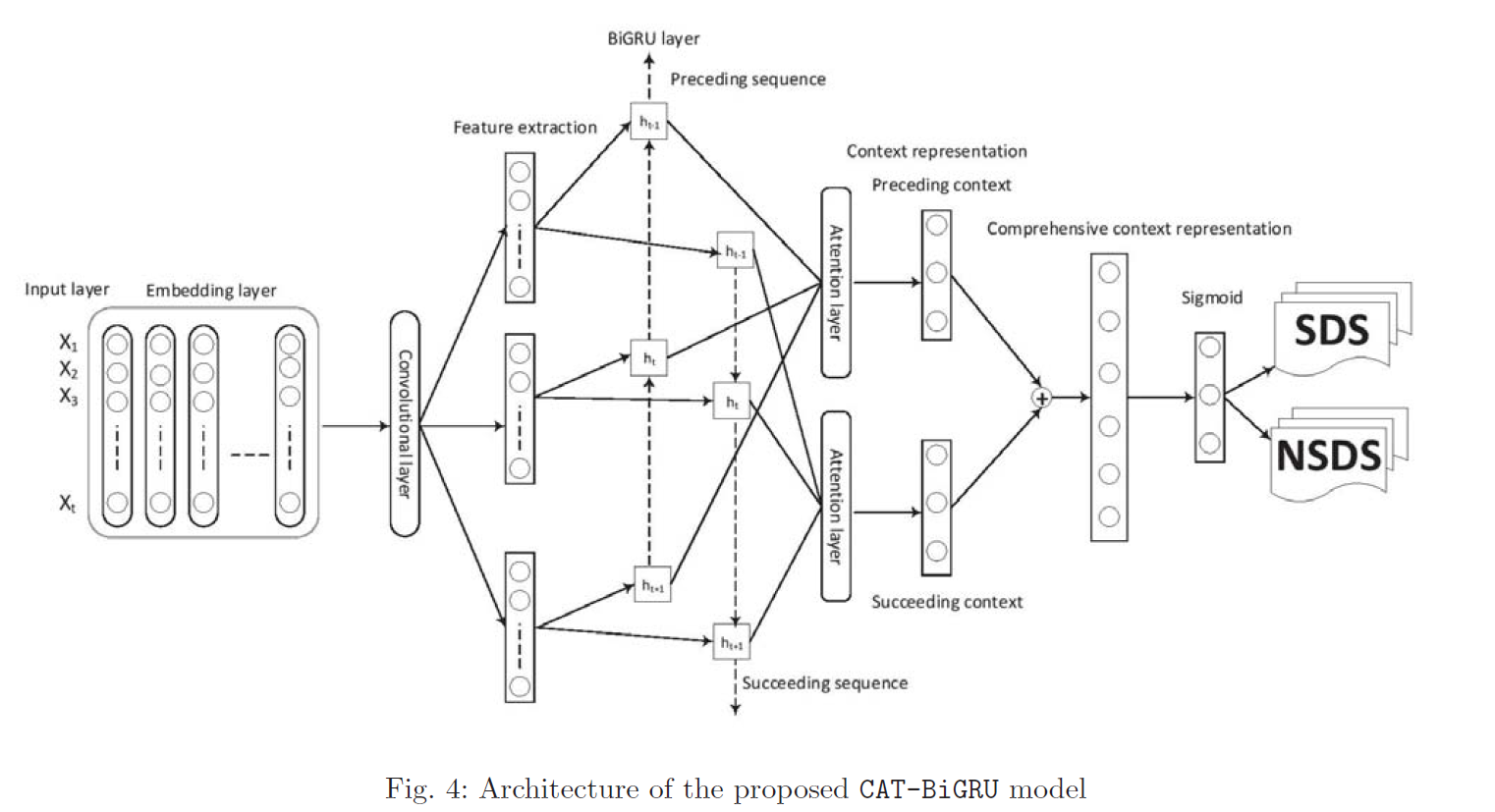
CAT-BiGRU 模型旨在通过将卷积层、BiGRU 和两个注意力层集成在一起来改善上述缺点。
输入层:
每条候选自引用推文都被标记化,转换为序列,并替换为其字典索引值。
为了使每个候选自引用推文的长度相同,使用固定的padding值。
它被转换为矩阵形式,其中每一行代表一个自引用推文向量,并传递到词嵌入层。
嵌入层
嵌入层充当神经网络架构中的隐藏层。
在本文中,使用了全局向量(GloVe)
卷积层
我们总共考虑了 256 个滤波器和 3 的窗口大小,它在嵌入向量上移动以提取特征。结果,生成了掌握基于 SDS 的句法和语义特征的各种序列。
卷积层用于从候选自引用推文中提取基于 SDS 的语法和语义特征。
BiGRU层
可以向前和向后两个方向工作,并从卷积层生成的特征中获取基于上下文信息的序列。
注意力层
两个注意力层利用重要词语的权重提取基于 SDS 的上下文表示。这些表征是从 BiGRU 的前后语境信息序列中提取的。
使用两个注意力层来允许候选自指推文中的单词具有不同的权重,以加强对基于 SDS 的单词/标记的理解。
softmax层
使用softmax激活函数获得每个单词的归一化权重。
dropout 用于通过在训练过程中丢弃神经元的随机样本来减少过度拟合并改善泛化误差。
二元交叉熵损失函数用于分类器训练,它将自引用推文标签解释为 SDS 或 NSDS。
🧪实验:
📇 数据集:
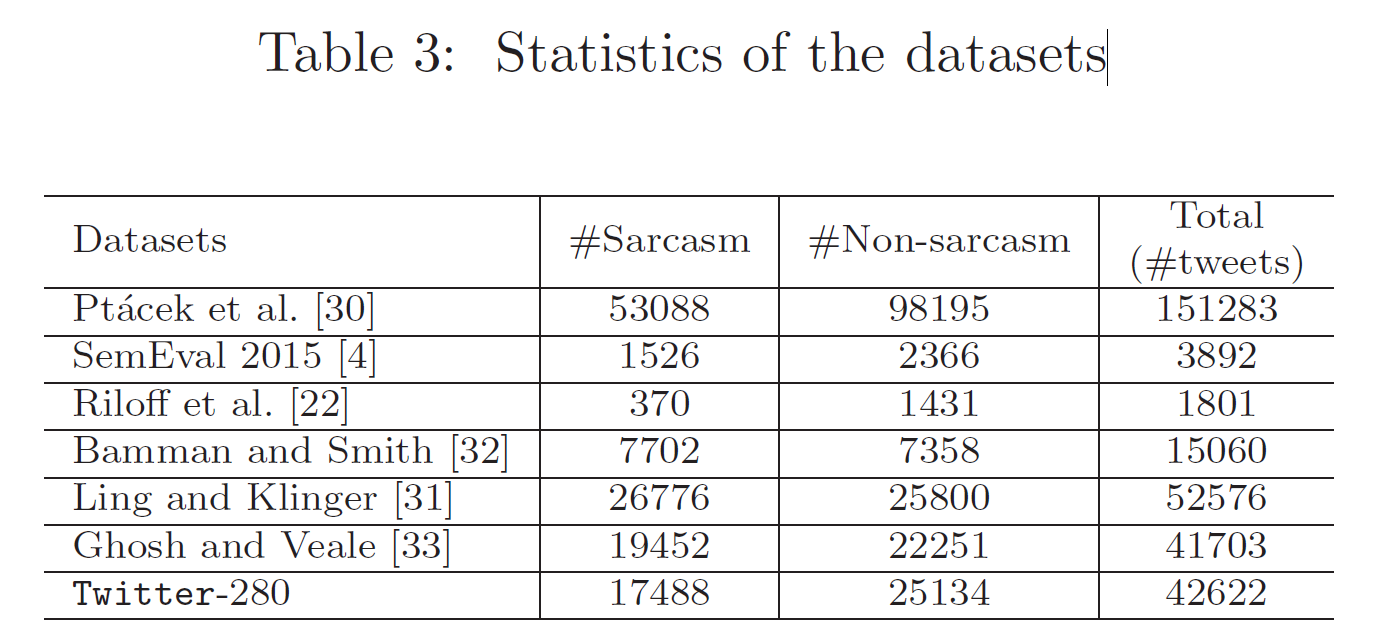
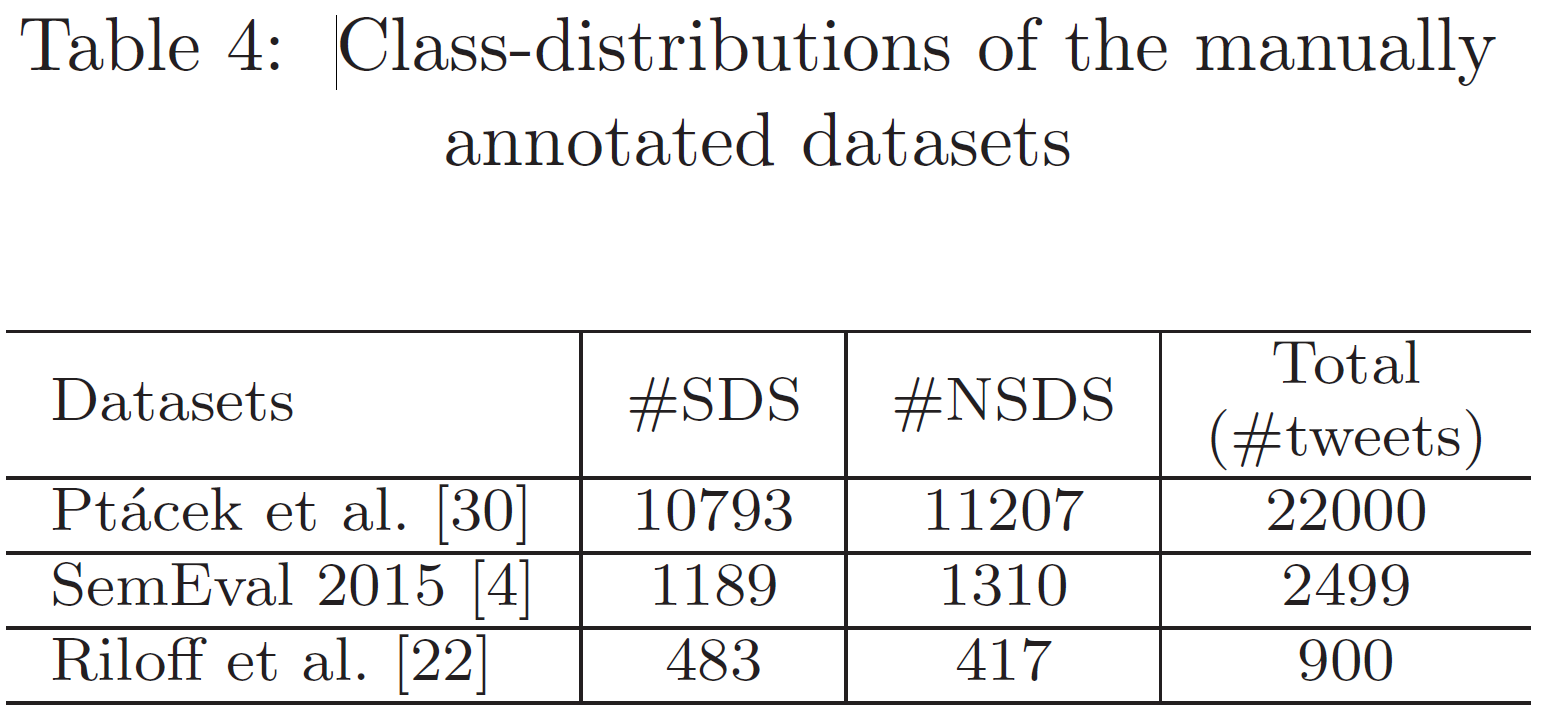
除了六个基准数据集之外,我们还创建了一个新数据集,即 Twitter-280,其中包含使用基于主题标签的注释技术通过爬虫从 2019 年 6 月 1 日到 2019 年 7 月 31 日发布的讽刺和非讽刺推文。
所有数据集分为训练集和测试集,其中80%的数据用于训练,20%的数据用于测试。
被手动注释为 SDS 或 NSDS。

📏评估指标:
使用四个标准评估指标进行评估——精确度、召回率、f 分数和准确性。
📉 优化器&超参数:
批量大小和详细值分别取256 和 2。
我们考虑了 Adam 优化算法
总共 100 个轮次来训练模型

💻 实验设备:
使用神经网络API Keras执行训练
📊 参数的影响:
显示不同 GloVe 嵌入维度、GRU 参数和感知计算资源对上述所有数据集上的 CAT-BiGRU 模型的影响。
GRU隐藏单元的数量
图 8 和图 9 分别展示了不同 GRU 隐藏单元(200、256 和 300)的 CAT-BiGRU 模型在所有数据集上的 f 分数和准确度值的分类结果。
结果表明,具有 256 个隐藏单元的 GRU 在所有数据集上表现更好。这些结果还表明隐藏单元的数量对 CAT-BiGRU 模型的性能有显着影响。
优化算法
使用两种不同的优化算法(Adam 和 RMSprop)对 CAT-BiGRU 模型的性能进行分析。
图 10 和 11 显示了 Adam 和 RMSprop 优化算法对 CAT-BiGRU 模型分类结果的影响(在所有数据集上的 f 分数和准确度值)。总的来说,从这些图中可以看出,在所有数据集上使用 Adam 优化器获得的结果都比使用 RMSprop 优化器获得的结果要好。
激活函数的效果
我们分析不同激活函数(sigmoid 和 softmax)对 CAT-BiGRU 模型性能的影响。
实验结果表明,在所有数据集上,使用 sigmoid 函数获得的 CAT-BiGRU 模型的分类结果优于使用 softmax 函数获得
感知计算资源的影响

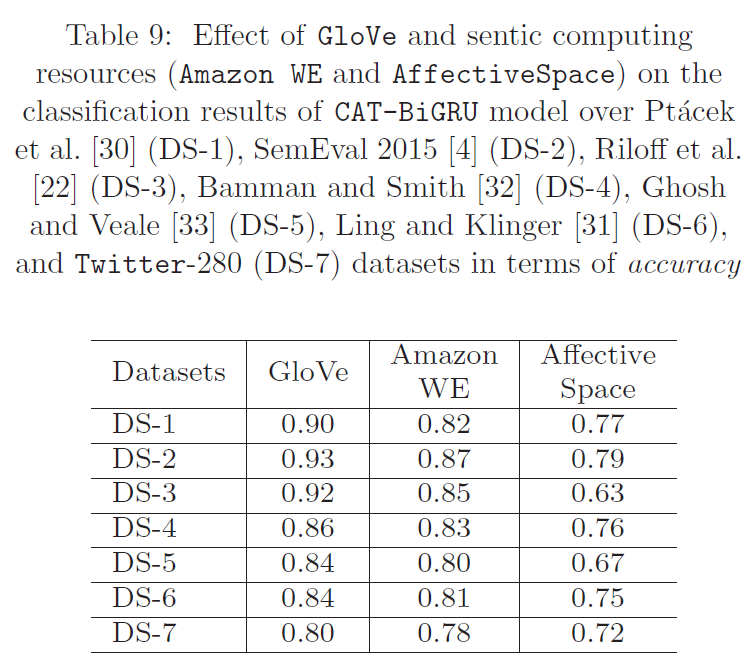
表 8 和表 9 列出了 CAT-BiGRU 模型使用 GloVe和 AffectiveSpace 的 CAT-BiGRU 模型的分类结果和 AffectiveSpace 的分类结果。有趣的是,拟议的 CAT-BiGRU 模型在使用两种计算资源的 CAT-BiGRU 模型在所有数据集上的 F1 分数和准确率值方面都取得了良好的结果。不过,与 AffectiveSpace 相比,使用 Amazon WE 获得的结果更好。根据这些结果可以推断出,在 CAT-BiGRU 模型中加入 sentic 计算资源可以提高其检测 SDS 的准确性。
📋 实验结果:
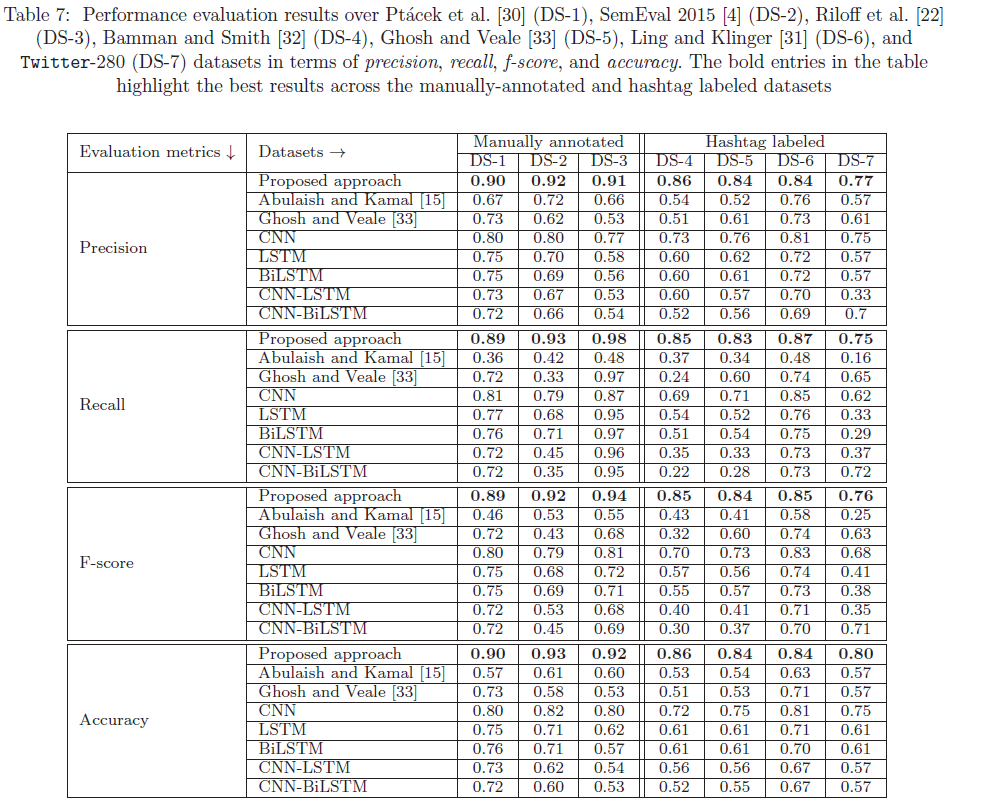
基于上述结果,可以推断,与 Ghosh 和 Veale [33] 方法相比,在我们提出的模型中包含两个在前后方向上起作用的注意层提供了更好的上下文表示,其中采用堆叠方法而无需任何注意力层机制。 Ghosh 和 Veale [33] 方法仅在一个方向上发挥作用,缺乏双向讽刺检测的上下文表示。
🚩研究结论:
在本文中,我们提出了一种用于 SDS 检测的新型 CAT-BiGRU 模型。所提出的模型由输入、嵌入、卷积、BiGRU 和两个注意力层组成,并从不同角度对七个数据集进行评估。
CAT-BiGRU 的实验结果很有希望,并且与各种基于神经网络的基线和最先进的方法相比明显更好。
📝总结
💡创新点:
我们提出了一种新颖的双向门控循环单元(CAT-BiGRU)的卷积和注意力模型,该模型由输入、嵌入、卷积、双向门控循环单元(BiGRU)和两个注意力层组成。
⚠局限性:
🔧改进方法:
🖍️知识补充:
推文通常是精确、简短和非正式的,并且包含非文字表达词、bashes、语法错误的词、非结构化短语和俚语。
近年来,各种神经网络模型,如RNN,在许多NLP应用中表现出了更好的性能,并以更少的特征数量获得了显着的效果。 RNN的架构是顺序的,可以处理任意长度的序列,主要是执行序列建模任务。
GRU 属于 RNN 家族,它克服了与非结构化文本相关的复杂单词建模任务。尽管 GRU 从文本中提取上下文信息,但它不会从已识别的上下文数据中检索重要信息。
此外,单词的语义和语法关系取决于上下文因素,这对于涉及文本分类、机器翻译和语音识别的许多 NLP 应用非常有用。
在神经网络中,注意力机制通过为文本中的每个单词指定不同的权重来突出显示重要的关键字,并最大限度地减少非关键字的影响。
💬讨论:
这篇关于Sarcasm detection论文解析 |CAT-BiGRU的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





