本文主要是介绍操作系统实战(二)(linux+C语言),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实验内容
通过Linux 系统中管道通信机制,加深对于进程通信概念的理解,观察和体验并发进程间的通信和协作的效果 ,练习利用无名管道进行进程通信的编程和调试技术。
管道pipe是进程间通信最基本的一种机制,两个进程可以通过管道一个在管道一端向管道发送其输出,给另一进程可以在管道的另一端从管道得到其输入。管道以半双工方式工作,即它的数据流是单方向的。因此使用一个管道一般的规则是读管道数据的进程关闭管道写入端,而写管道进程关闭其读出端。
示例程序
效果为:两个进程交替分别对X进行+1操作
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(int argc, char *argv[])
{int pid; //进程号int pipe1[2]; //存放第一个无名管道标号int pipe2[2]; //存放第二个无名管道标号int x; // 存放要传递的整数//使用pipe()系统调用建立两个无名管道。建立不成功程序退出,执行终止if(pipe(pipe1) < 0){perror("pipe not create");exit(EXIT_FAILURE);}if(pipe(pipe2) < 0){perror("pipe not create");exit(EXIT_FAILURE);}//使用fork()系统调用建立子进程,建立不成功程序退出,执行终止if((pid=fork()) <0){perror("process not create");exit(EXIT_FAILURE);}//子进程号等于0 表示子进程在执行else if(pid == 0){//子进程负责从管道1的0端读,管道2的1端写//所以关掉管道1的1端和管道2的0端。close(pipe1[1]);close(pipe2[0]);//每次循环从管道1 的0 端读一个整数放入变量X 中,//并对X 加1后写入管道2的1端,直到X大于10do{read(pipe1[0],&x,sizeof(int));printf("child %d read: %d\n",getpid(),x++);write(pipe2[1],&x,sizeof(int));}while( x<=9 );//读写完成后,关闭管道close(pipe1[0]);close(pipe2[1]);//子进程执行结束exit(EXIT_SUCCESS);}//子进程号大于0 表示父进程在执行else{//父进程负责从管道2的0端读,管道1的1端写,//所以关掉管道1 的0 端和管道2 的1端。close(pipe1[0]);close(pipe2[1]);x=1;//每次循环向管道1 的1 端写入变量X 的值,并从//管道2的0 端读一整数写入X 再对X加1,直到X 大于10do{write(pipe1[1],&x,sizeof(int));read(pipe2[0],&x,sizeof(int));printf("parent %d read: %d\n",getpid(),x++);}while(x<=9);//读写完成后,关闭管道close(pipe1[1]);close(pipe2[0]);}//父进程执行结束return EXIT_SUCCESS;
}
执行结果:

几个关键点
一、pipe系统调用的使用

- 创建管道两个端口 :int pipe[2]
- 调用pipe系统调用在两个端口间建立管道
- 后续可利用read、write通过管道端口,利用管道进行进程间通信
- 为了防止出现死锁以及消息冲突,需要进行close处理
- 读写操作传输的值都是实际地址
pipe管道端口不与进程绑定,而是可以更改的;pipe管道端口的作用是固定的,0端口读,1端口写
二、perror函数的使用
perror()是一个C语言标准库函数,用于打印错误信息。它接受一个字符串参数作为错误信息的前缀,并将系统的错误消息附加到该前缀后面。
一般用于打印系统调用的错误,能够自动输出系统调用错误的编码。见下面示例代码:
#include <stdio.h>
#include <errno.h>int main() {FILE *file = fopen("nonexistent_file.txt", "r");if (file == NULL) {perror("Error opening file: ");return 1;}// 其他文件操作...fclose(file);return 0;
}
其输出是:
Error opening file: No such file or directory
三、read、write函数的使用
(1)读取时:要先关闭管道的写入端口,才能从输出端口进行读出
read函数的三个参数分别为:
close(port[1]);
read(port[0],数据,要传输的数据长度);(2)输出时:
write函数的三个参数分别为:
close(port[0]);
write(port[1],数据,要传输的数据长度);本次实验
实验内容

实验代码
#include <stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include <wait.h>//三个递归函数的定义,每个函数用一个进程来运行,运行结果利用pipe通信
//f(x)
int fx(int x){if(x <= 0){printf("the number you input must be positive!");return 0;}else if(x == 1){return 1;}else if(x > 1){return fx(x-1) * x;}
}
//f(y)
int fy(int y){if(y <= 0){printf("the number you input must >2!");return 0;}else if(y == 1 || y == 2){return 1;}else if(y > 2){return fy(y-1) + fy(y-2);}
}
//f(x,y)
int fxy(int fx, int fy){return fx + fy;
}int main(int argc,char* argv[]){int pid1; //子进程1int pid2; //子进程2int pid; //父进程int pipe1[2]; //第一个管道:父进程写,子进程读int pipe2[2]; //第二个管道:父进程读,子进程写int result1; //保存f(x)和f(y)的计算结果int result2;int result;int status; //记录子进程状态int x;int y;//从键盘输入x和yprintf("please input number x: ");scanf("%d",&x);printf("\n");printf("please input number y: ");scanf("%d",&y);printf("\n");//开始创建管道if(pipe(pipe1)<0){perror("pipe1 not create");exit(EXIT_FAILURE);}if(pipe(pipe2)<0){perror("pipe2 not create");exit(EXIT_FAILURE);}//创建子进程开始执行操作pid1=fork(); if(pid1<0){ //第一个子进程,注意以下!!!!我在这里踩了坑perror("process1 not create");exit(EXIT_FAILURE);}//子进程1在执行if(pid1==0){//子进程负责在管道1的1端写,父进程在管道1的0端读//所以关掉管道1的0端close(pipe1[0]);result1=fx(x);printf("子进程1完成了运算,f(x)=%d\n",result1);//将运行结果发送出去write(pipe1[1],&result1,sizeof(int));//写完成后,关闭管道close(pipe1[1]);//子进程执行结束exit(EXIT_SUCCESS);}//父进程运行else{waitpid(pid1, &status, 0); //等待子进程运行结束再执行父进程(主动阻塞父进程,也可以让其因为read被动阻塞)printf("我是父进程%d,已经等待子进程%d完成,现开始运行\n",getpid(),pid1);close(pipe1[1]); //在访问共享资源前都要避免互斥//从管道1的0端口获得数值read(pipe1[0],&result1,sizeof(int));close(pipe1[0]);//创建另一个进程2执行f(y)程序printf("父进程%d已获取结果1,先创建新子进程运行f(y)\n ",getpid());pid2=fork();//使用fork()系统调用建立子进程,建立不成功程序退出,执行终止if(pid2 <0){perror("子进程2没有创建成功");exit(EXIT_FAILURE);}//第二个子进程,pipe2[1]用来写if(pid2 == 0){//关掉pipe2[0]端close(pipe2[0]);//计算f(y)result2 = fy(y);printf("子进程2完成了运算,f(y)=%d\n",result2);//发送消息write(pipe2[1],&result2,sizeof(int));close(pipe2[1]);}//父进程else{waitpid(pid2, &status, 0);close(pipe2[1]);//接受第二个子进程从管道里发来的信息read(pipe2[0],&result2,sizeof(int));result = fxy(result1,result2);printf("f(x) = %d\n",result1);printf("f(y) = %d\n",result2);printf("f(x,y) = %d\n",result);//读完成后关闭管道close(pipe2[1]);//父进程执行结束return EXIT_SUCCESS;}}
}运行结果
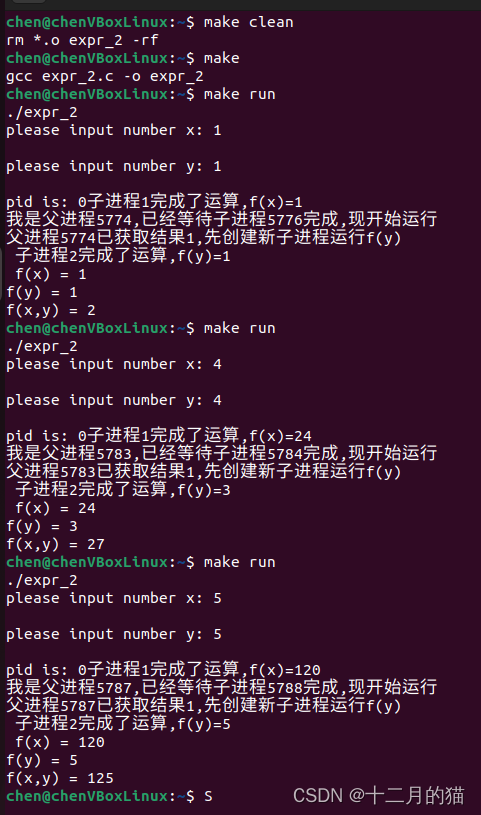
踩的坑
1、读只能从端口0进行,写从端口1进行
2、编程思路:对于一个进程它必须只要要完成一个操作单位体,计算一个递归函数就是一个操作单位体
3、
赋值运算优先级小于比较运算:所以if(pid1=fork()>0)此时执行的是if(pid1=(fork()>0)),也就是说pid1并未得到fork()返回的子进程pid而是得到比较运算结果1。
解决方案:1、可以把pid=fork,与pid>0分成两步去实现;2、可以修改if(pid1=fork()>0)为if((pid1=fork())>0)
makefile文件编写
# DEPEND 代替 依赖文件# CC 代替 gcc# CFLAGS 代替 编译命令# PARA 代替 参数# OBJS 代替 目标文件DEPEND=expr_2.cOBJS=expr_2CC=gccCFLAGS=-oexpr_1:$(DEPEND)$(CC) $(DEPEND) $(CFLAGS) $(OBJS)run:$(OBJS)./$(OBJS) clean:rm *.o $(OBJS) -rf
实验感悟
一、进程协作的特点:
- 共享资源:进程协作和通信允许多个进程共享资源,本示例中父子进程共享变量x
- 数据传输:进程可以通过通信机制相互传输数据,以实现信息交换和共享。本实验代码中进程之间传输不同函数运行的结果,从而实现协作
- 进程间控制:进程协作可以通过管道、消息队列、共享内存等实现进程间的控制和协调。本实验中采用管道控制
二、进程通信机制:
目前我们已经学习的有四种类型,如下:
-
管道:管道是一种单向通信机制,用于在具有亲缘关系的进程之间传递数据。它可以通过创建一个管道文件描述符来实现进程间的通信
-
消息队列:消息队列是一种存放消息的容器,进程可以通过发送和接收消息来实现通信。消息队列提供了一种异步通信的方式
-
共享内存:共享内存允许多个进程共享同一块内存区域,进程可以通过读写共享内存来交换数据
-
信号量(Semaphore):信号量是一种用于进程间同步和互斥访问共享资源的机制。进程可以使用信号量来控制对共享资源的访问
其中管道主要用于父子两个进程之间的简单通信,是单向的。实现起来也简单快捷,但是无法处理多个进程之间的复杂协作
三、进程管道通信的具体流程:
-
创建管道:通过调用系统的管道函数,创建一个管道,它会返回两个文件描述符,一个用于读取数据,一个用于写入数据
-
创建子进程:使用系统调用(如fork())创建一个新的子进程
-
父子进程通信:父进程可以通过写入管道的文件描述符将数据发送给子进程,子进程可以通过读取管道的文件描述符接收数据
-
关闭管道:当通信结束后,父进程和子进程都需要关闭管道的文件描述符,释放相关的资源
总结
本文到这里就结束啦~~
本篇文章重点在于利用linux系统的完成操作系统的实验,巩固课堂知识
本篇文章的撰写+实验代码调试运行+知识点细致化学习,共花了本人3h左右的时间
个人觉得已经非常详细啦,如果仍有不够希望大家多多包涵~~如果觉得对你有帮助,辛苦友友点个赞哦~
知识来源:山东大学《操作系统原理实用实验教程》张鸿烈老师编著

这篇关于操作系统实战(二)(linux+C语言)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







