本文主要是介绍2024DCIC海上风电出力预测Top方案 + 光伏发电出力高分方案学习记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
海上风电出力预测
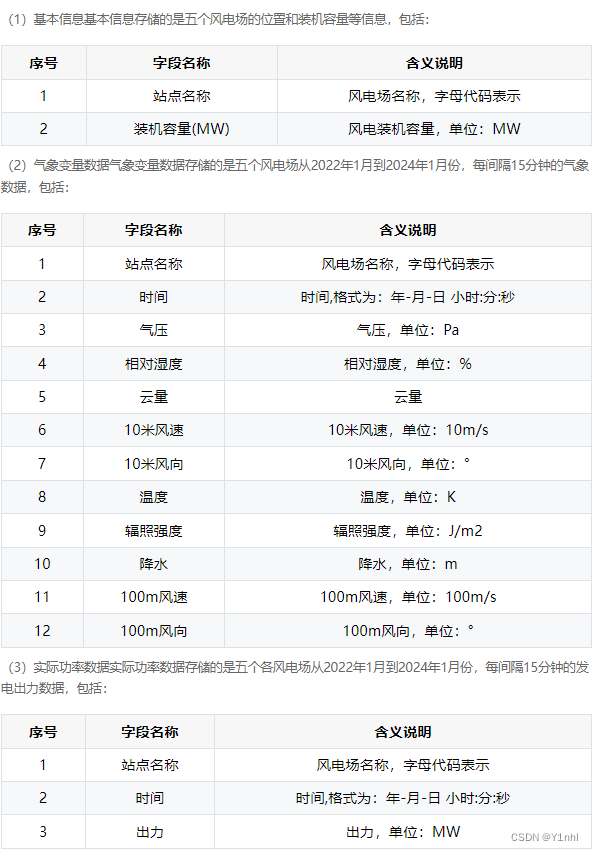
赛题数据
海上风电出力预测的用电数据分为训练组和测试组两大类,主要包括风电场基本信息、气象变量数据和实际功率数据三个部分。风电场基本信息主要是各风电场的装机容量等信息;气象变量数据是从2022年1月到2024年1月份,各风电场每间隔15分钟的气象数据;实际功率数据是各风电场每间隔15分钟的发电出力数据。
方案
1.特征构建
for col in tqdm.tqdm(num_cols):# 历史平移 + 差分特征 + 二阶差分特征for i in [1,2,3,4,5,6,7,15,30,50] + [1*96,2*96,3*96,4*96,5*96]:df[f'{col}_shift{i}'] = df.groupby('stationId')[col].shift(i)df[f'{col}_feture_shift{i}'] = df.groupby('stationId')[col].shift(-i)df[f'{col}_diff{i}'] = df[f'{col}_shift{i}'] - df[col]df[f'{col}_feture_diff{i}'] = df[f'{col}_feture_shift{i}'] - df[col]df[f'{col}_2diff{i}'] = df.groupby('stationId')[f'{col}_diff{i}'].diff(1)df[f'{col}_feture_2diff{i}'] = df.groupby('stationId')[f'{col}_feture_diff{i}'].diff(1)# 均值相关df[f'{col}_3mean'] = (df[f'{col}'] + df[f'{col}_feture_shift1'] + df[f'{col}_shift1'])/3df[f'{col}_5mean'] = (df[f'{col}_3mean']*3 + df[f'{col}_feture_shift2'] + df[f'{col}_shift2'])/5df[f'{col}_7mean'] = (df[f'{col}_5mean']*5 + df[f'{col}_feture_shift3'] + df[f'{col}_shift3'])/7df[f'{col}_9mean'] = (df[f'{col}_7mean']*7 + df[f'{col}_feture_shift4'] + df[f'{col}_shift4'])/9df[f'{col}_11mean'] = (df[f'{col}_9mean']*9 + df[f'{col}_feture_shift5'] + df[f'{col}_shift5'])/11df[f'{col}_shift_3_96_mean'] = (df[f'{col}_shift{1*96}'] + df[f'{col}_shift{2*96}'] + df[f'{col}_shift{3*96}'])/3df[f'{col}_shift_5_96_mean'] = (df[f'{col}_shift_3_96_mean']*3 + df[f'{col}_shift{4*96}'] + df[f'{col}_shift{5*96}'])/5df[f'{col}_future_shift_3_96_mean'] = (df[f'{col}_feture_shift{1*96}'] + df[f'{col}_feture_shift{2*96}'] + df[f'{col}_feture_shift{3*96}'])/3df[f'{col}_future_shift_5_96_mean'] = (df[f'{col}_future_shift_3_96_mean']*3 + df[f'{col}_feture_shift{4*96}'] + df[f'{col}_feture_shift{5*96}'])/3# 窗口统计for win in [3,5,7,14,28]:df[f'{col}_win{win}_mean'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').mean().valuesdf[f'{col}_win{win}_max'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').max().valuesdf[f'{col}_win{win}_min'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').min().valuesdf[f'{col}_win{win}_std'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').std().valuesdf[f'{col}_win{win}_skew'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').skew().valuesdf[f'{col}_win{win}_kurt'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').kurt().valuesdf[f'{col}_win{win}_median'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').median().values# 逆序df = df.sort_values(['stationId','time'], ascending=False)df[f'{col}_future_win{win}_mean'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').mean().valuesdf[f'{col}_future_win{win}_max'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').max().valuesdf[f'{col}_future_win{win}_min'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').min().valuesdf[f'{col}_future_win{win}_std'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').std().valuesdf[f'{col}_future_win{win}_skew'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').skew().valuesdf[f'{col}_future_win{win}_kurt'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').kurt().valuesdf[f'{col}_future_win{win}_median'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').median().values# 恢复正序df = df.sort_values(['stationId','time'], ascending=True)# 二阶特征df[f'{col}_win{win}_mean_loc_diff'] = df[col] - df[f'{col}_win{win}_mean']df[f'{col}_win{win}_max_loc_diff'] = df[col] - df[f'{col}_win{win}_max']df[f'{col}_win{win}_min_loc_diff'] = df[col] - df[f'{col}_win{win}_min']df[f'{col}_win{win}_median_loc_diff'] = df[col] - df[f'{col}_win{win}_median']df[f'{col}_future_win{win}_mean_loc_diff'] = df[col] - df[f'{col}_future_win{win}_mean']df[f'{col}_future_win{win}_max_loc_diff'] = df[col] - df[f'{col}_future_win{win}_max']df[f'{col}_future_win{win}_min_loc_diff'] = df[col] - df[f'{col}_future_win{win}_min']df[f'{col}_future_win{win}_median_loc_diff'] = df[col] - df[f'{col}_future_win{win}_median']for col in ['is_precipitation']:for win in [4,8,12,20,48,96]:df[f'{col}_win{win}_mean'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').mean().valuesdf[f'{col}_win{win}_sum'] = df.groupby('stationId')[col].rolling(window=win, min_periods=3, closed='left').sum().values
☆2.目标转化

这里的处理应该是最终获TOP的trick。之前在砍老师的文章中也提到了这个处理,例如预测房价时,转换为预测单位面积下的房价。
光伏发电
本题海上风力很类似。
方案
特征
df["年"] = df["时间"].dt.yeardf["季节"] = df["时间"].dt.quarter
df["月"] = df["时间"].dt.monthdf["日"] = df["时间"].dt.day
df["周"] = df["时间"].dt.weekdf["分"] = df["时间"].dt.minute // 15 + df["时间"].dt.hour * 4
df["分"] = df["分"].astype("category")df['100m风速(100m/s)'] = df['100m风速(100m/s)'] * np.sin(np.pi * df['100m风向(°)'] / 180)
df['10米风速(10m/s)'] = df['10米风速(10m/s)'] * np.sin(np.pi * df['10米风向(°)'] / 180)
df["光照/温度"] = df["辐照强度(J/m2)"] / df["温度(K)"]# 这里做平移 + 差分
dfs = []
for site, df_site in df.groupby("光伏用户编号"):df_site = df_site.sort_values("时间")df_site["辐照强度(J/m2) - 1"] = df_site["辐照强度(J/m2)"].shift(1) - df_site["辐照强度(J/m2)"]df_site["辐照强度(J/m2) - 8"] = df_site["辐照强度(J/m2)"].shift(8) - df_site["辐照强度(J/m2)"]dfs.append(df_site)
df = pd.concat(dfs, axis=0)# 这里是提取一个辐照强度和当天最强辐照强度的比值特征(因为夏天和冬天的辐照强度不同,比值特征会更加合理)
df["日期"] = df["时间"].dt.date
day_max_values = df[["光伏用户编号", "日期", "辐照强度(J/m2)"]].groupby(by=["光伏用户编号", "日期"]).max()
day_max_values = day_max_values.rename(columns={x: x + "_max" for x in day_max_values.columns}).reset_index()
df = pd.merge(df, day_max_values, on=["光伏用户编号", "日期"], how="left").drop(columns=["日期"])
df["辐照强度(J/m2)_max"] = df["辐照强度(J/m2)"] / df["辐照强度(J/m2)_max"]# 温差特征
df["日期"] = df["时间"].dt.date
day_max_values = df[["光伏用户编号", "日期", "温度(K)"]].groupby(by=["光伏用户编号", "日期"]).max()
day_min_values = df[["光伏用户编号", "日期", "温度(K)"]].groupby(by=["光伏用户编号", "日期"]).min()
day_max_values = day_max_values.rename(columns={x: x + "_max" for x in day_max_values.columns}).reset_index()
day_min_values = day_min_values.rename(columns={x: x + "_min" for x in day_min_values.columns}).reset_index()
df = pd.merge(df, day_max_values, on=["光伏用户编号", "日期"], how="left")
df = pd.merge(df, day_min_values, on=["光伏用户编号", "日期"], how="left").drop(columns=["日期"])
df["温度(K)_max"] = df["温度(K)_max"] - df["温度(K)"]
df["温度(K)_min"] = df["温度(K)"] - df["温度(K)_min"]
df = df.rename(columns={"辐照强度(J/m2)_max": "光照/当天最强光照","温度(K)_max": "与当天最高温度之差","温度(K)_min": "与当天最低温度之差"
})
这篇关于2024DCIC海上风电出力预测Top方案 + 光伏发电出力高分方案学习记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




