本文主要是介绍Sarcasm detection论文解析 |基于情感背景和个人表达习惯的有效讽刺检测方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文地址
论文地址:https://link.springer.com/article/10.1007/s12559-021-09832-x#/
论文首页

笔记框架
基于情感背景和个人表达习惯的有效讽刺检测方法
📅出版年份:2022
📖出版期刊:Cognitive Computation
📈影响因子:5.4
🧑文章作者:Du Yu,Li Tong,Pathan Muhammad Salman,Teklehaimanot Hailay Kidu,Yang Zhen
📍 期刊分区:JCR分区: Q1 中科院分区升级版: 计算机科学3区 中科院分区基础版: 工程技术2区 影响因子: 5.4 5年影响因子: 4.8 EI: 是 南农高质量: A
🔎 摘要:
讽刺在社交媒体中很常见,人们用它来间接表达自己情绪更强烈的观点。虽然它属于情感分析的一个分支,但传统的情感分析方法无法识别反讽修辞,因为它需要大量的背景知识。现有的讽刺检测方法主要集中于使用各种自然语言处理技术来分析讽刺的文本内容。本文认为,检测讽刺的本质问题是联系其上下文,包括回复目标文本的文本情绪和用户的表达习惯。提出了一种双通道卷积神经网络,不仅可以分析目标文本的语义,还可以分析其情感背景。此外,SenticNet还用于为长短期记忆(LSTM)模型添加常识。然后应用注意力机制来考虑用户的表达习惯。在多个公共数据集上进行了一系列实验,结果表明所提出的方法可以显着提高讽刺检测任务的性能。
🌐 研究目的:
提高讽刺检测任务的性能
研究问题:
通过添加模型注意力机制提取的用户表达习惯,是否可以提高讽刺文本的预测性能?
语义、情感和用户维度的结合能否提高讽刺文本的预测性能?
所提出的方法比现有的先进模型更好吗?
📰 研究背景:
现有的讽刺检测方法主要集中于使用各种自然语言处理技术来分析讽刺的文本内容。本文认为,检测讽刺的本质问题是检查其上下文,包括回复目标文本的文本情绪和用户的表达习惯。
🔬 研究方法:
本文遵循的研究方法主要分为三个部分,如图2所示。
情感上下文不协调特征嵌入
其中上下文情感信息被添加到词嵌入方法中,并使用CNN来分别提取评论的语义和情感特征。
用户表达习惯特征
其中使用Bi-LSTM对语义词向量进行编码,然后结合用户的注意力机制构建表达习惯的特征向量。
集成了多维信息
即语义、情感上下文和用户习惯
🔩 模型架构:

情感上下文不协调特征嵌入模型
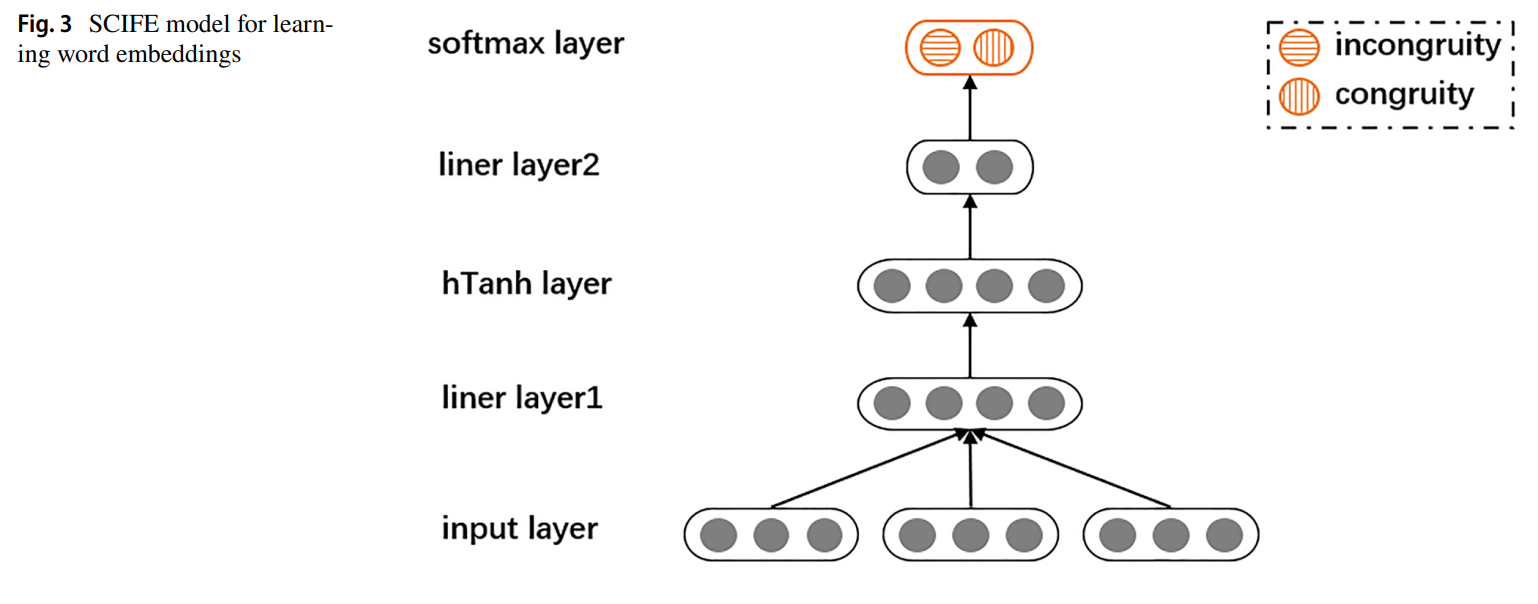
输入层
SARC 数据集的注释用作 SCIFE 模型训练的输入序列。
线性层1
输入层输出序列词e(w1),e(w2)...e(wn),线性层1在串联后进行线性变换。
滑动窗口大小3是经过多次实验选择的合适参数。
hTanh层
为了使模型获得非线性特征,模型选择硬版本的双曲正切作为非线性函数。
线性层2
使用线性变换方法结合提取的情感特征并计算输入序列的情感分数。
softmax层
softmax 层用于标准化所有情感分数。
优化和学习
练目标是最小化训练数据中的交叉熵损失。
CNN架构
经过预处理后,通过Glove和SCIFE模型得到单词的向量表示。
双通道 CNN 模型考虑了两个独立的向量表示,即语义通道和情感通道。
窗口大小3是经过多次实验选择的合适参数。
利用卷积运算分别得到评论的语义隐藏序列表示hri和评论的情感不一致隐藏序列表示hci。
使用最大池化方法来保留显着特征,同时减少输出的维度。
用户表达习惯特征工程
将常识向量 μt 添加到 LSTM 每个时间节点的输入门、遗忘门和输出门。
当前的研究中使用了注意力机制,为句子中的不同单词分配不同的权重,并提取对特定用户的表达重要的单词。
最后,将信息聚合成句子的特征向量。
这里根据任务选择前馈神经网络作为评分函数的参数化方法。
讽刺分类
该模型使用非线性ReLU投影层来学习这三个特征向量的联合表示。
softmax 层用于标准化所有预测标签。
所提出的神经网络模型经过端到端训练,以优化标准二元交叉熵损失函数。
🧪 实验:
📇 数据集:
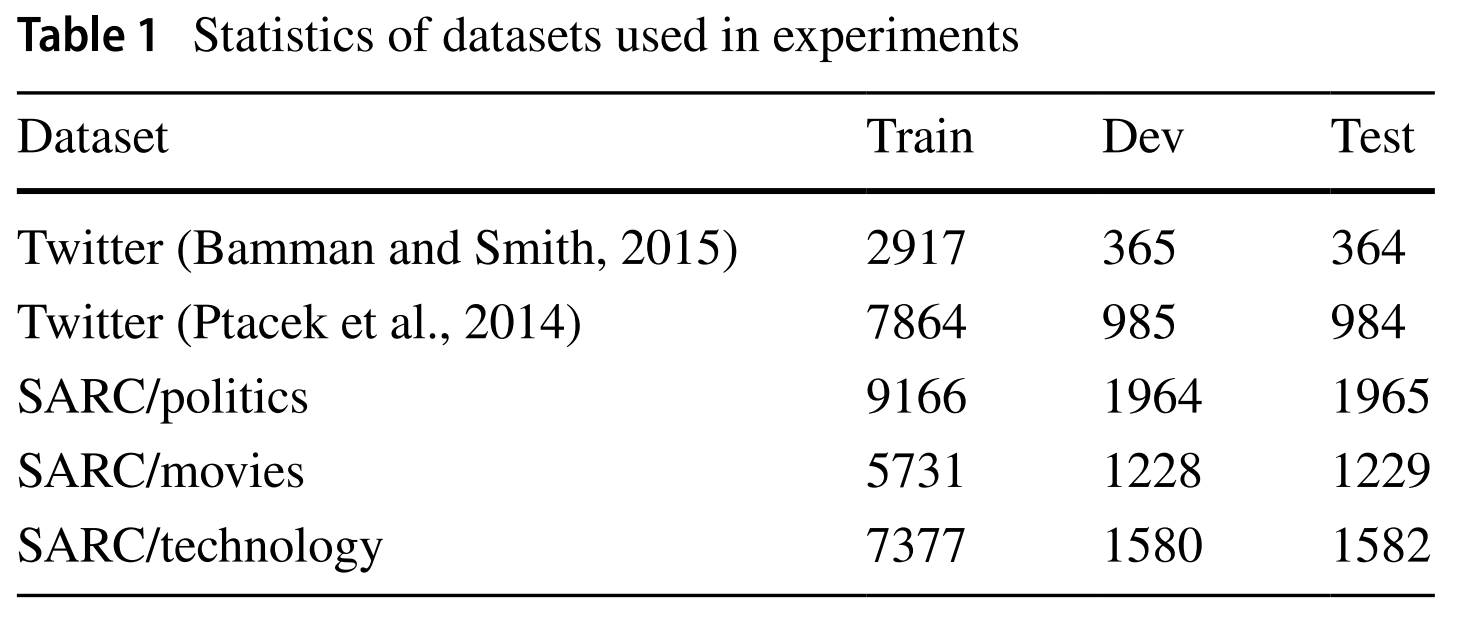
Twitter、Reddit
验证上下文的情感不协调作为讽刺特征在不同主题上是普遍存在的。
📏 评估指标:
📉 优化器&超参数:
💻 实验设备:
所有实验均使用 TensorFlow 实施。
📊 消融实验:
图6、图7
📋 实验结果:


在不同的数据集上,使用Bi-LSTM和attention结合获得的F1-score均高于LSTM模型获得的F1-score。
由此可见,一条评论是否讽刺,与发表该评论的作者有很大关系。
三种特征相结合的模型具有最好的性能。多维特征的组合可以挖掘文本的复杂特征,更有利于判断文本是否含有反讽成分。
🚩 研究结论:
本文提出了一种结合语义、情感和多维用户信息的讽刺检测框架。首先,使用 CNN 提取评论的语义特征。然后,将影响上下文的不一致信息添加到词嵌入模型中。将得到的词向量作为CNN的输入,获取评论的情感特征。随后,利用Bi-LSTM结合常识情感和注意力,提取评论中特定用户的表达特征。最后,通过神经网络对三个维度的信息进行拼接和训练。在多个标准数据集上对所提出的模型进行了评估,结果表明,与其他先进方法相比,所提出的模型取得了显着的改进。
📝 总结
💡 创新点:
本文提出了一种采用双通道结构设计的神经网络模型,将情感背景和个人表达习惯结合到讽刺检测中。对于讽刺这样的细粒度情绪,添加常识可以提高模型的预测能力。
基于卷积神经网络(CNN)的情感上下文不一致特征嵌入方法,可以综合提取目标上下文的语义和情感特征。
基于双向LSTM(Bi-LSTM)方法的模型,结合常识和注意力机制,全面表征用户表达习惯的特征。
⚠ 局限性:
🔧 改进方法:
🖍️ 知识补充:
SenticNet 和 AffectiveSpace 是将常识纳入长短期记忆 (LSTM) 模型的依据。
之前使用基于深度学习的模型来检测讽刺的研究中使用了两种方法,其中包括分析对话上下文以及分析用户的评论和心理状态。
自然语言工具包(NLTK)是一种自然语言情感分析工具,用于分别预测r和c的情感极性。
HTanh它的优点是计算成本略低(与双曲正切相比),而泛化保持不变[31]。
与Word2vec[33]相比,Glove具有更快的训练速度和良好的性能。
卷积运算通常用于合成 n-gram 信息[34]。
LSTM[14]由于其在序列建模方面的优异性能而被广泛应用于文本挖掘。为了解决长期依赖问题,LSTM 架构引入了一个可以长时间保存单元状态的存储单元。
[38]中使用的哨兵向量,允许模型灵活地决定是否关注这一常识。
根据阿米尔的研究[3],不同用户表达的同一句话可能具有不同的讽刺意义。
💬 讨论:
所提出的方法对于不同的 SARC 主题数据集表现出不同的分类性能。对于政治主题,性能提升较小,而对于电影和技术主题数据集,性能提升明显。究其原因,在于不同的题材具有不同的讽刺特征。
这篇关于Sarcasm detection论文解析 |基于情感背景和个人表达习惯的有效讽刺检测方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





