本文主要是介绍使用memcache 和 redis 、 实现session 会话复制和保持,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、NoSQL介绍
NoSQL是对Not Only SQL、非传统关系型数据库的统称
NoSQL一词诞生于1998年,2009年这个词汇再次提出指非关系型、分布式、不提供ACID的数据库设计模式
随着互联网时代的数据爆发时增长、数据库技术发展的日新月异,要适应新的业务需求,大数据技术中的NoSQL也同样重要
NoSQL分类
KV型(key-value):性能好(O1),如redis memcached(优势:数据的存储和缓存写入内存当中去)
文档数据库(Document):mogodb(索引、分片机制作为导向,所以其很适合关联大数据领域,搜索领域)、CouchDB、ES(分布式、restful风格的搜索和数据分析引擎)
Column Store列存数据库:HBase、Cassandra、大数据领域应用广泛
Graph DB数据库:Neo4j
Time Series(时序数据库):InfluxDB Prometheus
Memcached
Memcached只支持能序列化的数据类型,不支持持久化,基于key-value的内存缓存系统
memcached虽然没有像redis具有数据持久化功能,但是可以通过做集群同步的方式,让Memcached服务器的数据进行同步,从而实现数据的一致性,即保证各memcached的数据是一样的,即使又任何一台memcached发生故障,只要集群中有一台memcached可用就不会出现数据丢失。当其他mem加入集群,可以从已有的mem中自动获取数据并提供服务。
memcached借助了操作系统的Libevent工具做高效的读写,其支持动I/O。libevent是个程序库,它将Linux的epoll、BSD类操作系统的kqueue等事件处理机制封装成统一的调用接口。即使对服务器的连接数量增加,也能发挥高性能。mem适应这个库,可以在Linux、BSD、Solaris等操作系统上发挥其高性能。
memcached支持最大的内存存储对象为1M,redis可达512M(不代表其内存缓存为1M),超过1M的数据可以使用客户端压缩或拆分放到多个KEY中,比较大的数据在进行读取的时候需要消耗的时间比较长,memcached最适合保存用户的session实现session共享
memcached存储数据时,会申请1M的内存,把该内存称为一个slab,也称为一个page
memcached支持多种开发语言,包括JAVA C PYTHON C# PHP Ruby Perl等
相同键值对数据库Redis和Memcached的比较
数据结构:
Redis:哈希、列表、集合、有序集合、消息队列 memcached:纯key-value
是否支持持久化:
Redis:支持 memcached:不支持
是否支持高可用:
Redis:支持,也支持读写分离、主从复制,官方还有集群管理功能,能实现主从监控、故障转移,无需人工干预。 memcached:不支持,但可以二次开发。
存储容量:
Redis:最大512M memcached:最大1M
内存分配:
Redis:临时申请,可能导致碎片 memcached:预分配内存池,节省内存分配时间
单机QPS:
Redis:10w memcached:60w
memcached工作机制
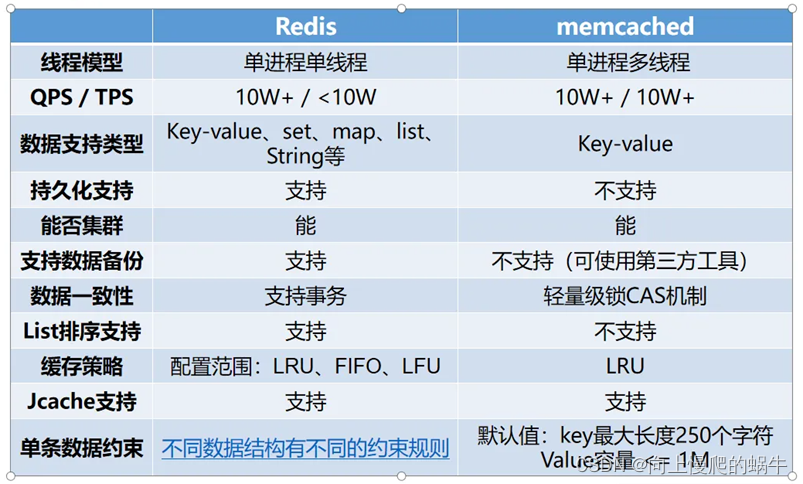
①:Memcached内存分配机制
应用程序运行时需要使用内存存储数据,但是对于一个缓存系统来说,申请内存、释放内存将十分频繁,非常容易导致大量的内存碎片,最后导致无连续内存可用。
memcached采用了slab Allocator机制来分配和管理内存。
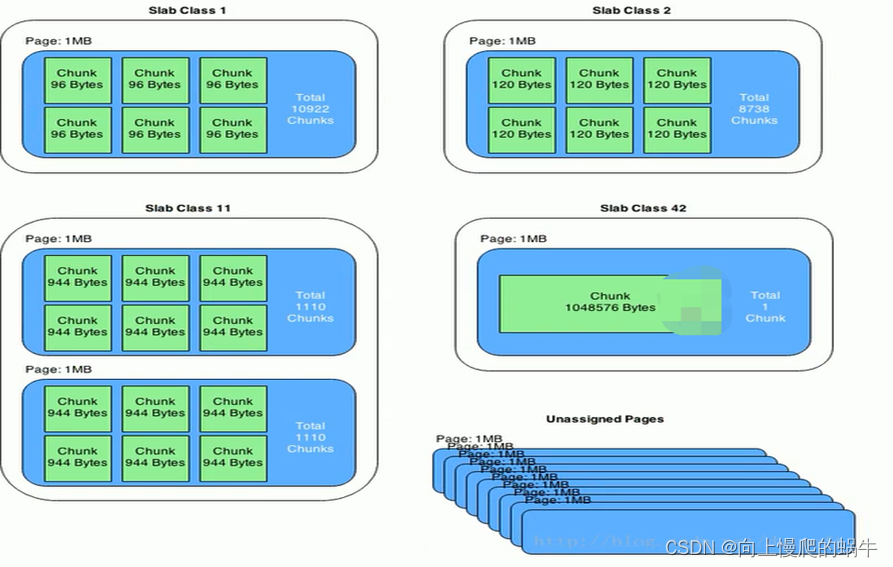
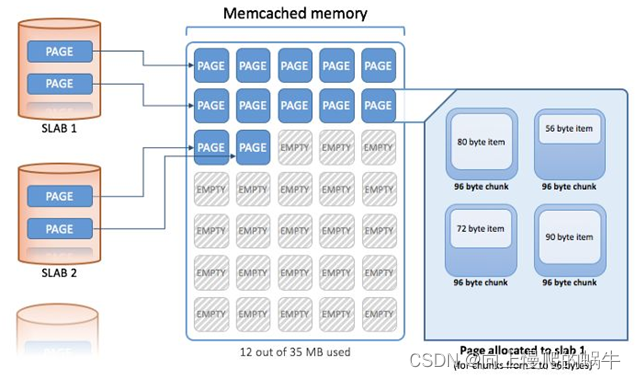
Page:分配给slab的内存空间,默认为1M,memcached中存储数据的最大单位。分配后就得到了一个slab,slab分配之后内存按照固定字节大小等分成chunk
Chunk:内存块,用于缓存记录K/V值的内存空间。Memcached会根据数据大小选择存到哪一个chunk中,假设chunk有128byte、64byte等多种,数据只要100byte存储在128byte中,存在少许浪费。
chunk最大就是Page的大小,即一个Page中就一个chunk
Slab Class:Slab按照chunk的大小分组,就组成了不同的Slab Class,diyige Chunk大小为96B的Slab为Class1,Chunk 120B为Class 2,如果有100bytes要存,那么Memcached会选择下图中Slab class 2存储,因为它是120byte的chunk。slab之间的差异可用使用Growth Factor(增长因子)控制,默认为1.25。


②:缓存清理机制
缓存过期并且访问只是才会清理缓存,不会主动清理缓存(懒过期机制)
提取出stats的指标:
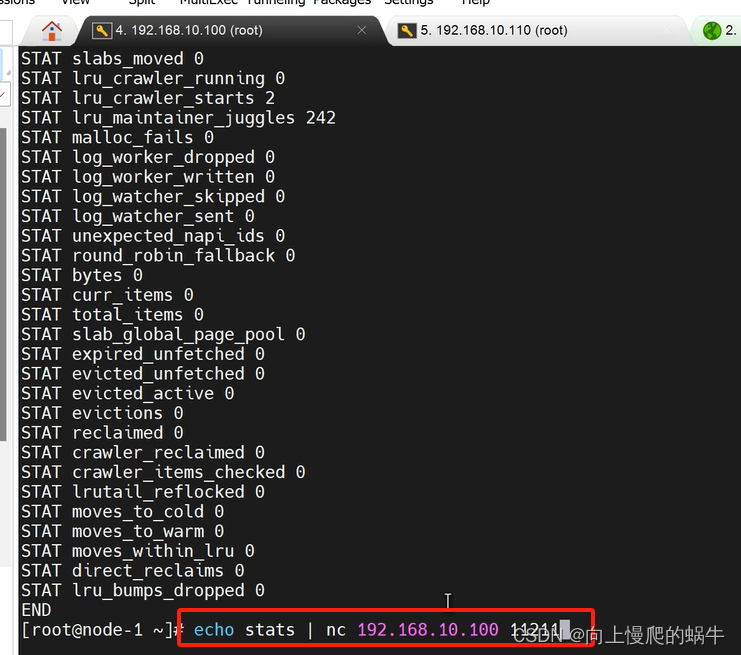

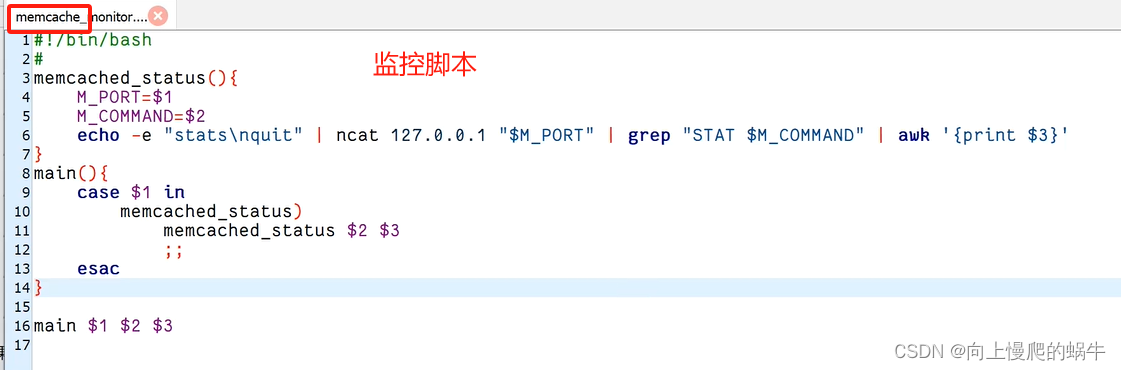
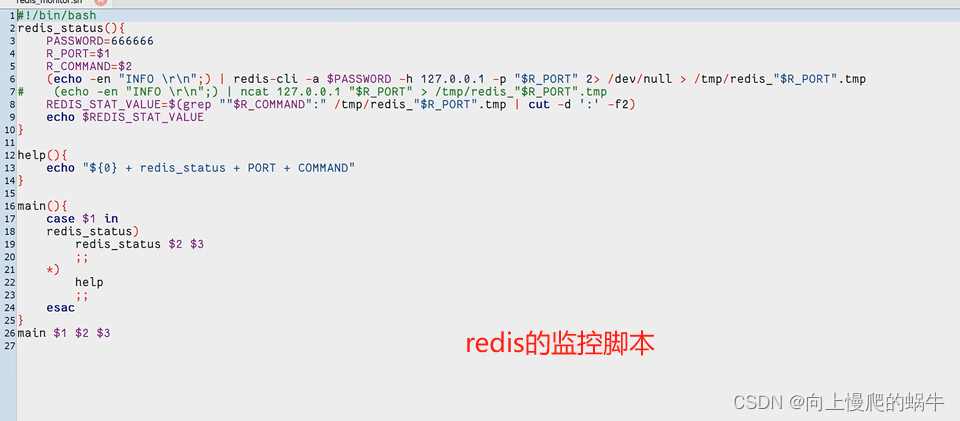 memcached安装
memcached安装
1:yum安装
yum -y install memcached
配置文件:/etc/sysconfig/memcached

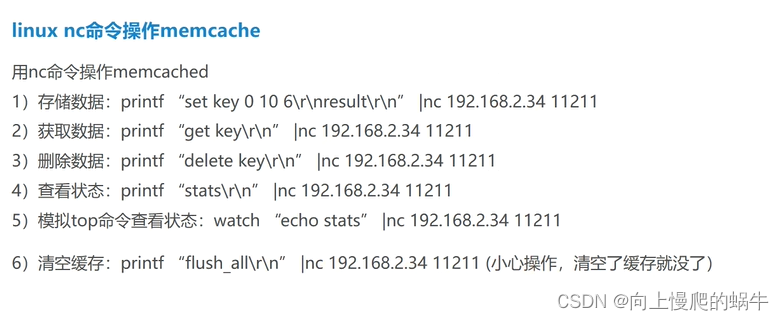
2:memcached简单命令操作
stats set add replace get delete
连接测试

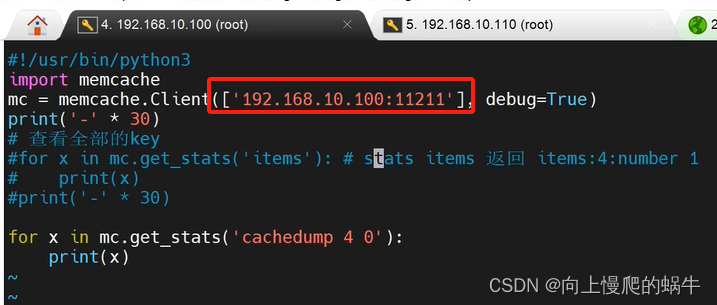
Python3连接memcached
apt-get update
apt install python3-pip -y
pip3 install python3-memcached
3:memcache高可用(需要基于第三方解决方案)
memagent高可用 反向代理memcached
二、memcache实现session会话复制和保持
基于集群,将tomcat的会话信息保存至memcached中,可用基于两种模式
sticky模式(tomcat和memcached有关联关系)

 【注】:适用于相对规模小的模式下。
【注】:适用于相对规模小的模式下。

t1 和 m1 在一台机器上 t2 和 m2 在一台机器上 t1 的会话存储在 m2 上 t2 的会话 存储在 m1 上 交叉存储 因为在同一个机器 因此 如果一个机器坏掉 另一个 msm 也会顶上 进行保持会
non-sticky模式(tomcat和memcached没有关系,tomcat自身不需要存放任何session信息)
SetupAndConfiguration · magro/memcached-session-manager Wiki · GitHub

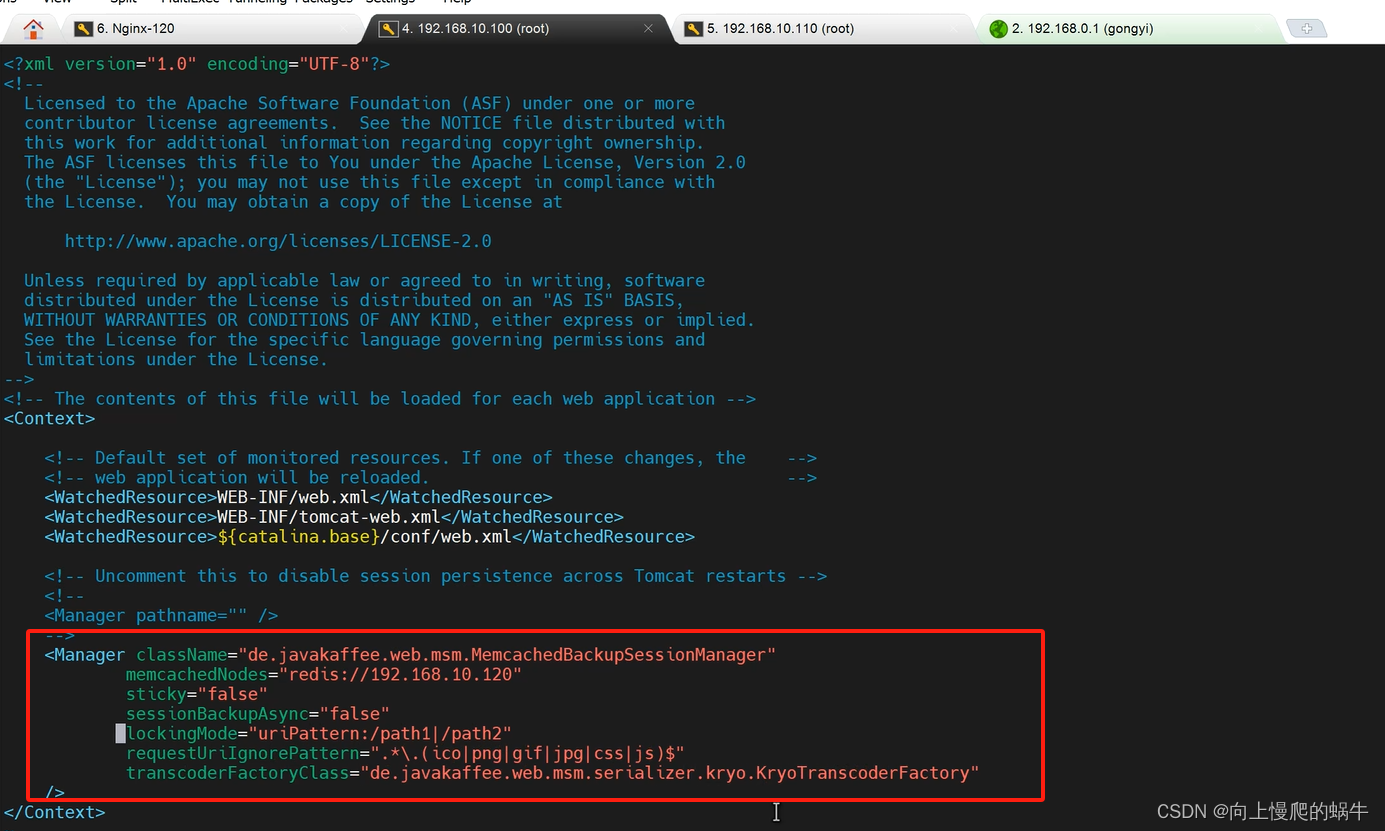
【注】:kryo版本有严格的要求。
安装tomcat和memcached
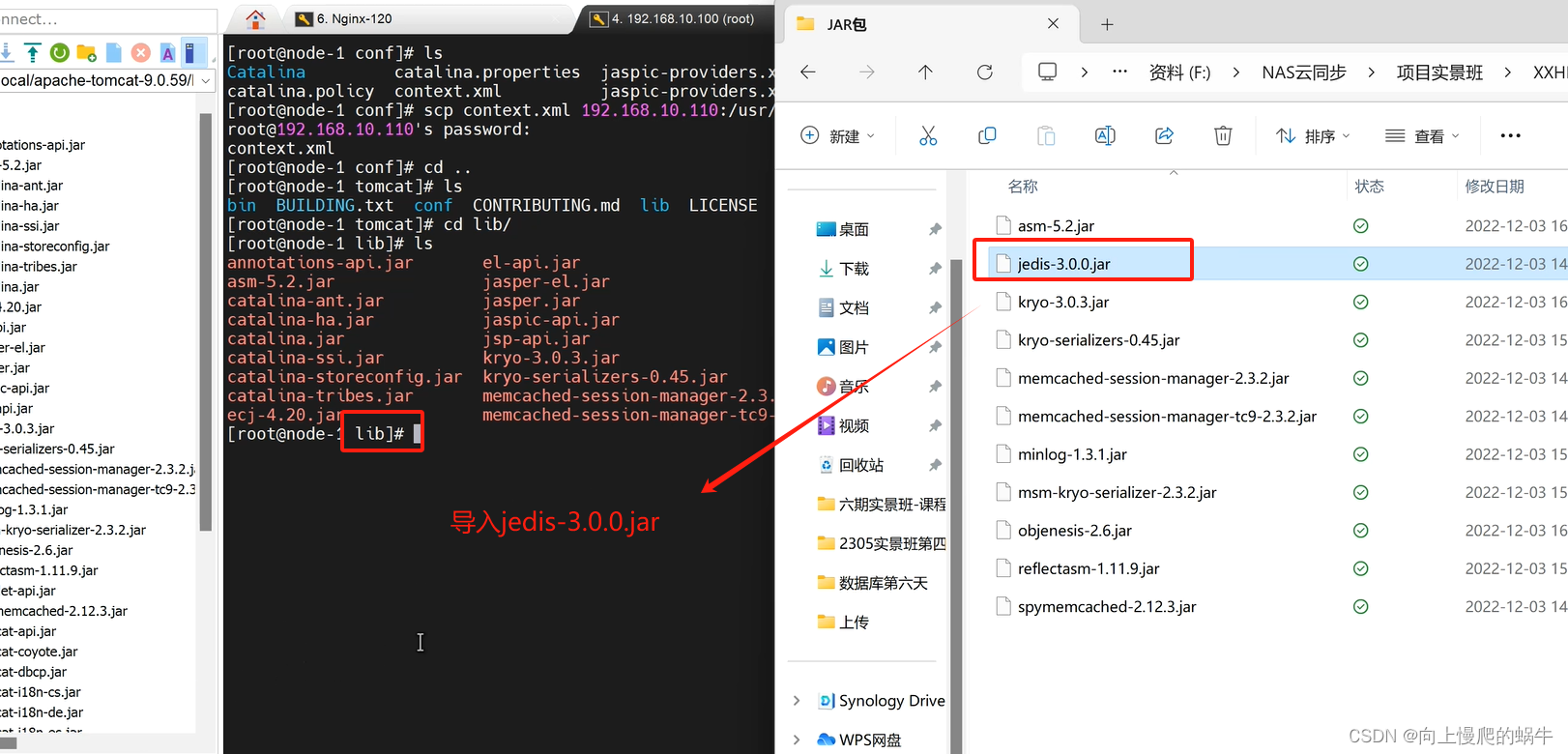
将所有的jar包放置tomcat的库目录,并修改context.xml

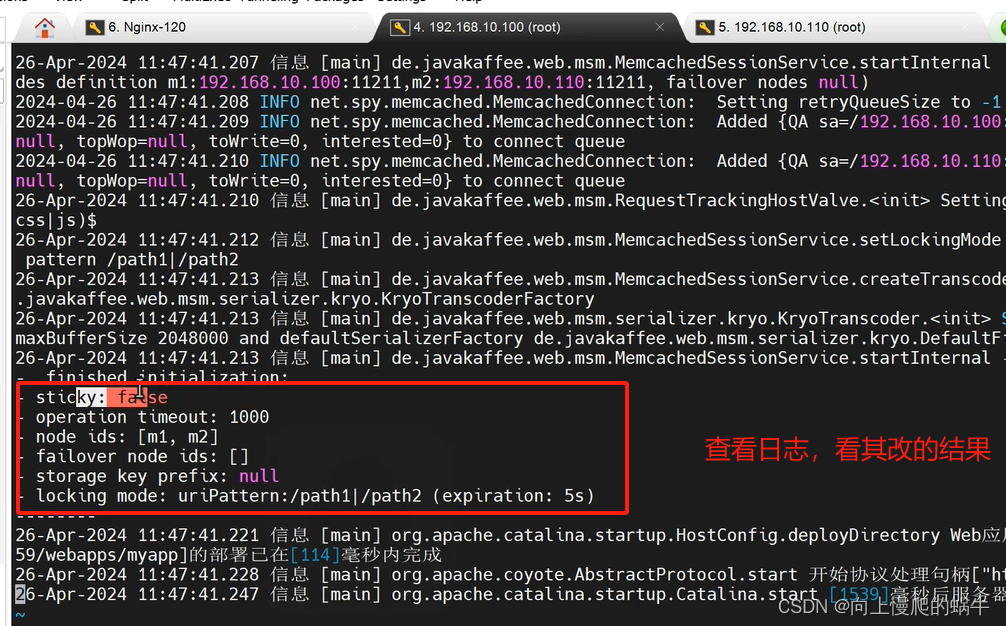
启动memcached服务,查看session会话
尝试故障一台memcache,查看会话故障迁移效果。
2:non-sticky模式
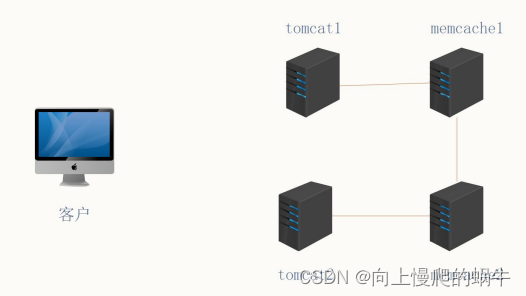
会话进行访问 会存储到内存中 自己是异步的 但是这里选择同步 异步就是在空余时 间在复制 这里直接复制到另一个 memcache 中 即使她宕机 另一个机器也能
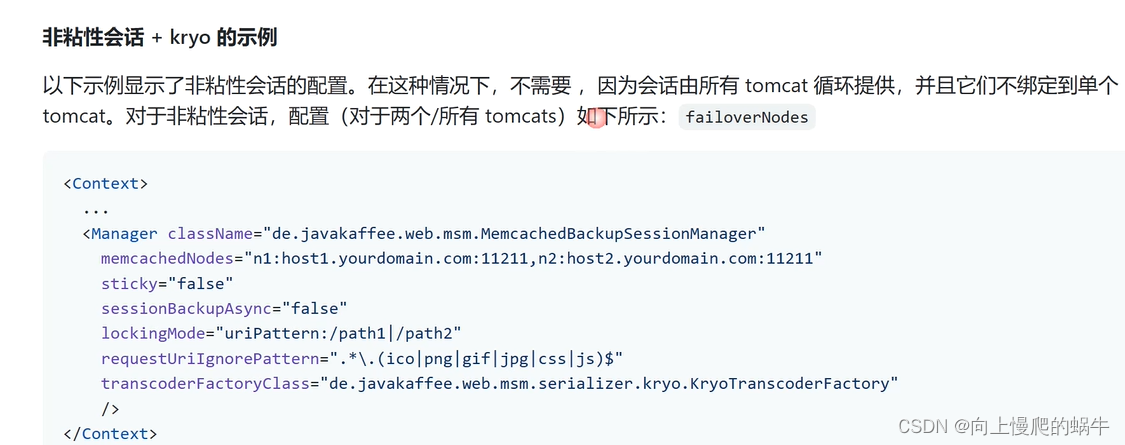
tomcat自身不存任何session信息,完全依赖于后端数据库缓存。(其默认做异步,为了数据不丢失,禁止其做异步:sessionbackupasync=false)


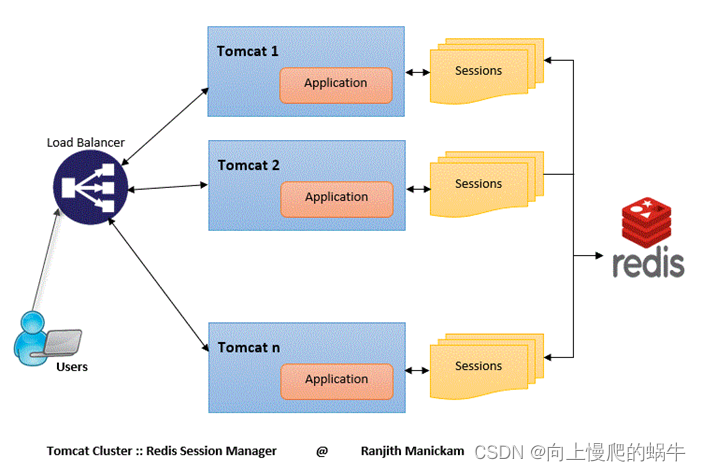
3:使用Redis实现tomcat的session会话保持
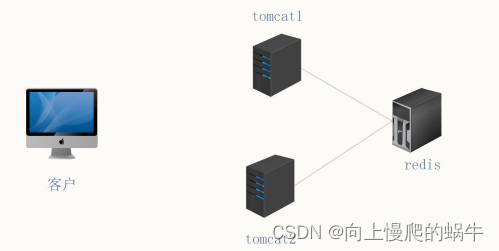
Redis 对会话记录进行管理 当有会话访问以后 会存储到内存中 同时他在异步的情况下 会将会话存储到硬盘中 这里选择的
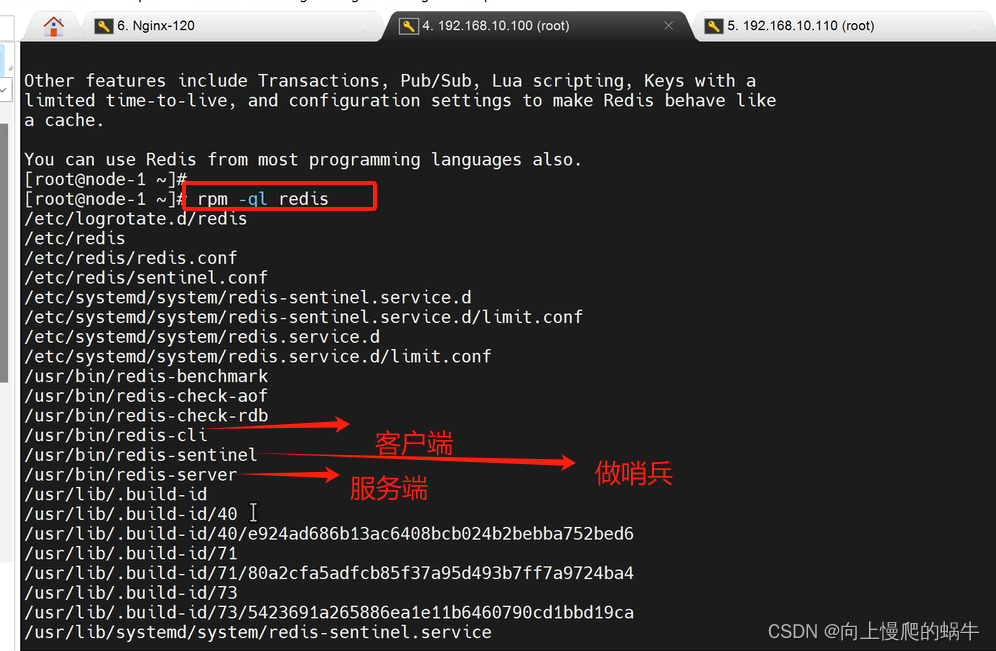
基于epel源安装redis
yum -y install redis
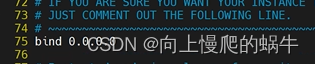
更改配置文件:
Home · ran-jit/tomcat-cluster-redis-session-manager Wiki · GitHub

这篇关于使用memcache 和 redis 、 实现session 会话复制和保持的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



