本文主要是介绍场景文本检测识别学习 day08(无监督的Loss Function、代理任务、特征金字塔),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
无监督的Loss Function(无监督的目标函数)
- 根据有无标签,可以将模型的学习方法分为:无监督、有监督两种。而自监督是无监督的一种
- 无监督的目标函数可以分为以下几种:
- 生成式网络的做法,衡量模型的输出和固定的目标之间的差距,主要考虑输入数据是怎么分布的,即 “给定Y,如何生成X”。如auto-encoder:输入一张干扰过的图,通过编码器-解码器,然后得出一张还原后的图,通过对比原图和生成的还原后的图之间的差异
- 判别式网络的做法,衡量模型的输出和固定的目标之间的差异,主要考虑输入和输出的映射关系,不考虑输入数据是怎么分布的,即 ”给定X,预测Y“ 。如eight positions:将一张输入图片分成九宫格,按顺序标好序号,并给中间的5号格,然后随机在剩下的格中挑一个,预测出这个随机的格是在中间格的哪一个方位
- 对比学习的做法:在一个特征空间中,衡量各个样本对之间的相似性,从而达到,相似的物体之间的特征尽量接近,不相似的物体之间的特征尽量远,如有三张图片,两张人和一张狗,对比学习只需要区分出两张人的图片是相似的,一张狗的图片是单独的即可,而不需要区分出它们分别是人和狗。对比学习和生成式网络、判别式网络的区别:后两者的目标都是固定的目标(找到一个能很好表示原图像,或输入图像的特征空间,这个特征空间是固定的),但是对比学习的目标是在训练过程中不断改变。(不断优化特征空间,来让正样本对更加接近,负样本对更加远离)
- 对抗学习的做法:衡量两个概率分布之间的差异,即生成数据分布和真实数据分布的差异。对抗学习包含两个模型:生成模型和判别模型。生成模型的任务是尽可能生成接近真实数据分布的数据样本,判别模型的任务是区分输入的样本是真是数据集还是来自生成模型的。对抗学习可以用来做无监督数据生成,特征学习。
代理任务

- 如果有一个输入X,通过一个模型,得到Y
- 那么在有监督学习中,我们是通过真实值GT和Y进行比较,并通过一个目标函数(Loss Function)来衡量这个比较的结果
- 在无监督学习中,由于没有GT的存在,那么就需要自己造一个GT。主要是通过代理任务来生成一个自监督的信号,用来充当GT,之后仍然是将GT和Y进行比较,并通过一个目标函数(Loss Function)来衡量这个比较的结果
特征金字塔、图像金字塔
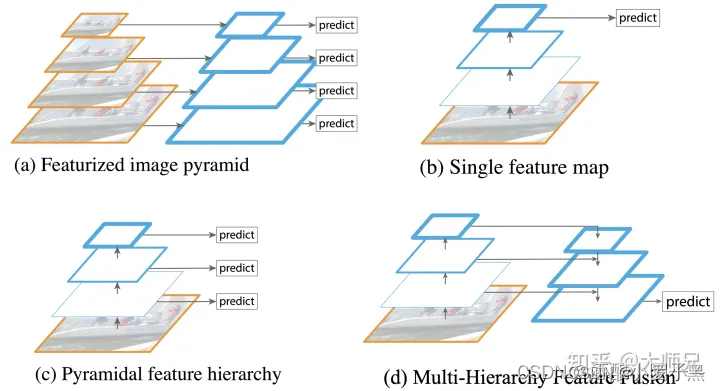
- (a) 是图像金字塔,通过将输入图像缩放到不同的尺度来构成了图像金字塔。然后将这些不同不同尺度的图像输入到模型中(可以共享权重,也可以独立权重),最后得到每个尺度的预测结果。图像金字塔的问题是:推理速度慢,因为每张输入图像都要推理很多遍
- (b) 是Faster R-CNN、YOLO算法的网络结构,只使用CNN的最后一层的结果用作预测。这个结构的问题在于:对小尺寸物体的预测效果不理想,因为小尺寸的物体特征回随着卷积层的加深快速流失,到最后一层只有很少的特征支持小尺寸物体的预测了。
- © 是SSD采用的结构,使用不同层的Feature Map来预测,但是SSD只是单纯的从每一层都输出一个预测结果,并没有进行不同层之间的特征复用和特征融合。
- (d) 是U-Net的结构,虽然使用了不同层之间的特征复用和特征融合,但是没有使用多层预测,仍然只是在模型的最后一层进行了预测。
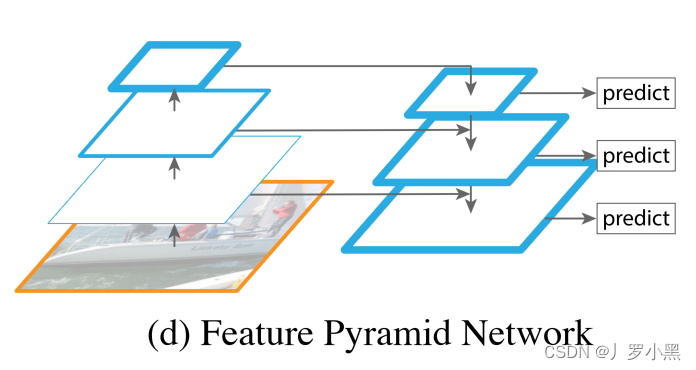
- 上图为特征金字塔网络FPN的结构,跟U-Net不相同的是,FPN在每一层都进行了输出预测。
这篇关于场景文本检测识别学习 day08(无监督的Loss Function、代理任务、特征金字塔)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


