本文主要是介绍从零开始学AI绘画,万字Stable Diffusion终极教程(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【第2期】关键词
欢迎来到SD的终极教程,这是我们的第二节课
这套课程分为六节课,会系统性的介绍sd的全部功能,让你打下坚实牢靠的基础
1.SD入门
2.关键词
3.Lora模型
4.图生图
5.controlnet
6.知识补充
在第一节课里面,我们已经掌握了SD的使用流程
其实AI绘画的本质就是通过我们写的一些词语(也就是关键词),AI生成对应的画面
如果想要生成更加好看、更加符合自己脑海里的画面的照片,就最好按标准化把关键词写好了
所以这一节课我们就来讲讲写关键词的模板
一、关键词的重要性
这是一张国足“获得”世界杯冠军的照片(非常离谱)

这是一个比人还要大的西瓜

还有这只既能自己做饭吃,还能参加巴黎时装周,走T台秀的小猫咪


还有真人写真、二次元头像壁纸、美食摄影



以上各式各样、不同风格的图,都是由AI绘画生成的
而生成这些图片,最重要的就是写好关键词
二、关键词模板
我将从以下三个部分对关键词进行讲解,看完之后,你只要套模板就能生成出好看又好玩的照片
1.格式
2.公式
3.权重
1.格式
首先要讲的是关键词的书写格式,就以这张图为例
一句话描述这张图就是“一个漂亮的女生站在森林里”

把这句话变成关键词可以有三种格式
第一种就是直接把这句话当成关键词:一个漂亮的女生站在森林里
第二种是拆成词组:一个漂亮的女生,站在森林里
最后一种就是直接拆分成一个个单词:一个女生,漂亮,站着,森林
这也是我们最常用的一种
因为SD只能识别英语,所以我们要把这些中文关键词翻译成英语
句子:A beautiful girl standing in the forest
词组:A beautiful girl,Standing in the forest
单词:A girl, beautiful, standing, forest
需要特别注意的是,这些单词和单词之间要用英文状态下的逗号分隔开
2.公式
我给大家总结出来了一个写关键词的公式,按照这个公式,写关键词就变得非常简单了
关键词公式:
画质+主体+主体细节+人物服装+其他(背景、天气、构图等)
首先画质就是一些关于画面质量的词
可以写最高质量,大师杰作、超高清画质之类,加强质量的词,这样出来的照片会更加精致
然后就开始写照片里面有什么东西,想象一下照片是什么样的
先确定照片的主体,这里我们就生成一个女生的照片
接着就是对这个主体的细节描写,包括这个人的长什么样,穿什么衣服
这里就是按照自己脑海里的画面去写,可以从头到脚想一遍这个人长什么样
最后还可以加上其他东西,背景、天气、动作姿势、构图等等
好啦,这样一套下来,我们的关键词就写的差不多了
画 质:最高质量,杰作,高清画质,丰富的细节,
主 体:一个女生,
主体细节:精致的五官,漂亮,黑色长发,卷发,大眼睛,
人物服装:白色衬衫,黑色短裙,
其 他:在公园里,坐在椅子上,树,阳光,全身照
把这一段关键词翻译成英语,复制到sd

大家可以像我这样,一行一行分开类型去写关键词,后面改词会更加方便
但一定要注意,每一行的最后也要加上英文逗号
接着按照上节课的内容,选一个二次元的大模型,设置参数
最后生成的照片是这样的,基本上都符合我们关键词的内容

3.权重
当我们在SD里出的图多了,我们慢慢会发现一个问题
明明我们的关键词里写了人物的某个特征,或者需要画面出现的东西
可生成出来的照片就是没有体现出来我们要的东西
就比如下面这张照片
明明关键词里写了卷发,但是照片却没有卷发,这时候该怎么办呢
怎样才能让SD注意到“卷发”这个关键词
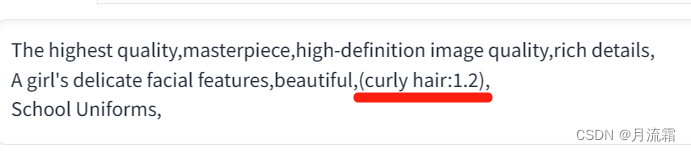
The highest quality, masterpiece, high-definition image quality, rich details,
A girl's delicate facial features, beautiful, curly hair,
School Uniforms
最高质量,杰作,高清画质,丰富的细节,
一个女生精致的五官,漂亮,卷发,
学校制服

那就是给关键词加权重,让这个词变得更加重要
默认情况下,一个关键词的权重是1
比如我们直接输入“curly hair(卷发)”这个关键词,那现在它的权重就是1
如果我们给关键词加一个括号,变成:(curly hair)
这时候“卷发”的权重就变成了1.1
如果想要调更高数值,我们不用继续加括号
只要在在关键词后面加冒号,再加上一个数值就可以了,现在就变成了:(curly hair:1.2)
这个时候“卷发”的权重就是1.2
这样生成的照片里面就有很明显的卷发了

如果你想减权重,就对应把数值改成1以下就行
例如变成:(curly hair:0.9)、(curly hair:0.8)
那关于关键词该怎么写、格式以及权重的内容都已经讲完了
如果你还不知道写些什么
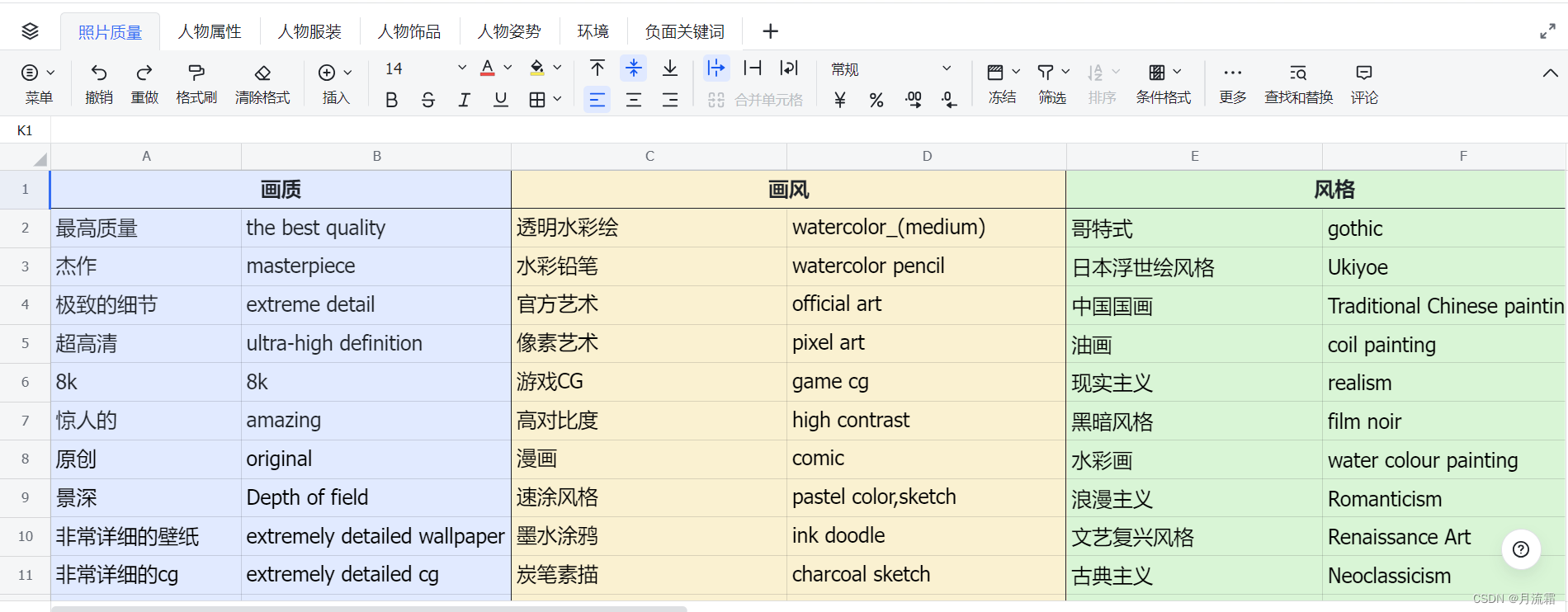
这里我也给大家整理了一个常用的关键词分类,大家可以直接按照刚刚的关键词公式,在这里找到对应的关键词,具体参见文章末尾的网盘链接下载
三、关键词插件
最后,再给大家分享一个写关键词的插件
这样就可以直接在SD里面输入中文,这个插件会将我们的中文关键词自动翻译成英语

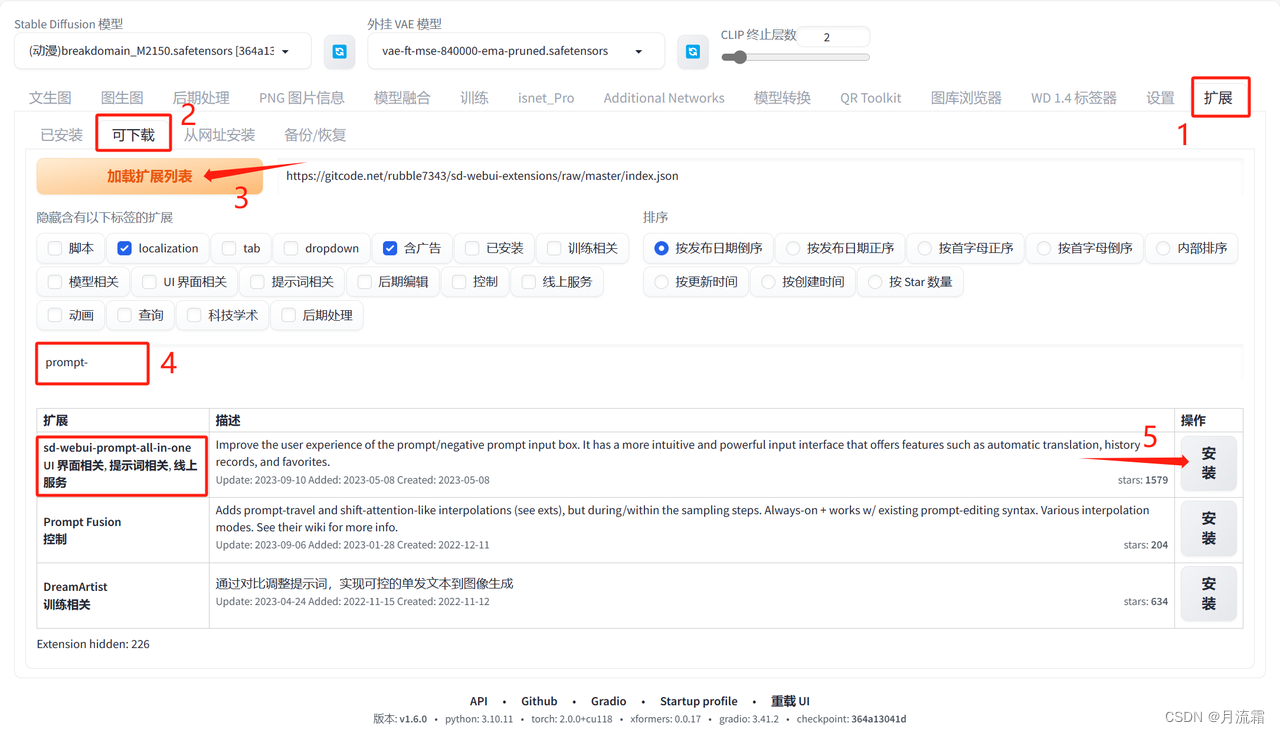
1.插件的安装方法
①在状态栏点击“扩展”
②点击“可下载”
③点击“加载扩展列表”
④在搜索框里输入“prompt-”
⑤找到对应的插件,点击“安装”
安装完了之后,点击“已安装”,然后点击“应用更改并重启”,重新打开SD

这时候就会在关键词的文本框下面看到这个插件,这样就安装好啦

2.插件的使用方法
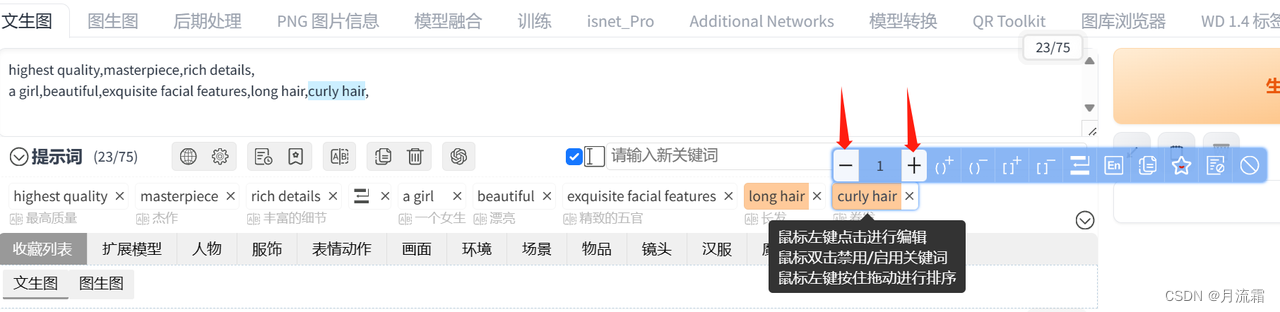
我们可以在下面小文本框里直接输入中文,敲回车键就会变成英语关键词
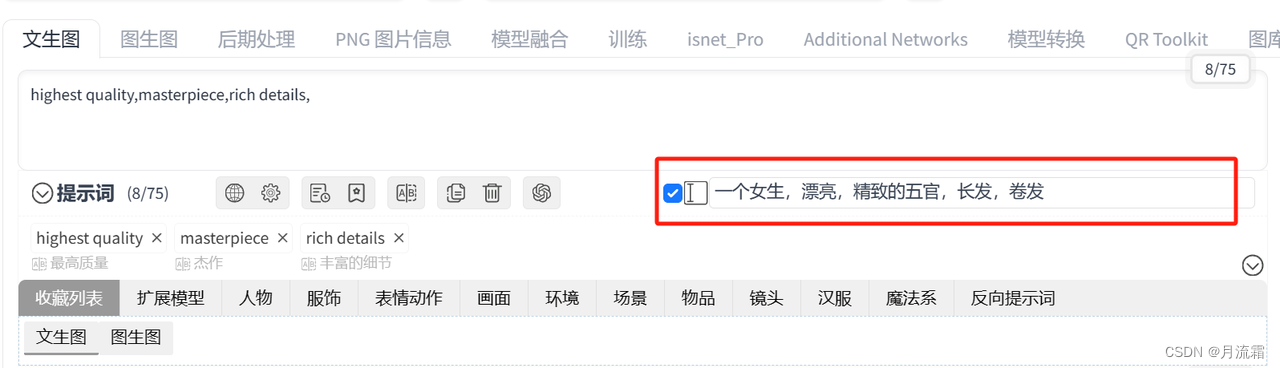
如果要给某个词加权重,就把鼠标放到这个词上面,点击加减号可以直接加减权重
四、结尾
好啦,最后总结一下我们这节课的内容
关键词的万能模板:
-
格式:关键词用英文输入,单词之间用英文逗号分隔开
-
公式:画质+主体+主体细节+人物服装+其他(背景、天气、构图等)
-
权重:加减权重的方法:(关键词:数值)
以上就是关于关键词模板的内容
网盘链接:https://pan.baidu.com/s/1X9u5u9-cFR-j3LLEMM6xCQ?pwd=vfpa
提取码:vfpa
这篇关于从零开始学AI绘画,万字Stable Diffusion终极教程(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!