本文主要是介绍Python多进程程文件去重,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
注:本文基于python2.7.5
用完多线程,必然得尝试下多进程咯。
python下多进程一般通过multiprocessing模块实现,和上篇一样,我们还是以图片去重为例。
#-*- coding: UTF-8 -*-import multiprocessing
from multiprocessing import freeze_support
import os
import sys
import hashlib
import timedef run_process(name, ph, md5, id, lockForPhoto, lockForMD5, lockForIdentical, LockForPrint):LockForPrint.acquire()print("starting: process" + str(name)) LockForPrint.release()lockForPhoto.acquire()while len(ph) > 0:photo = ph.pop()lockForPhoto.release()photomd5 = getmd5(photo)lockForMD5.acquire()if photomd5 not in md5:md5.append(photomd5)lockForMD5.release()else:lockForMD5.release()lockForIdentical.acquire()id.append(photo)lockForIdentical.release()lockForPhoto.acquire()lockForPhoto.release()def getmd5(file):if not os.path.isfile(file): return f = open(file,'rb')md5 = hashlib.md5()md5.update(f.read())f.close()return md5.hexdigest() def getFiles(targetDir):allfiles = multiprocessing.Manager().list()for path,dir,filelist in os.walk(targetDir):for filename in filelist:allfiles.append(os.path.join(path, filename))return allfilesif __name__ == '__main__':#freeze_support()#windows平台下需要增加这个语句,不然可能会出现崩溃dirname = sys.argv[1]if len(sys.argv) == 3:identicalDir = sys.argv[2]else:identicalDir = ""identicalPhotoes = multiprocessing.Manager().list()photoMd5List = multiprocessing.Manager().list()photoes = multiprocessing.Manager().list()lockForPhoto = multiprocessing.Lock()lockForMD5 = multiprocessing.Lock()lockForIdentical = multiprocessing.Lock()LockForPrint = multiprocessing.Lock()processes = []photoes=getFiles(dirname)start = time.time()for i in range(4):process = multiprocessing.Process(target=run_process, args=(i+1, photoes, photoMd5List, identicalPhotoes, lockForPhoto, lockForMD5, lockForIdentical, LockForPrint))process.start()processes.append(process)for process in processes:process.join()end = time.time()last = end - startprint("There are " + str(len(identicalPhotoes)) + " identical photo(es)")if os.path.exists(identicalDir):for i in identicalPhotoes:shutil.move(i, identicalDir)print(i.decode('gbk'))print("main Process exit: lasts for " + str(last) + "s")
功能不变,脚本接收两个入参,一个是需要去重的文件目录(必须),另一个是存放重复文件的目录(可选)。如果没有指定存放重复文件的目录,则不移动重复文件,仅打印重复文件数量。
多进程的实现主要通过multiprocessing模块操作,multiprocessing的Process函数,接收子进程主体函数,以及函数入参用于创建新的进程,之后便进入新进程的代码中运行。
多进程相比于多线程有个不同的地方,应该在代码里也能发现写端倪,就是对于数据的共享。
在线程中,数据共享通过全局变量即可。因为线程没有自己的系统资源,它与其他线程共享系统分配的资源,比如文本区和数据区。而在进程中,每个进程都有自己的数据空间,所有的资源都会从父进程中拷贝一份,因此使用全局变量并不能真正实现全局,因为子进程已经把这个全局变量也拷贝到子进程中,因此全局变量只能称之为进程内全局变量。为了解决进程间的数据共享,我们引入了multiprocessing的Manager()模块。Manager()返回的manager对象控制了一个server进程,此进程包含的python对象可以被其他的进程通过proxies来访问,从而达到多进程间数据通信且安全。Manager支持的类型有list,dict,Namespace,Lock,RLock,Semaphore,BoundedSemaphore,Condition,Event,Queue,Value和Array。
完成了进程间的数据共享,下一步就要考虑进程间数据的同步了。这里同样使用锁来保证数据同步。为每个全局资源定义一个锁,粒度小,这样对资源的占用就不会太久。
最后,在实际去重的时间上来说,多进程并不占优,如下:
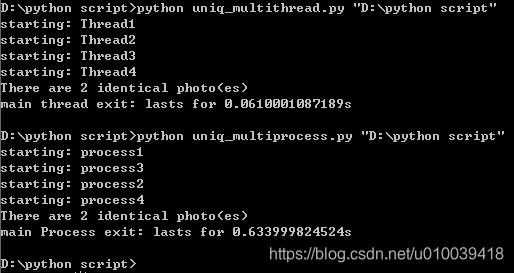
由上可见多进程和多线程相差达到一个数量级,和想象中的不太一样。不过这并不能说明多线程就优于多进程,因为这取决 于你程序的工作性质。由于本次测试数据量小,线程的创建和初始化速度肯定快于进程,因此差距才会比较明显。
其实,如果在数据量大的情况下,两者的差异主要取决于程序是计算密集还是IO密集,多进程因为可以利用多个CPU同时工作,因此对于计算密集型程序表现更好,而多线程则在IO密集的情况下表现更优,因为它可以利用IO阻塞的时间运行其他线程,而不必在那等待。
考虑到有些场景我们不可能手动去限制进程数量,尤其是如果有成百上千个进程时,因此现在我们再考虑使用进程池实现。进程池为用户提供指定数量的进程,当用户提交新的请求时,如果进程池没有满,那么就会创建一个新的进程来执行任务;如果此时进程数量已经达到指定值,就会阻塞,等待某个进程执行完毕再创建新进程执行任务。通过进程池能够很好的限制事务处理的进程数,也就限制了应用占用系统资源的数量。进程池这一功能主要由multiprocessing.Pool模块提供。
#-*- coding: UTF-8 -*-import multiprocessing
from multiprocessing import freeze_support
import os
import sys
import hashlib
import timedef run_process(name, photo, md5, id, lockForMD5, lockForIdentical, LockForPrint):LockForPrint.acquire()print("starting: process" + str(name)) LockForPrint.release()photomd5 = getmd5(photo)lockForMD5.acquire()if photomd5 not in md5:md5.append(photomd5)lockForMD5.release()else:lockForMD5.release()lockForIdentical.acquire()id.append(photo)lockForIdentical.release()def getmd5(file):if not os.path.isfile(file): return f = open(file,'rb')md5 = hashlib.md5()md5.update(f.read())f.close()return md5.hexdigest() def getFiles(targetDir):allfiles = multiprocessing.Manager().list()for path,dir,filelist in os.walk(targetDir):for filename in filelist:allfiles.append(os.path.join(path, filename))return allfilesif __name__ == '__main__':#freeze_support()#windows平台下需要增加这个语句,不然可能会出现崩溃dirname = sys.argv[1]if len(sys.argv) == 3:identicalDir = sys.argv[2]else:identicalDir = ""identicalPhotoes = multiprocessing.Manager().list()photoMd5List = multiprocessing.Manager().list()photoes = multiprocessing.Manager().list()lockForMD5 = multiprocessing.Manager().Lock()lockForIdentical = multiprocessing.Manager().Lock()LockForPrint = multiprocessing.Manager().Lock()processes = []photoes=getFiles(dirname)start = time.time()pool = multiprocessing.Pool(4)i = 0while len(photoes) > 0:i = i + 1photo = photoes.pop()pool.apply_async(run_process, (i, photo, photoMd5List, identicalPhotoes, lockForMD5, lockForIdentical, LockForPrint))pool.close()pool.join()end = time.time()last = end - startprint("There are " + str(len(identicalPhotoes)) + " identical photo(es)")if os.path.exists(identicalDir):for i in identicalPhotoes:shutil.move(i, identicalDir)print(i.decode('gbk'))print("main Process exit: lasts for " + str(last) + "s")
相比于非进程池方案,有两点改变,
1、对于总任务photoes的使用,使用进程池的思想为:如果photoes中还有照片要处理,那么创建一个进程处理这张照片(虽然为了一张照片就创建一个进程有点浪费,不过这只是实验,一般的任务不会这么简单)。因此整个过程会创建len(photoes)个进程,但同时最多只会存在4个进程,有进程池大小决定。因此总任务这个资源也就不用锁保护,因为任务分发只在主进程中进行。
2、对于锁对象的传递。由于线程池中参数传递通过pool.apply_async()函数,该函数实际操作时会将参数序列化,因此原先使用的multiprocessing.Lock()无法满足需求,如果仍然使用该变量,就无法达到锁保护左右,结果就是重复文件无法完全识别。这里需要通过multiprocessing.Manager().Lock()来创建锁变量。
我们可以实际操作一下:
>>> import multiprocessing
>>> import pickle
>>> lock = multiprocessing.Lock()
>>> lp = pickle.dumps(lock)
Traceback (most recent call last):
......
RuntimeError: Lock objects should only be shared between processes through inher
itance
>>>
对比Manager的Lock:
>>> import multiprocessing
>>> import pickle
>>> lock = multiprocessing.Manager().Lock()
>>> lp = pickle.dumps(lock)
>>>
>>>
这篇关于Python多进程程文件去重的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




