本文主要是介绍yolov5-pytorch-Ultralytics训练+预测+报错处理记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、前言
玩一段时间大模型,也该回归一下图像识别。本项目用于记录使用基于Ultralytics的yolov5进行目标检测测试。为什么用Ultralytics呢?答案有3
1、其良好的生态,方便我们部署到其它语言和设备上。因此本次测试结论:大坑没有,小坑不断~
2、对新手极度友好,只要装好依赖,按官方教程就可以运行起来。甚至export.py集成权重文件的各种转换功能比如:转ONNX文件!!
3.其对自定义数据集要求低,训练难度大减。当我们制作训练集时无需考虑吧图片压缩切割到成512x512或者640x640。只管找图标注,Ultralytics在train时会自动帮处理这些不合格尺寸的图片(爽爆了!!!)

二、简介
本篇使用的yolo5模型大小为yolov5l
由于需要识别一图片些细小的物体,我在Ultralytics的yolov5添加了一些注意力机制,但本次不会展开说,因为添加注意力前后对我们训练和预测的操作流程都没有任何影响。
三、训练
1.数据准备
也不知道是该夸还是该骂( ̄ェ ̄;)
Ultralytics提供了许多训练集数据格式,可以VOC、COCO、SKU等等。
但是label的数据格式不是xml而是txt…额…这就有些坑爹了▄█▀█●
以下我只选用其中一种格式:VOC实现
我采集数据文件夹取名MY_DataSet
(1)数据格式如下:
MY_DataSet
├── images└── train└── val
└── labels└── train└── val
└── dataset.yaml
(2)labels里数据的格式:
labels/train里的文件如下:

txt内容如下:

参考图图片如下:

即数据格式为:种类、x、y、w、h
通过以下方法可以使xml格式转成txt
def convert_annotation(voc_name,image_set,image_id):in_file = open('data/%s/Annotations/%s.xml' % (voc_name,image_id), encoding='utf-8')out_file = open('data/%s/labels/%s/%s.txt' % (voc_name,image_set,image_id), 'w', encoding='utf-8')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').text# difficult = obj.find('Difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))b1, b2, b3, b4 = b# 标注越界修正if b2 > w:b2 = wif b4 > h:b4 = hb = (b1, b2, b3, b4)bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')(3)dataset.yaml内部如下:
train: 本文件夹相对于trian.py文件的位置/MY_DataSet/images/train
val: 本文件夹相对于trian.py文件的位置/MY_DataSet/images/val
nc: 4
names: ['华强','西瓜','刀子','背带裤']
(4)修改模型yaml文件
到Ultralytics项目下的models文件夹找到对应yolo5l.yaml文件打开它将
nc: 80 # number of classes
改成你识别类的总数即可,我这只有4类改成4即可。
nc: 4 # number of classes
2.训练
在安装好Ultralytics的yolo5l.yaml和配置好训练数据后运行代码
python train.py --img 512 --batch 16 --epoch 300 --data dataset.yaml的相对位置 --cfg models/yolov5l.yaml --weights yolov5l.pt的位置
即可!!开始训练
四、预测
默认会保存在项目的runs/train/exp/weights/文件夹中
python detect.py --weights runs/train/exp/weights/best.pt --data 训练集dataset.yaml的相对路径 --source 图片路径
五、报错处理
-
assert nf > 0 or not augment, f"{prefix}No labels found in {cache_path}, can not start training. {HELP_URL}"
答:yolov5的数据集里标签格式为.txt,而我的自定义数据集是.xml格式,总而言之,我们要按官方的数据格式来,不能按以前传统的xml来弄。 -
卡主并显示
Downloading https://ultralytics.com/assets/Arial.Unicode.ttf to/root/.config/Ultralytics/Arial.Unicode.ttf...
答:初次运行,yolo5会检测你在/root/.config/Ultralytics的目录下是否有Arial.ttf 文件在,如果没有该文件,它会自动下载给你安装给你安装。由于需要连接该比较耗时。建议直接去网上下载文件
https://ultralytics.com/assets/Arial.Unicode.ttf
如果下载失败也可用我下载的文件,然后放到对应目录下即可。
- NotImplementedError(“cannot instantiate %r on your system”
NotImplementedError: cannot instantiate ‘PosixPath’ on your system
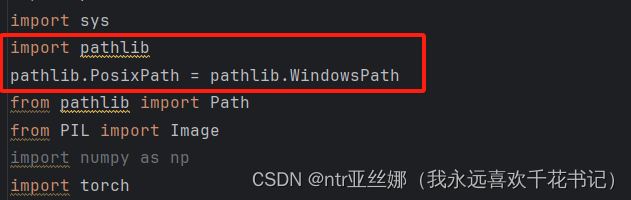
答:这个是在windows运行时会报的问题。在from pathlib import Path前插入如下代码即可
import pathlib
pathlib.PosixPath = pathlib.WindowsPath
注意:如果要弄到到Linux时,记得把这两行删了
六、结语
训练+预测至此结束咯~~

这篇关于yolov5-pytorch-Ultralytics训练+预测+报错处理记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








