本文主要是介绍深浅复制详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
浅复制:
复制列表,默认做的就是浅复制。如果所有元素都是不可变的,那么使用浅复制没有问题,还能节省内存。
问题如下:列表元素是可变的,复制时,默认做浅复制。list2中的列表和list1中的列表指向同一个列表,元组也是。当对list1或2中的列表进行删除或追加的时候,操作的是同一个引用对象。元组+=操作则会创建一个新元组。
list1 = [3, [66,44, 55], (7, 8, 9)]
list2 = list(list1)
list1.append(100) #对list2没有影响
print('1:', list1)
print('2:', list2)
list1[1].remove(55) #对list2有影响,因为list2[1]与list1[1]绑定的是同一个列表。
print('1:', list1)
print('2:', list2)
list2[1] += [33, 22] # 就地操作
list2[2] += (10, 11) # 元组 += 运算符会创建一个新元组
print('1:', list1)
print('2:', list2)结果:
1: [3, [66, 44, 55], (7, 8, 9), 100]
2: [3, [66, 44, 55], (7, 8, 9)]
1: [3, [66, 44], (7, 8, 9), 100]
2: [3, [66, 44], (7, 8, 9)]
1: [3, [66, 44, 33, 22], (7, 8, 9), 100]
2: [3, [66, 44, 33, 22], (7, 8, 9, 10, 11)]list2复制list1后状态如下:
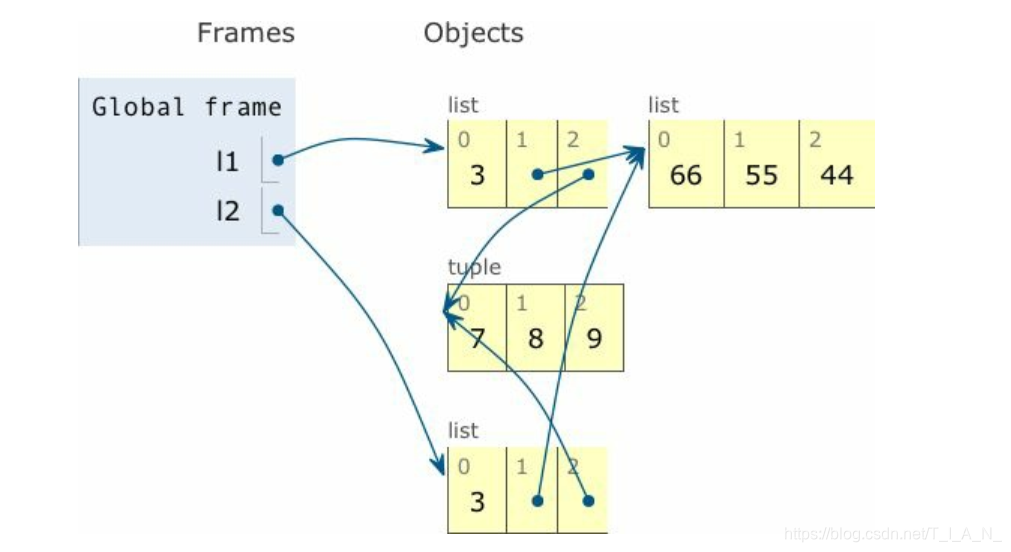
上图是执行 list2 = list(l1) 赋值后的程序状态。list1 和 list2指代不同的列表,但是二者引用同一个列表 [66, 55, 44] 和元组(7, 8, 9)
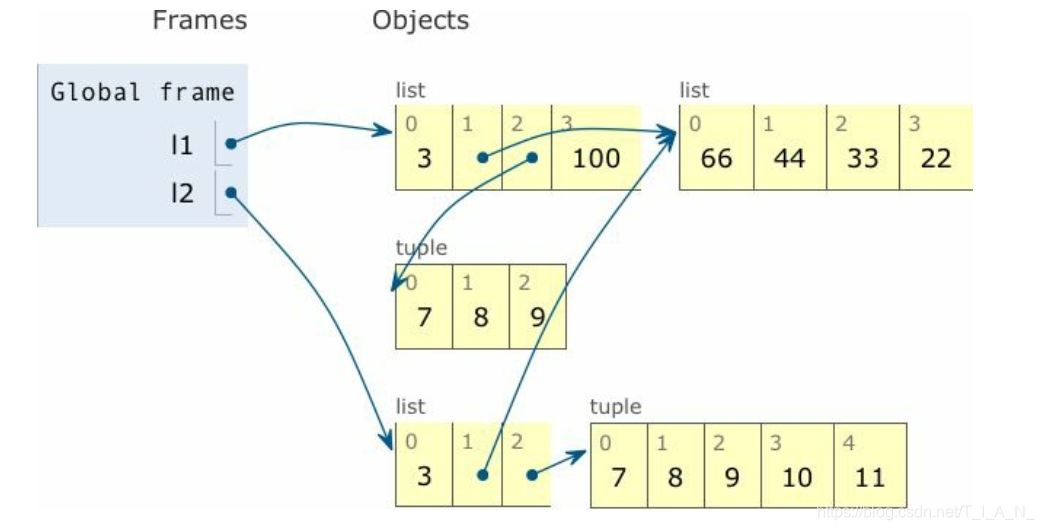
上图是 list1 和 list2 的最终状态: 二者依然引用同一个列表对象, 现在列表的值是 [66, 44, 33, 22], 不过 list2[2] += (10, 11) 创建一个新元组, 内容是 (7, 8, 9, 10, 11), 它与 list1[2] 引用的元组(7, 8, 9) 无关。
深复制
浅复制没什么问题,但有时我们需要的是深复制(即副本不共享内部对象的引用)。copy模块提供的deepcopy和copy函数能为任何对象做深复制和浅复制。
数据完全不共享(复制其数据完完全全放独立的一个内存,完全拷贝,数据不共享)。
深拷贝就是完完全全复制了一份,且数据不会互相影响,因为内存不共享。
class Bus:def __init__(self, passengers=None):if passengers is None:self.passengers = []else:self.passengers = list(passengers)def pick(self, name):self.passengers.append(name)def drop(self, name):self.passengers.remove(name)import copybus1 = Bus(['alice', 'alex', 'bill', 'david'])
bus2 = copy.copy(bus1) # 浅复制
bus3 = copy.deepcopy(bus1) # 深复制
print(id(bus1), id(bus2), id(bus3)) # 685543908520 685543910032 685543910704
bus1.drop('bill')
print(bus1.passengers) # ['alice', 'alex', 'david']
print(bus2.passengers) # ['alice', 'alex', 'david']
print(id(bus1.passengers), id(bus2.passengers),id(bus3.passengers)) # 685543921608 685543921608 685543842632,bus1和bus2共享同一个列表对象
print(bus3.passengers) # ['alice', 'alex', 'bill', 'david']
这篇关于深浅复制详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







