本文主要是介绍【openLooKeng集成Hive连接器完整过程】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【openLooKeng集成Hive连接器完整过程】
- 一、摘要
- 二、正文
- 2.1 环境说明
- 2.2 Hadoop安装
- 2.2.1. 准备工作
- 2.2.2 在协调节点coordinator上进行安装hadoop
- 2.2.3、将Hadoop安装目录分发到从节点worker
- 2.2.4、在协调节点coordinator上启动hadoop集群
- 2.3 MySQL安装
- 2.4 Hive安装及基本操作
- 2.5 openLooKeng配置Hive连接器
- 2.6 openLooKeng操作Hive
- 三、总结
一、摘要
本文主要介绍在openLooKeng中如何使用Hive连接器,并在Hive连接器上对表进行增删改查等操作。openLooKeng如想正常使用Hive连接器相关功能,前提是需要事先安装部署Hive,而Hive的安装依赖于Hadoop环境(如Hive使用远程模式安装则还需要依赖于MySQL,其元数据存储于MySQL中)。故,本文将先完成对Hadoop的安装和MySQL的安装,再对hive进行安装,最后在openLooKeng中配置Hive连接器即可。
二、正文
2.1 环境说明
-
相关软件说明
软件 说明 Hadoop hadoop-2.7.7.tar.gz Hive apache-hive-2.3.3-bin.tar.gz openLooKeng hetu-server-1.10.0.tar.gz JDK 1.8.0_401 MySQL 5.7.44 -
拓扑结构
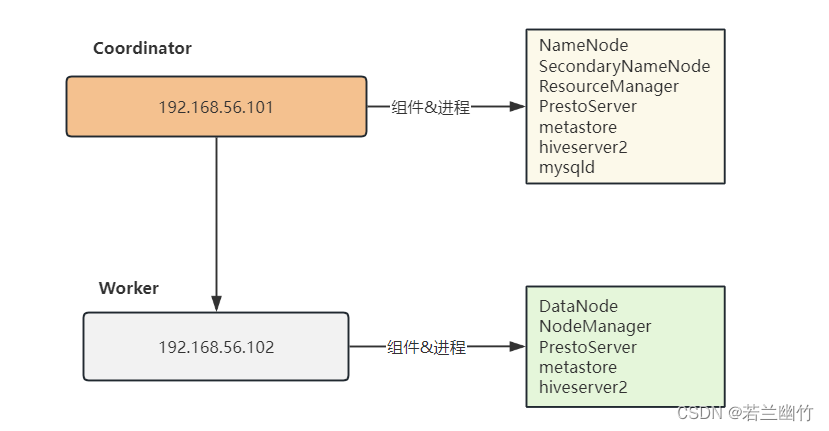
2.2 Hadoop安装
2.2.1. 准备工作
-
1、所有主机安装jdk
上传jdk-8u401-linux-x64.tar.gz到/root目录下,执行如下解压安装:tar -zvxf jdk-8u401-linux-x64.tar.gz -C /opt配置环境变量,编辑/etc/profile文件,添加如下内容:
# jdk export JAVA_HOME=/opt/jdk1.8.0_401 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin环境变量生效,执行:
source /etc/profile验证Java安装正确与否:
[root@coordinator ~]# java -version java version "1.8.0_401" Java(TM) SE Runtime Environment (build 1.8.0_401-b10) Java HotSpot(TM) 64-Bit Server VM (build 25.401-b10, mixed mode) [root@coordinator ~]# -
2、所有主机都需要关闭防火墙
systemctl stop firewalld systemctl disable firewalld -
3、所有主机都需要配置主机名映射关系 :
vim /etc/hosts192.168.56.101 coordinator coordinator.openlookeng.com 192.168.56.102 worker worker.openlookeng.com -
4、配置免密码登录(配置两两之间的免密码登录)
所有的机器都需要产生一对密钥:公钥和私钥,执行如下命令:ssh-keygen -t rsa一直回车即可。当秘钥对生成后,所有主机需要执行如下命令:
ssh-copy-id -i ~/.ssh/id_rsa.pub root@coordinator ssh-copy-id -i ~/.ssh/id_rsa.pub root@worker第一次执行时,需要输入root密码。
2.2.2 在协调节点coordinator上进行安装hadoop
-
上传hadoop安装包/root目录下,解压:
tar -zvxf /root/hadoop-2.7.7.tar.gz -C /opt/ -
配置环境变量
注意需要同时设置:coordinator和worker两个节点# hadoop export HADOOP_HOME=/opt/hadoop-2.7.7 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
创建tmp目录
mkdir /opt/hadoop-2.7.7/tmp -
修改配置文件
1)修改hadoop-env.sh文件vim /opt/hadoop-2.7.7/etc/hadoophadoop-env.sh设置JAVA_HOME的路径为本机jdk安装路径:
export JAVA_HOME=/opt/jdk1.8.0_401
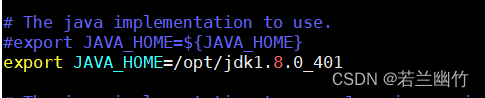
2)修改hdfs-site.xml文件vim /opt/hadoop-2.7.7/etc/hadoop/hdfs-site.xml添加如下信息:
在<configuration></configuration>之间添加<property><name>dfs.replication</name><value>1</value> </property> <property><name>dfs.permissions</name><value>false</value> </property>3)修改
core-site.xml文件vim /opt/hadoop-2.7.7/etc/hadoop/core-site.xml添加如下信息:
<property><name>fs.defaultFS</name><value>hdfs://coordinator:9000</value></property><property><name>hadoop.tmp.dir</name><value>/opt/hadoop-2.7.7/tmp</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>4)修改
mapper-site.xml文件vim /opt/hadoop-2.7.7/etc/hadoop/mapper-site.xml添加如下信息:
<property><name>mapreduce.framework.name</name><value>yarn</value> </property> <!-- 历史服务器端地址
这篇关于【openLooKeng集成Hive连接器完整过程】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






