本文主要是介绍Flink SQL 之 Calcite Volcano优化器(源码解析),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Calcite作为大数据领域最常用的SQL解析引擎,支持Flink , hive, kylin , druid等大型项目的sql解析
同时想要深入研究Flink sql源码的话calcite也是必备技能之一,非常值得学习
我们内部也通过它在做自研的sql引擎,通过一套sql支持关联查询任意多个异构数据源(eg : mysql表join上 hbase表在做一个聚合计算)
因为calcite功能比较多,本文主要还是从calcite重要的主流程源码入手,主要侧重在VolcanoPlanner的优化器上
梳理一下Calcite SQL执行的几个阶段

总结下来就是
1. 通过Parser解析器将传入的sql解析成一颗词法树,SqlNode作为树的节点
2. 做词法的校验Validate,类型校验,元数据校验等等
3. 将校验好的SqlNode树转换成对应的关系代数表达式,也是一颗树,RelNode作为节点
4. 将RelNode关系代数表达式树,通过内置的两种优化器Volcano , Hep 优化关系代数表达式得到最优逻辑代数的一颗树,也是RelNode
5. 最优的逻辑代数表达式(RelNode),会被转换成对应的可执行的物理执行计划(转换逻辑根据框架有所不同),像Flink就转成他的Operator去运行
来详细的看下每个阶段
1. Sql语句解析成语法树阶段(SQL - > SqlNode)
这一个阶段其实不是calcite实现的,而是calcite自己定义了一套sql语法分析规则模板,通过javaCC这个框架去实现的
拉代码来看下
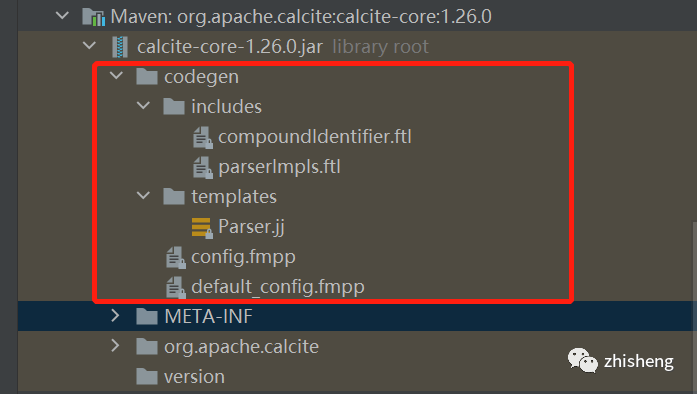
源码中那个Parser.jj就是calcite核心的语法模板了,比如说我们要为flink sql添加什么语法比如count window就要修改这里
其中定义了是什么sql token 如何返回sqlNode的具体逻辑
看个例子
"select ID,NAME from MYHBASE.MYHBASE where ID = '1' "就会被解析成这样一颗sqlNode树
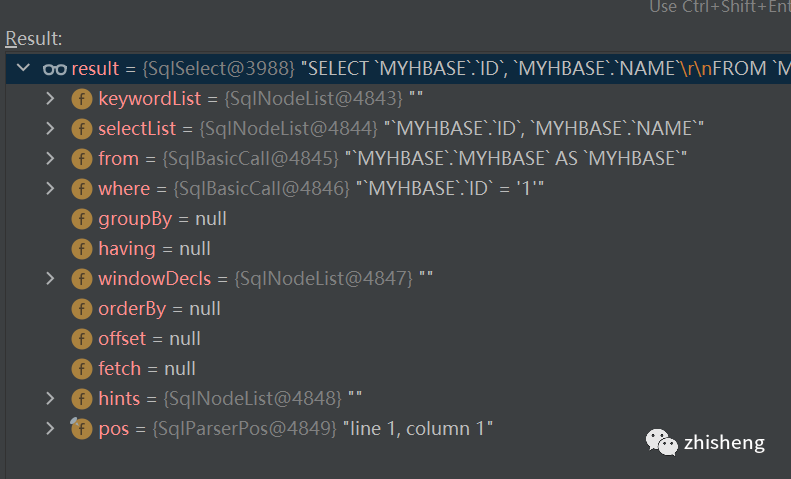
这里就不赘述了,javacc 可以参考官网(https://javacc.github.io/javacc/)
2 . 语法校验validator阶段
这里通过校验器去校验,这里不展开了,不是重点
3. 将sqlNode转成relNode的逻辑表达式树(sqlNode - > relNode)
这里calcite有默认的sql2rel转换器org.apache.calcite.sql2rel.SqlToRelConverter
这里也先不展开了
4. 逻辑关系代数树优化(relNode - > relNode)
这里是中重点中的重点!!!为什么有那么多框架选择Calcite就是因为它的sql优化
通过3阶段我们得到了一个relNode树,但这里这颗树并不是最优解,而calcite通过自身的两种优化器planner得到一个优化后的best树
这里才是整个calcite的核心,calcite提供的两种优化器
HepPlanner规则优化器(简单理解为定义许多规则Rule,只要能符合优化规则的树节点的就按规则转换,得到一颗规则优化后的树,这个比较简单)
VolcanPanner代价优化器(基于代价cost,树会根据rule一直迭代,不停计算更新root relnode节点的代价值,来找到最优的树)
先来看下
select ID,NAME from a where ID = '1'这样sql转换而来的一颗RelNode树长什么样子
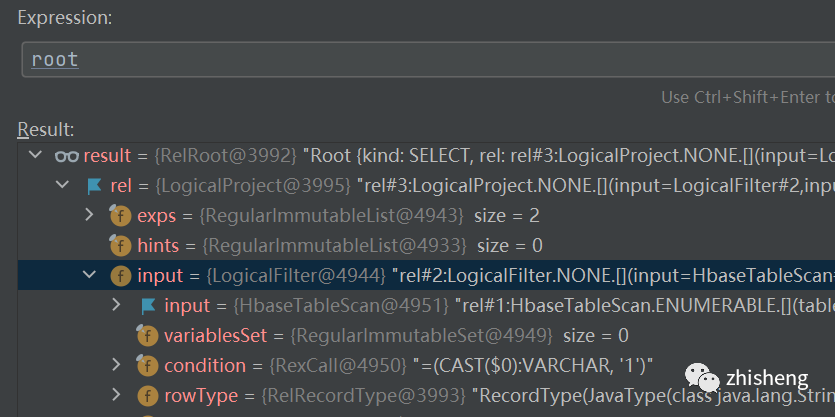
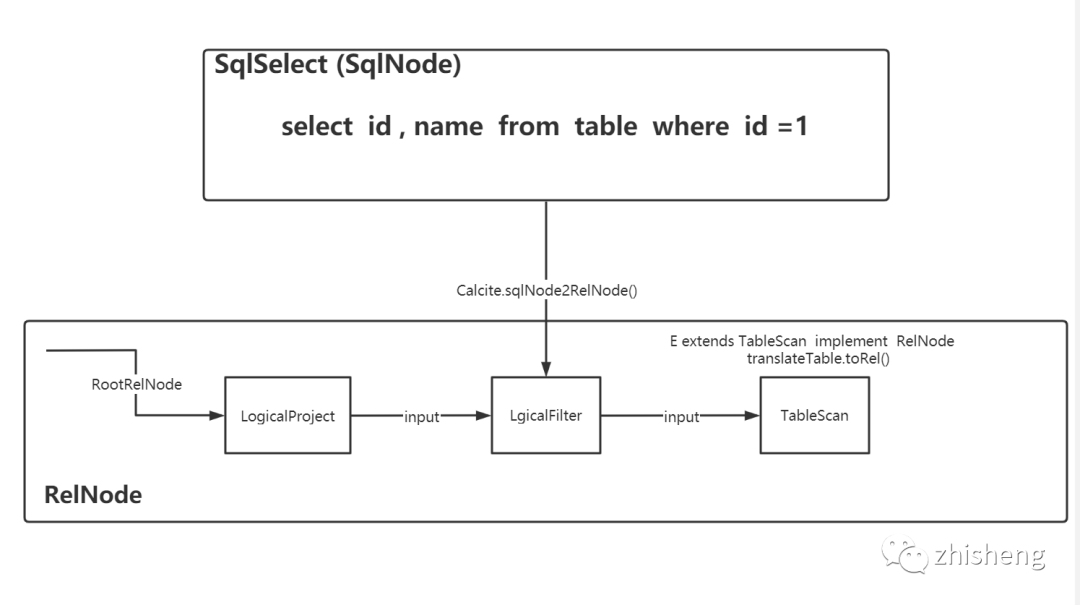
可以看到很多节点都是以Logical命名的,因为这是3阶段通过calcite默认的转化器(SqlToRelConverter)转换而来的逻辑节点,逻辑节点是没有物理属性的也无法运行的
接下来进入calcite的代价cost优化器VolcanoPlanner进行优化

返回的就是代价最优的解
进去calcite的optimize方法
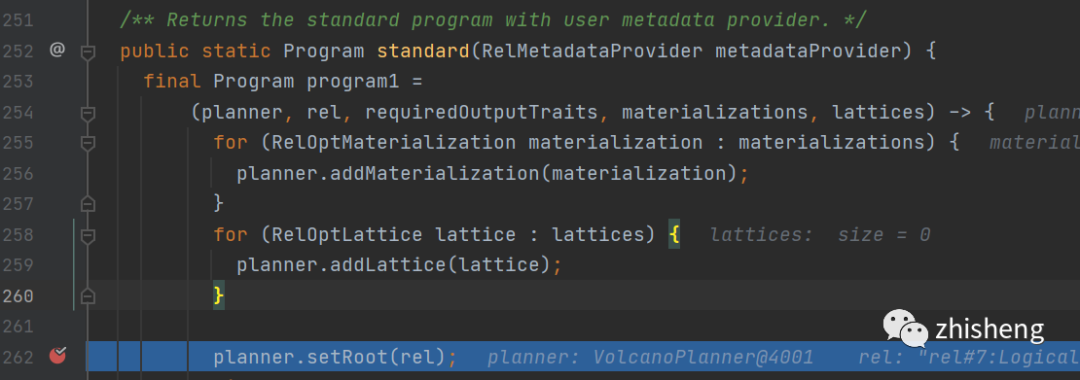
首先calcite会将我们上一阶段得到的relNode设置到我们代价Volcano优化器的root里去
在其中 org.apache.calcite.plan.volcano.VolcanoPlanner.registerImpl() 方法中
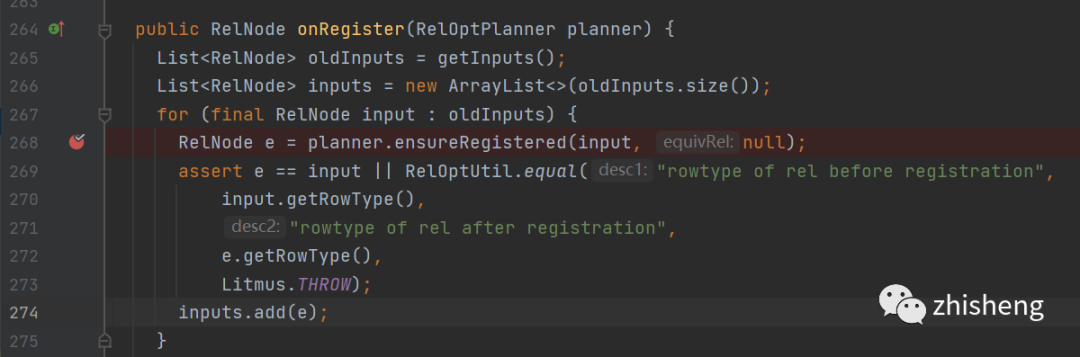
断点的地方在register的过程中会先将relnode的input先注册
在ensureRestered方法中
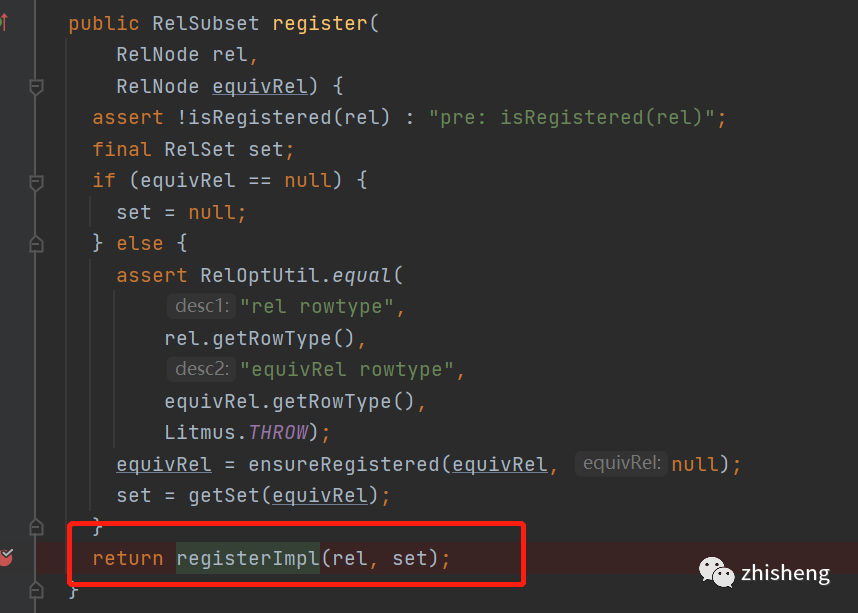
可以看到有绕回了registerImpl()方法
也就是树的子节点深度遍历先注册
接下来看一下注册过程
既然是深度遍历回到刚才看的VolcanoPlanner.registerImpl()方法中看下onRegister()方法之后做了什么

可以看到要触发规则了,这里就要穿插一个概念,calcite中的Rule
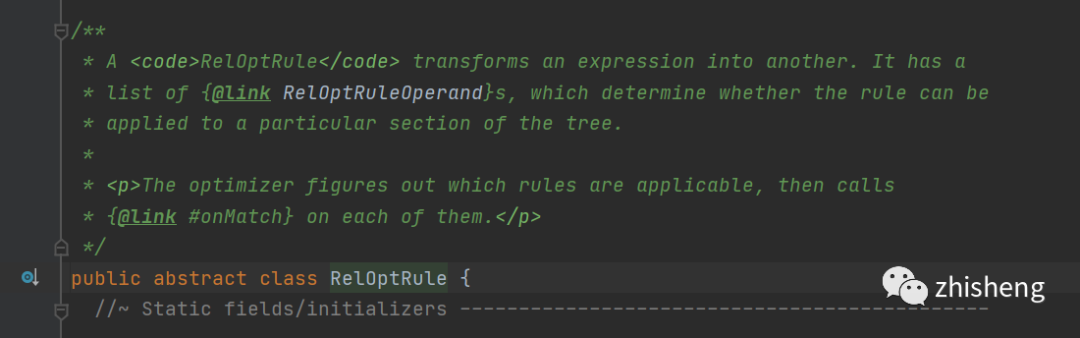
从类描述中我们可以知道,规则可以将一个表达式转换成另一个,什么意思呢,来看下有哪些抽象方法
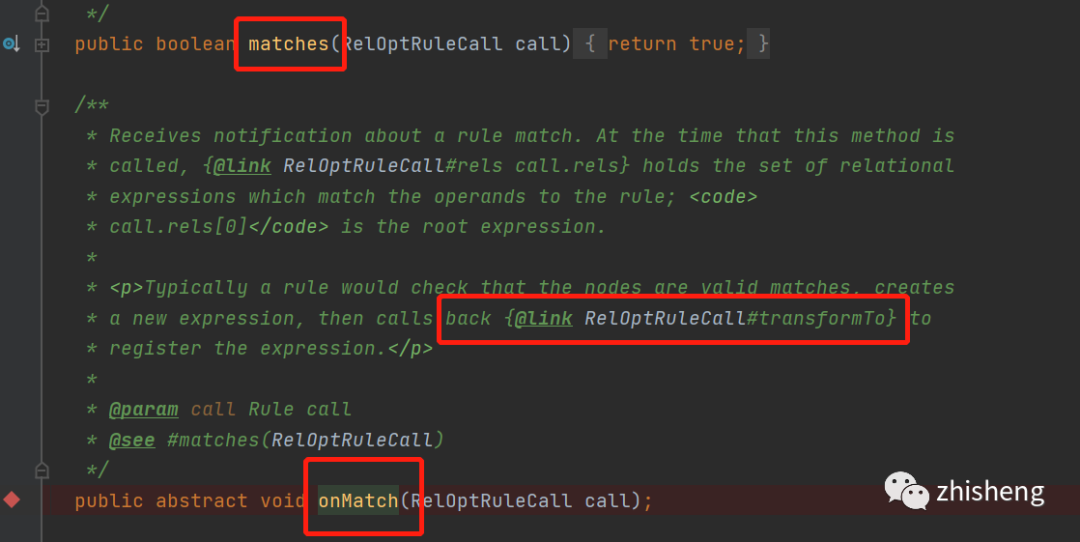
什么意思呢?归纳起来就是两个核心方法
matches()返回当前的relnode是否能匹配上此规则rule
onMatch () 当匹配上此规则时,这个方法会被调用,在其中可以调用transformTo()方法,这个方法的作用就是将一个relNode转换成另一个relNode
规则就是整个calcite的核心了,其实所有的sql优化都是由对应的rule组成的,将sql的优化逻辑实现为对应的rule让对应的relNode树节点做对应的转换来得到最优的best执行计划
ok回到我们的主流程上,继续上面的volcanoPlanner.fireRule()方法看看如何触发规则的
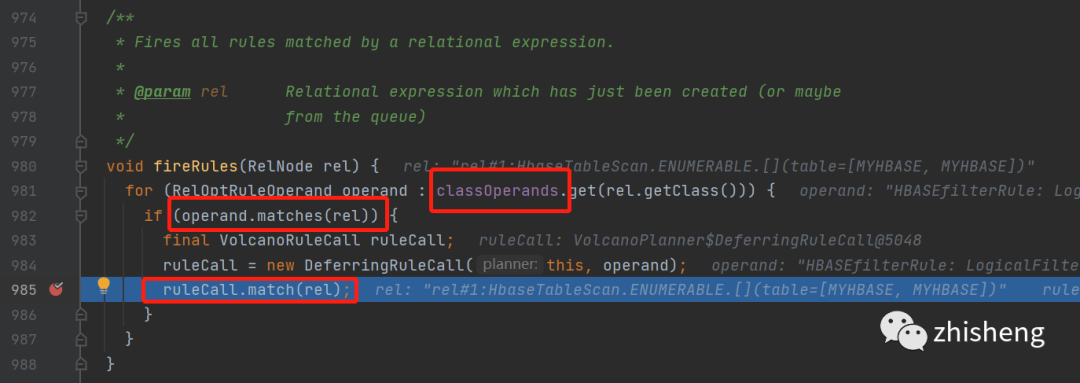
这里逻辑是比较简单的,就是当relnode满足rule就调用volcanoRuleCall的match()方法
但是有个地方需要注意,这里的classOperands这里包含了relNode以及所有可能匹配上这个relnode的规则的映射关系,并且可以向上也可以向下
具体是什么意思呢?
假设我有一个LogicFilter的RelNode,然后定义了两个规则
RuleA
operand(Logicalfilter.class, operand(TableScan.class))RuleB
operand(Logicalproject.class, operand(Logicalfilter.class))那这两个rule都会进入这个可能匹配上的映射关系classOperands里面去
当匹配上rule以后,接着来继续看代码
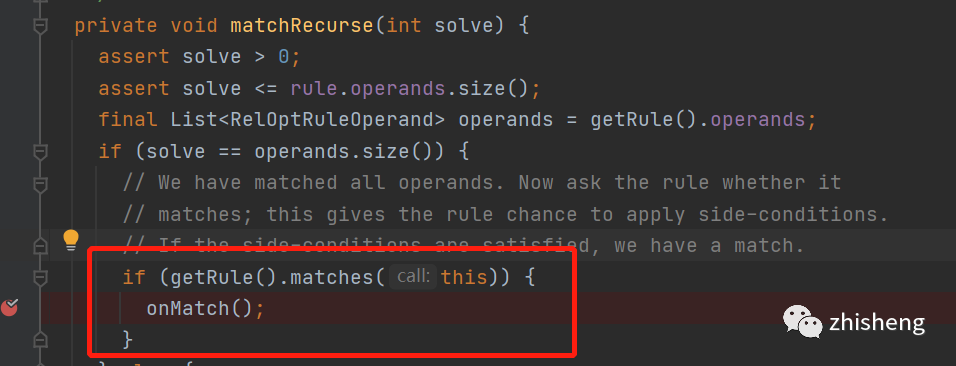
然后走到了volcanoPlanner.DeferringRuleCall的onMatch中
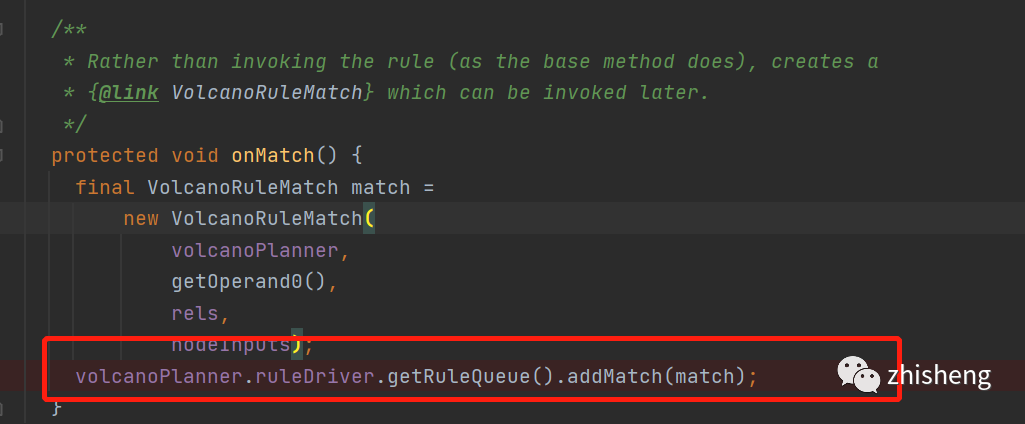
这里就是把这个rule的加入到了IterativeRuleDriver中的ruleQueue,这个队列就是专门用来存放已经匹配上的rule的,不难发现这些匹配上的rule只是存在队列里面,但还没有执行这些规则
那多久会执行呢?
回到主流程当我们setRoot里的所有relnode子节点都register以后
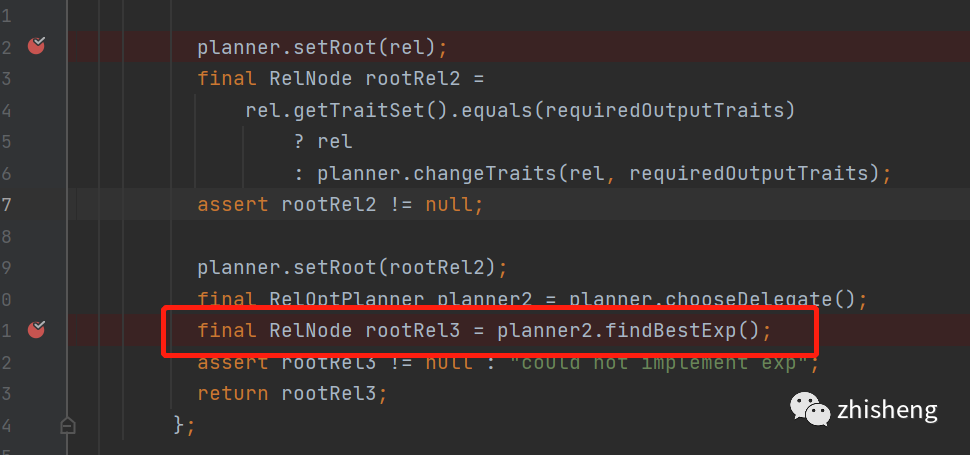
会走具体planner的findBestExp()方法,从名字可以看出来找到最优的表达式
这里要提前说一下,claicte的优化原理是,它假定如果一个表达式最优,那它的局部也是最优的,那当前relNode的best我们也就只用关心,从
1.子节点的所有best加起来
2. 自己能匹配上的所有规则,以及剩下部位的best加起来
从中比较得到的就是当前relnode的最优解了
引用个图
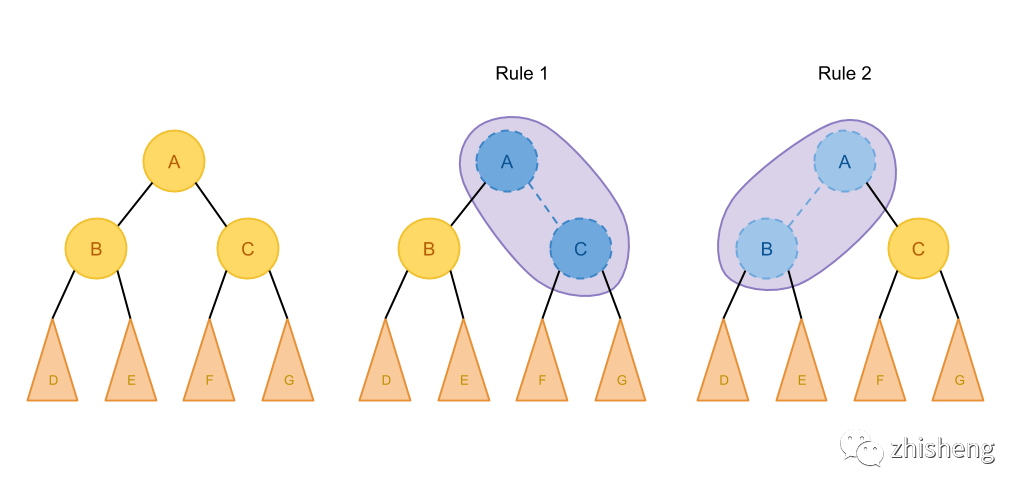
如果A只能匹配这两种规则,那我们枚举求最优解的时候就只用考虑这几张情况
关于原理不太了解的可以看看这篇 https://io-meter.com/2018/11/01/sql-query-optimization-volcano/
接着看findBestexp()
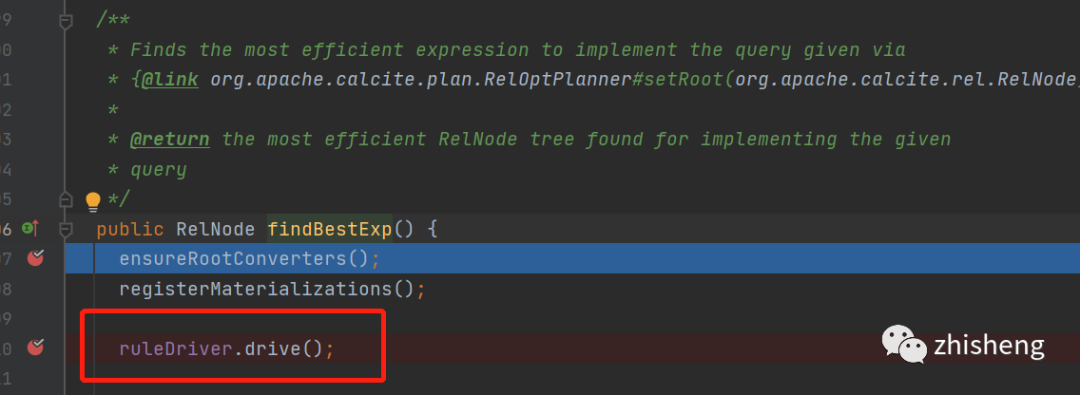
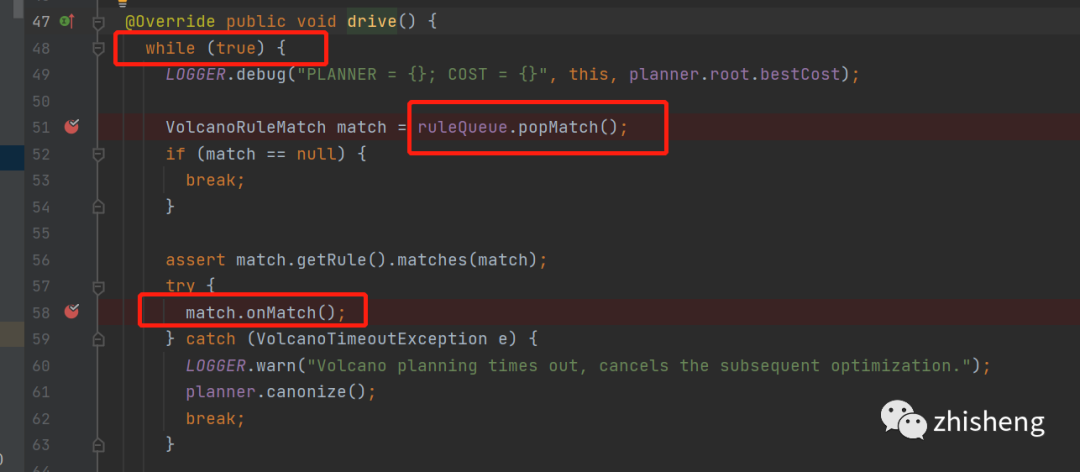
这里就是整个优化寻找最优解bestExp的主loop了
不停的从queue中拿rule, 运行rule,直到所有rule都执行完才退出
没错这里的这个queue就是前面说到的,当默认的relnode注册进来的时候会把能匹配上的rule放这queue里面去
这里自然就有个疑问, 前面说到rule运行的时候会改变relNode节点,也就是添加relndoe的等价节点,
那这里树的结构变化会导致,之前不能匹配上的rule改变树的结构后就能匹配上,那这里能匹配上的rule不就漏了,那就接着看rule的onMatch()中用于转换等价节点的方法transformTo()
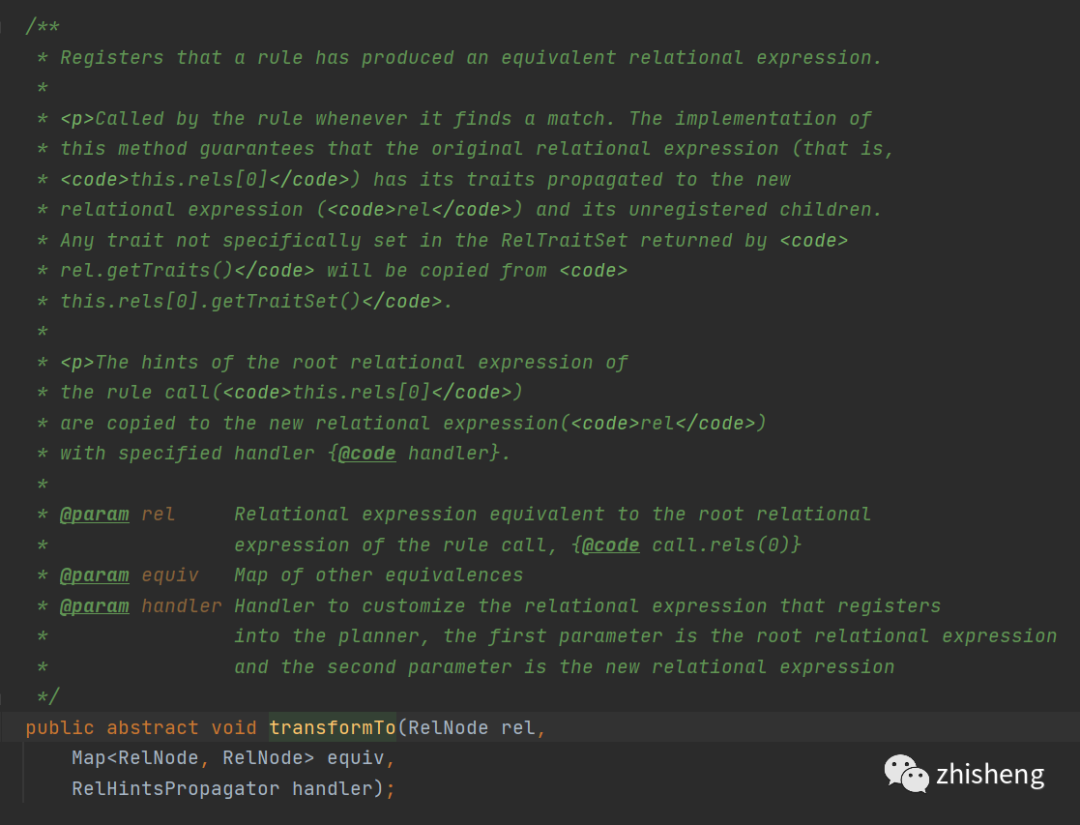
其中转换的新节点,在transformTo方法中又会执行register

也就是说新来的节点也会走一遍,默认relNode注册的流程,当新节点注册成等价节点会有新的规则匹配上的时候,又会将此rule加入rulequeu中等待下一次执行rule了
另外当这个relnode节点会被规则rule转换时,生成的新relnode会被设置加入到这个relnode的等价节点中去
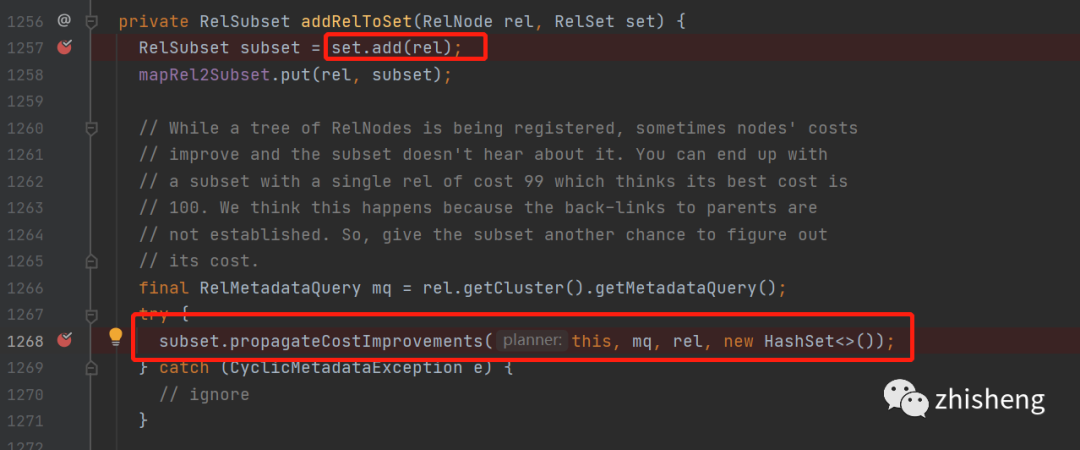
加入等价节点,并且在propagateCostImprovement方法中
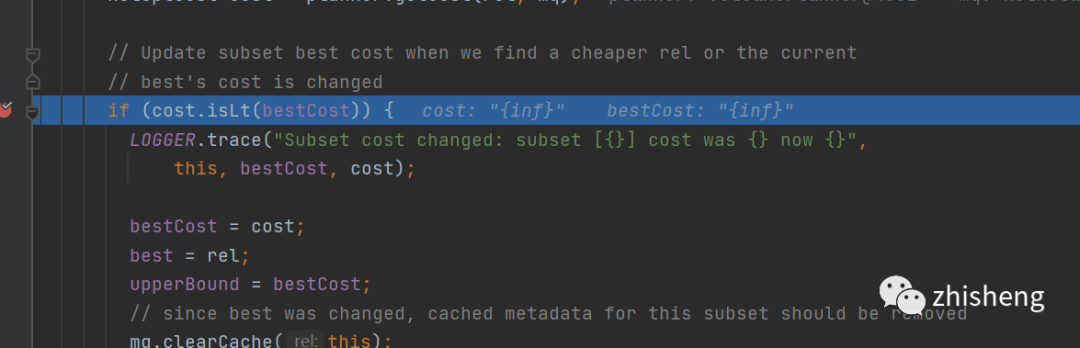
计算当前等价节点会不会使,当前relnode的cost代价下降,如果下降了,那就更新当前relnode的bestcost并且向上冒泡修改父relnode的最优bestCost
while true 一直触发拉取ruleQueue中的rule,直到rule为空
然后rule会添加新的等价节点
新的等价节点如果更优cost,更新整棵树的best Relnode
新的等价节点relnode会匹配上新的规则,新的rule加入到rulequeue中
进入下一次循环,直到没有rule可以匹配上,这样bestexp就可以返回优化后的最优的relnode了
之后就是根据这个最优的relnode,不同的框架翻译成自己的api
calciet终于说完,,之后就可以开始解析flink sql的源码了
本地地址:https://www.cnblogs.com/ljygz/p/15421973.html
end
Flink 从入门到精通 系列文章基于 Apache Flink 的实时监控告警系统
关于数据中台的深度思考与总结(干干货)
日志收集Agent,阴暗潮湿的地底世界

公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。点个赞+在看,少个 bug 👇这篇关于Flink SQL 之 Calcite Volcano优化器(源码解析)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


