本文主要是介绍Python爬虫学习笔记-第二课(网络请求模块上),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
网络请求模块上
- 1. 相关概念介绍
- 1.1 向网站发起请求的方式:
- 1.2 url-全球统一资源定位符
- 1.3 User-Agent 用户代理
- 1.4 referer
- 1.5 状态码
- 1.6 抓包工具
- 2. urllib模块简介
- 3. urllib常用方法
- 3.1 urllib.request
- 3.2 urllib.parse
1. 相关概念介绍
1.1 向网站发起请求的方式:
- Get
查询参数会在url地址中显示;
通常应用于直接从服务器上获取数据,不会对服务器上的数据产生影响;
打开百度搜索引擎,搜索python关键字,按快捷键F12,显示结果如下:

搜索的关键字python在url地址中会有显示。
- Post
查询参数不会显示在url地址上;
向服务器发送请求,会对服务器的数据产生影响,比如在某网站进行登录操作,需要向服务器提交账号、密码信息进行验证,或者上传文件,这些操作会影响服务器的资源,请求的方法大多是post。
比如,打开github登录界面,尝试登陆github账号:
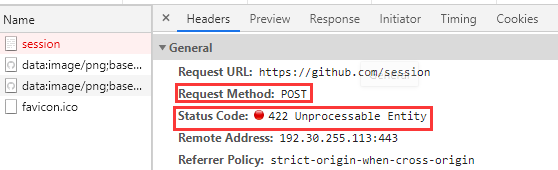
这里账号密码是随便乱输,服务器给的反馈状态码是422,请求方式是POST。
login账号、密码信息在Form Data里。

1.2 url-全球统一资源定位符
https://new.qq.com/omn/20201210/20201210A04L0R00.html
url组成解析:
- https: 协议
- new.qq.com: 主机名,省略了端口
- omn/20201210/20201210A04L0R00.html: 访问资源的路径
- anchor:锚点 可以作为页面定位导航。
以百度百科为例,图中1.1 早年经历与url中的#1_1相对应。

再比如网易云音乐,我的音乐与url中的#my相对应。

小细节:浏览器请求一个url的时候,除了英文字母、数字和部分符号外,其他的字符都会用%十六进制来表示。自己编写代码向服务器发起请求时,需要注意中文字符的转换。
1.3 User-Agent 用户代理

User-Agent里记录了一些信息,比如用户的操作系统、浏览器、内核等等,为了让用户获取更好的HTML页面效果。
服务器会对user-agent进行检查,即使向同一个服务器发起请求,不同的浏览器之间通常会有不同的效果。
1.4 referer
在网易云音乐里,想要找自己想听的歌曲,通常先到网易云音乐的首页,再点击或者搜索想听的歌曲,才会到达具体的页面,此时referer就会记录当前请求从哪个url转过来。
反爬工程师可以通过referer来判断当前的请求是否是程序发起的,我们自己编写代码也应考虑这一点,尽可能地模拟人类请求服务器的动作。

referer表明当前请求从哪一个url过来,通常也可作为反爬的技术之一。
1.5 状态码
200:请求成功
301:永久重定向
302:临时重定向
404:请求失败(服务器无法根据客户端的请求找到资源)
500:服务器内部请求
关于重定向,京东首页的url为www.jd.com

但一些老用户不知道新的url地址,输入老地址www.360buy.com,也能跳转到京东首页:

再比如,直接输入www.zhihu.com,想要访问知乎,但是会临时重定向到知乎的登陆界面:
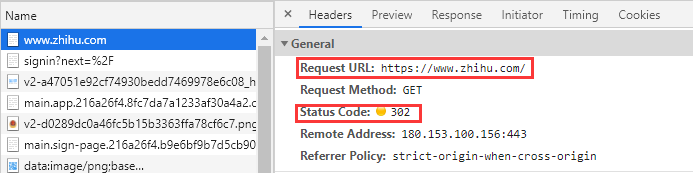
1.6 抓包工具
Elements:元素,网页源代码,提取和分析数据,但是有些数据是经过处理的,所以并不都是准确的。

Console:控制台(打印信息)
Source:信息来源(整个网站加载的文件)

Network:网络工作(信息抓包),能都看到许多的网页请求。

2. urllib模块简介
为什么还需要学习urllib模块:
- 有些比较老的爬虫项目用的是urllib技术;
- 有些情况爬取数据的时候需要urllib+requests一起使用;
- urllib是内置模块,有必要掌握一定的基础使用;
- 某些方面的作用还是比较强大的。
示例代码:
在百度页面上抓取一张图片:
# 方式一:使用requests模块
import requests
# 将图片的地址保存在变量中
url = 'https://dss2.bdstatic.com/8_V1bjqh_Q23odCf/pacific/1975226040.jpg'
# 抓取图片
pict = requests.get(url).content
# 保存图片到pict.jpg
with open('pict.jpg', 'wb') as f_obj:f_obj.write(pict)
在py文件的同级目录下,出现pict.jpg的图片文件,如下:

# 方式2 使用urllib模块
from urllib import request
# 将图片的地址保存在变量中
url = 'https://dss2.bdstatic.com/70cFvnSh_Q1YnxGkpoWK1HF6hhy/it/u=2416828055,1360908189&fm=26&gp=0.jpg'
# 抓取图片
request.urlretrieve(url, 'pict2.jpg')
在py文件的同级目录下,出现pict2.jpg的图片文件,如下:

3. urllib常用方法
3.1 urllib.request
示例代码:
import urllib.request as ure
response = ure.urlopen('http://www.baidu.com/')
# read()方法把响应对象里面的内容读取出来
# decode()方法把内容解码转换成str类型
html = response.read().decode('utf-8')
print(html)
print(type(html))
运行结果:

从上图的结果看,这并非我们期望得到的数据,说明百度服务器有一些反爬措施.
一个直接的思路是添加headers,更好地模拟人访问网站.
import urllib.request as ure
# 给程序添加headers
headers = {}
# TypeError: urlopen() got an unexpected keyword argument 'headers'
response = ure.urlopen('http://www.baidu.com/', headers=headers)
运行结果:

上图结果显示,无法直接通过urlopen()方法添加请求的headers.
改进代码如下:
import urllib.request
# 0.准备前置变量
url = 'http://www.baidu.com/'
headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:80.0) Gecko/20100101 Firefox/80.0'}
# 1.创建请求的对象(构建user-agent)
req = urllib.request.Request(url,headers=headers)
# 2.获取响应对象(urlopen)
res = urllib.request.urlopen(req)
# 3.读取响应对象的内容(read().decode('utf-8'))
html = res.read().decode('utf-8')
运行结果:

图中显示了百度网页上的文字信息,说明请求的数据比之前更正常一些.
此时也可对响应对象使用getcode()方法,查看响应的状态码:
print(res.getcode())
运行结果:

3.2 urllib.parse
当url地址中出现中文字符,浏览器会将中文字符进行编码,表现形式为%十六进制,一个汉字对应3个%
例如:
张无忌 %e5%bc%a0%e6%97%a0%e5%bf%8c
张无 %e5%bc%a0%e6%97%a0
百度搜索"张无忌",url地址为:
https://www.baidu.com/s?ie=utf-8&f=3&rsv_bp=1&rsv_idx=1&tn=baidu
&wd=%E5%BC%A0%E6%97%A0%E5%BF%8C&fenlei=256&rsv_pq=9fcf15e2000a745c&
rsv_t=c2feR0%2BEOVViZDAVbDKUJc1TcmQWEX5VWWHEk%2BeFcO7MHgndVe%2FUFxgLpPw&rqlang=
cn&rsv_enter=1&rsv_dl=is_0&rsv_sug3=10&rsv_sug1=7&rsv_sug7=101&rsv_sug2=1&
rsv_btype=i&prefixsug=zhangwuji&rsp=0&inputT=3140&rsv_sug4=16408
# 使用urlencode()方法将中文字符编码
import urllib.parse
tu = {'wd':'张无忌'}
res = urllib.parse.urlencode(tu)
print(res)
运行结果:

小练习:输入要搜索的内容, 并保存到本地 内容.html.
import urllib.parse
import urllib.request
# 目标url
base_url = 'https://www.baidu.com/s?'
key = input('请输入想要搜索的内容:')
# urlencode()对中文字符编码
wd = {'wd' : key}
key = urllib.parse.urlencode(wd)
# 拼接url
url = base_url + key
print(url)# 输出结果:
请输入想要搜索的内容:张无忌
https://www.baidu.com/s?wd=%E5%BC%A0%E6%97%A0%E5%BF%8C
将得到的url输入浏览器,回车得到如下结果(浏览器自动把编码的汉字解码成正常字符):

继续小练习,接下来给出完整代码:
import urllib.parse
import urllib.request
# 目标url
base_url = 'https://www.baidu.com/s?'
key = input('请输入想要搜索的内容:')
# urlencode()对中文字符编码
wd = {'wd' : key}
key = urllib.parse.urlencode(wd)
# 拼接url
url = base_url + key
headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:80.0) Gecko/20100101 Firefox/80.0'}
# 1.创建请求的对象(构建user-agent)
req = urllib.request.Request(url,headers=headers)
# 2.获取响应对象(urlopen)
res = urllib.request.urlopen(req)
# 3.读取响应对象的内容(read().decode('utf-8'))
html = res.read().decode('utf-8')
# 4.保存文件
with open('内容.html', 'w', encoding='utf-8') as fobj:fobj.write(html)
运行结果,在py文件同级目录下出现内容.html文件,文件内容的部分截图如下:

除了使用urlencode()方法外,quote()也可以对中文字符进行编码处理.
import urllib.parse
import urllib.request
# 目标url
base_url = 'https://www.baidu.com/s?wd='
# 使用quote()对中文字符编码
key = urllib.parse.quote('张无忌')
url = base_url + key
print('目标url: ', url)
运行结果:

小总结:
urlencode() 方法传入的参数是一个字典.
quote() 方法传入的参数是一个字符串.
这篇关于Python爬虫学习笔记-第二课(网络请求模块上)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






