本文主要是介绍LLM之RAG实战(三十八)| RAG分块策略之语义分块,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

在RAG应用中,分块是非常重要的一个环节,常见的分块方法有如下几种:
- Fixed size chunking
- Recursive Chunking
- Document Specific Chunking
- Semantic Chunking
a)Fixed size chunking:这是最常见、最直接的分块方法。我们只需决定分块中的tokens数量,以及它们之间是否应该有任何重叠。一般来说,我们希望在块之间保持一些重叠,以确保语义上下文不会在块之间丢失。与其他形式的分块相比,固定大小的分块在计算上便宜且使用简单,因为它不需要使用任何NLP库。
b)Recursive Chunking:递归分块使用一组分隔符,以分层和迭代的方式将输入文本划分为更小的块。如果最初分割文本没有产生所需大小或结构的块,则该方法会使用不同的分隔符或标准递归地调用结果块,直至达到所需的块大小或结构。这意味着,虽然块的大小不会完全相同,但它们仍然具有相似的大小,并可以利用固定大小块和重叠的优点。
c)Document Specific Chunking:该方法不像上述两种方法一样,它不会使用一定数量的字符或递归过程,而是基于文档的逻辑部分(如段落或小节)来生成对齐的块。该方法可以保持内容的组织,从而保持了文本的连贯性,比如Markdown、Html等特殊格式。
d)Semantic Chunking:语义分块会考虑文本内容之间的关系。它将文本划分为有意义的、语义完整的块。这种方法确保了信息在检索过程中的完整性,从而获得更准确、更符合上下文的结果。与之前的分块策略相比,速度较慢。
本文,我们将对语义分块和递归检索器进行实验分析:
一、语义分块
语义分块包括获取文档中每个句子的嵌入,比较所有句子的相似性,然后将嵌入最相似的句子分组在一起。
这里的假设是,我们可以使用单个句子的嵌入来生成更有意义的块。基本思路如下:
-
根据分隔符(.,?,!)将文档拆分成句子;
-
根据位置为每个句子创建索引;
-
分组:选择两边的句子数量,在所选句子的两侧添加一个句子缓冲区;
-
计算句子组之间的距离;
-
根据相似性合并组,即将相似的句子放在一起;
-
把不相似的句子分开。
二、代码实现
安装相关包
!pip install -qU langchain_experimental langchain_openai langchain_community langchain ragas chromadb langchain-groq fastembed pypdf openai相关包的版本如下:
langchain==0.1.16langchain-community==0.0.34langchain-core==0.1.45langchain-experimental==0.0.57langchain-groq==0.1.2langchain-openai==0.1.3langchain-text-splitters==0.0.1langcodes==3.3.0langsmith==0.1.49chromadb==0.4.24ragas==0.1.7fastembed==0.2.6
下载数据集
!wget "https://arxiv.org/pdf/1810.04805.pdf"处理PDF文件
from langchain.document_loaders import PyPDFLoaderfrom langchain.text_splitter import RecursiveCharacterTextSplitter#loader = PyPDFLoader("1810.04805.pdf")documents = loader.load()#print(len(documents))
运行基本分块(RecursiveCharacterTextSpliting)
from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=0,length_function=len,is_separator_regex=False)#naive_chunks = text_splitter.split_documents(documents)for chunk in naive_chunks[10:15]:print(chunk.page_content+ "\n")###########################RESPONSE###############################BERT BERTE[CLS] E1 E[SEP] ... ENE1’... EM’CT1T[SEP] ...TNT1’...TM’[CLS] Tok 1 [SEP] ... Tok NTok 1 ... TokMQuestion Paragraph Start/End SpanBERTE[CLS] E1 E[SEP] ... ENE1’... EM’CT1T[SEP] ...TNT1’...TM’[CLS] Tok 1 [SEP] ... Tok NTok 1 ... TokMMasked Sentence A Masked Sentence BPre-training Fine-Tuning NSP Mask LM Mask LMUnlabeled Sentence A and B Pair SQuADQuestion Answer Pair NER MNLI Figure 1: Overall pre-training and fine-tuning procedures for BERT. Apart from output layers, the same architec-tures are used in both pre-training and fine-tuning. The same pre-trained model parameters are used to initializemodels for different down-stream tasks. During fine-tuning, all parameters are fine-tuned. [CLS] is a specialsymbol added in front of every input example, and [SEP] is a special separator token (e.g. separating ques-tions/answers).ing and auto-encoder objectives have been usedfor pre-training such models (Howard and Ruder,2018; Radford et al., 2018; Dai and Le, 2015).2.3 Transfer Learning from Supervised DataThere has also been work showing effective trans-fer from supervised tasks with large datasets, suchas natural language inference (Conneau et al.,2017) and machine translation (McCann et al.,2017). Computer vision research has also demon-strated the importance of transfer learning fromlarge pre-trained models, where an effective recipeis to fine-tune models pre-trained with Ima-geNet (Deng et al., 2009; Yosinski et al., 2014).3 BERTWe introduce BERT and its detailed implementa-tion in this section. There are two steps in ourframework: pre-training and fine-tuning . Dur-ing pre-training, the model is trained on unlabeleddata over different pre-training tasks. For fine-tuning, the BERT model is first initialized withthe pre-trained parameters, and all of the param-eters are fine-tuned using labeled data from thedownstream tasks. Each downstream task has sep-arate fine-tuned models, even though they are ini-tialized with the same pre-trained parameters. Thequestion-answering example in Figure 1 will serveas a running example for this section.A distinctive feature of BERT is its unified ar-chitecture across different tasks. There is mini-mal difference between the pre-trained architec-ture and the final downstream architecture.Model Architecture BERT’s model architec-ture is a multi-layer bidirectional Transformer en-coder based on the original implementation de-scribed in Vaswani et al. (2017) and released inthetensor2tensor library.1Because the useof Transformers has become common and our im-plementation is almost identical to the original,we will omit an exhaustive background descrip-tion of the model architecture and refer readers toVaswani et al. (2017) as well as excellent guidessuch as “The Annotated Transformer.”2In this work, we denote the number of layers(i.e., Transformer blocks) as L, the hidden size asH, and the number of self-attention heads as A.3We primarily report results on two model sizes:BERT BASE (L=12, H=768, A=12, Total Param-eters=110M) and BERT LARGE (L=24, H=1024,A=16, Total Parameters=340M).BERT BASE was chosen to have the same modelsize as OpenAI GPT for comparison purposes.Critically, however, the BERT Transformer usesbidirectional self-attention, while the GPT Trans-former uses constrained self-attention where everytoken can only attend to context to its left.41https://github.com/tensorflow/tensor2tensor2http://nlp.seas.harvard.edu/2018/04/03/attention.html3In all cases we set the feed-forward/filter size to be 4H,i.e., 3072 for the H= 768 and 4096 for the H= 1024 .4We note that in the literature the bidirectional Trans-Input/Output Representations To make BERThandle a variety of down-stream tasks, our inputrepresentation is able to unambiguously representboth a single sentence and a pair of sentences(e.g.,〈Question, Answer〉) in one token sequence.Throughout this work, a “sentence” can be an arbi-trary span of contiguous text, rather than an actuallinguistic sentence. A “sequence” refers to the in-put token sequence to BERT, which may be a sin-gle sentence or two sentences packed together.We use WordPiece embeddings (Wu et al.,2016) with a 30,000 token vocabulary. The firsttoken of every sequence is always a special clas-sification token ( [CLS] ). The final hidden statecorresponding to this token is used as the ag-gregate sequence representation for classificationtasks. Sentence pairs are packed together into asingle sequence. We differentiate the sentences intwo ways. First, we separate them with a specialtoken ( [SEP] ). Second, we add a learned embed-
实例化embedding模型
from langchain_community.embeddings.fastembed import FastEmbedEmbeddingsembed_model = FastEmbedEmbeddings(model_name="BAAI/bge-base-en-v1.5")
设置大模型的API Key
from google.colab import userdatafrom groq import Groqfrom langchain_groq import ChatGroq#groq_api_key = userdata.get("GROQ_API_KEY")
我们今天将使用“百分位(percentile)”阈值作为示例,但在语义块上可以使用三种不同的策略):
“百分位数(percentile)”(默认值):计算句子之间的所有差异,然后将大于X百分位数的任何差异拆分。
“标准偏差(standard_deviation)”:任何大于X个标准偏差的差异都会被拆分。
“四分位间距(interquartile)”:四分位距离用于分割块。
PS:这种方法目前还在实验阶段,并不稳定,预计在未来几个月内会有更新和改进。
from langchain_experimental.text_splitter import SemanticChunkerfrom langchain_openai.embeddings import OpenAIEmbeddingssemantic_chunker = SemanticChunker(embed_model, breakpoint_threshold_type="percentile")#semantic_chunks = semantic_chunker.create_documents([d.page_content for d in documents])#for semantic_chunk in semantic_chunks:if "Effect of Pre-training Tasks" in semantic_chunk.page_content:print(semantic_chunk.page_content)print(len(semantic_chunk.page_content))#############################RESPONSE###############################Dev SetTasks MNLI-m QNLI MRPC SST-2 SQuAD(Acc) (Acc) (Acc) (Acc) (F1)BERT BASE 84.4 88.4 86.7 92.7 88.5No NSP 83.9 84.9 86.5 92.6 87.9LTR & No NSP 82.1 84.3 77.5 92.1 77.8+ BiLSTM 82.1 84.1 75.7 91.6 84.9Table 5: Ablation over the pre-training tasks using theBERT BASE architecture. “No NSP” is trained withoutthe next sentence prediction task. “LTR & No NSP” istrained as a left-to-right LM without the next sentenceprediction, like OpenAI GPT. “+ BiLSTM” adds a ran-domly initialized BiLSTM on top of the “LTR + NoNSP” model during fine-tuning. ablation studies can be found in Appendix C. 5.1 Effect of Pre-training TasksWe demonstrate the importance of the deep bidi-rectionality of BERT by evaluating two pre-training objectives using exactly the same pre-training data, fine-tuning scheme, and hyperpa-rameters as BERT BASE :No NSP : A bidirectional model which is trainedusing the “masked LM” (MLM) but without the“next sentence prediction” (NSP) task. LTR & No NSP : A left-context-only model whichis trained using a standard Left-to-Right (LTR)LM,

实例化向量数据库
from langchain_community.vectorstores import Chromasemantic_chunk_vectorstore = Chroma.from_documents(semantic_chunks, embedding=embed_model)
我们将把语义检索器“限制”为k=1,以展示语义分块策略的能力,同时在语义和原始检索上下文之间保持相似的tokens计数。
实例化检索步骤
semantic_chunk_retriever = semantic_chunk_vectorstore.as_retriever(search_kwargs={"k" : 1})semantic_chunk_retriever.invoke("Describe the Feature-based Approach with BERT?")########################RESPONSE###################################[Document(page_content='The right part of the paper represents the\nDev set results. For the feature-based approach,\nwe concatenate the last 4 layers of BERT as the\nfeatures, which was shown to be the best approach\nin Section 5.3. From the table it can be seen that fine-tuning is\nsurprisingly robust to different masking strategies. However, as expected, using only the M ASK strat-\negy was problematic when applying the feature-\nbased approach to NER. Interestingly, using only\nthe R NDstrategy performs much worse than our\nstrategy as well.')]
实例化增强步骤(用于内容增强)
from langchain_core.prompts import ChatPromptTemplaterag_template = """\Use the following context to answer the user's query. If you cannot answer, please respond with 'I don't know'.User's Query:{question}Context:{context}"""rag_prompt = ChatPromptTemplate.from_template(rag_template)
实例化生成步骤
chat_model = ChatGroq(temperature=0,model_name="mixtral-8x7b-32768",api_key=userdata.get("GROQ_API_KEY"),)
利用语义块创建RAG管道
from langchain_core.runnables import RunnablePassthroughfrom langchain_core.output_parsers import StrOutputParsersemantic_rag_chain = ({"context" : semantic_chunk_retriever, "question" : RunnablePassthrough()}| rag_prompt| chat_model| StrOutputParser())
问题一:
semantic_rag_chain.invoke("Describe the Feature-based Approach with BERT?")################ RESPONSE ###################################The feature-based approach with BERT, as mentioned in the context, involves using BERT as a feature extractor for a downstream natural language processing task, specifically Named Entity Recognition (NER) in this case.To use BERT in a feature-based approach, the last 4 layers of BERT are concatenated to serve as the features for the task. This was found to be the most effective approach in Section 5.3 of the paper.The context also mentions that fine-tuning BERT is surprisingly robust to different masking strategies. However, when using the feature-based approach for NER, using only the MASK strategy was problematic. Additionally, using only the RND strategy performed much worse than the proposed strategy.In summary, the feature-based approach with BERT involves using the last 4 layers of BERT as features for a downstream NLP task, and fine-tuning these features for the specific task. The approach was found to be robust to different masking strategies, but using only certain strategies was problematic for NER.
问题二:
semantic_rag_chain.invoke("What is SQuADv2.0?")################ RESPONSE ###################################SQuAD v2.0, or Squad Two Point Zero, is a version of the Stanford Question Answering Dataset (SQuAD) that extends the problem definition of SQuAD 1.1 by allowing for the possibility that no short answer exists in the provided paragraph. This makes the problem more realistic, as not all questions have a straightforward answer within the provided text. The SQuAD 2.0 task uses a simple approach to extend the SQuAD 1.1 BERT model for this task, by treating questions that do not have an answer as having an answer span with start and end at the [CLS] token, and comparing the score of the no-answer span to the score of the best non-null span for prediction. The document also mentions that the BERT ensemble, which is a combination of 7 different systems using different pre-training checkpoints and fine-tuning seeds, outperforms all existing systems by a wide margin in SQuAD 2.0, even when excluding entries that use BERT as one of their components.
问题三:
semantic_rag_chain.invoke("What is the purpose of Ablation Studies?")################ RESPONSE ###################################Ablation studies are used to understand the impact of different components or settings of a machine learning model on its performance. In the provided context, ablation studies are used to answer questions about the effect of the number of training steps and masking procedures on the performance of the BERT model. By comparing the performance of the model under different conditions, researchers can gain insights into the importance of these components or settings and how they contribute to the overall performance of the model.
使用Naive Chunking策略实现RAG管道
naive_chunk_vectorstore = Chroma.from_documents(naive_chunks, embedding=embed_model)naive_chunk_retriever = naive_chunk_vectorstore.as_retriever(search_kwargs={"k" : 5})naive_rag_chain = ({"context" : naive_chunk_retriever, "question" : RunnablePassthrough()}| rag_prompt| chat_model| StrOutputParser())
PS:这里我们将使用k=5;这是为了对这两种策略进行“公平的比较”。
问题一:
naive_rag_chain.invoke("Describe the Feature-based Approach with BERT?")#############################RESPONSE##########################The Feature-based Approach with BERT involves extracting fixed features from the pre-trained BERT model, as opposed to the fine-tuning approach where all parameters are jointly fine-tuned on a downstream task. The feature-based approach has certain advantages, such as being applicable to tasks that cannot be easily represented by a Transformer encoder architecture, and providing major computational benefits by pre-computing an expensive representation of the training data once and then running many experiments with cheaper models on top of this representation. In the context provided, the feature-based approach is compared to the fine-tuning approach on the CoNLL-2003 Named Entity Recognition (NER) task, with the feature-based approach using a case-preserving WordPiece model and including the maximal document context provided by the data. The results presented in Table 7 show the performance of both approaches on the NER task.
问题二:
naive_rag_chain.invoke("What is SQuADv2.0?")#############################RESPONSE##########################SQuAD v2.0, or the Stanford Question Answering Dataset version 2.0, is a collection of question/answer pairs that extends the SQuAD v1.1 problem definition by allowing for the possibility that no short answer exists in the provided paragraph. This makes the problem more realistic. The SQuAD v2.0 BERT model is extended from the SQuAD v1.1 model by treating questions that do not have an answer as having an answer span with start and end at the [CLS] token, and extending the probability space for the start and end answer span positions to include the position of the [CLS] token. For prediction, the score of the no-answer span is compared to the score of the best non-null span.
问题三:
naive_rag_chain.invoke("What is the purpose of Ablation Studies?")#############################RESPONSE##########################Ablation studies are used to evaluate the effect of different components or settings in a machine learning model. In the provided context, ablation studies are used to understand the impact of certain aspects of the BERT model, such as the number of training steps and masking procedures, on the model's performance.For instance, one ablation study investigates the effect of the number of training steps on BERT's performance. The results show that BERT BASE achieves higher fine-tuning accuracy on MNLI when trained for 1M steps compared to 500k steps, indicating that a larger number of training steps contributes to better performance.Another ablation study focuses on different masking procedures during pre-training. The study compares BERT's masked language model (MLM) with a left-to-right strategy. The results demonstrate that the masking strategies aim to reduce the mismatch between pre-training and fine-tuning, as the [MASK] symbol does not appear during the fine-tuning stage. The study also reports Dev set results for both MNLI and Named Entity Recognition (NER) tasks, considering fine-tuning and feature-based approaches for NER.
语义块的Ragas评估比较
使用RecursiveCharacterTextSplitter拆分文档
synthetic_data_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=0,length_function=len,is_separator_regex=False)#synthetic_data_chunks = synthetic_data_splitter.create_documents([d.page_content for d in documents])print(len(synthetic_data_chunks))
创建以下数据集
- Questions——综合生成(grogq-mixtral-8x7b-32768)
- Contexts——上面创建的(合成数据块)
- Ground Truths——合成生成(grogq-mixtral-8x7b-32768)
- Answers——由我们的语义RAG链生成
questions = []ground_truths_semantic = []contexts = []answers = []question_prompt = """\You are a teacher preparing a test. Please create a question that can be answered by referencing the following context.Context:{context}"""question_prompt = ChatPromptTemplate.from_template(question_prompt)ground_truth_prompt = """\Use the following context and question to answer this question using *only* the provided context.Question:{question}Context:{context}"""ground_truth_prompt = ChatPromptTemplate.from_template(ground_truth_prompt)question_chain = question_prompt | chat_model | StrOutputParser()ground_truth_chain = ground_truth_prompt | chat_model | StrOutputParser()for chunk in synthetic_data_chunks[10:20]:questions.append(question_chain.invoke({"context" : chunk.page_content}))contexts.append([chunk.page_content])ground_truths_semantic.append(ground_truth_chain.invoke({"question" : questions[-1], "context" : contexts[-1]}))answers.append(semantic_rag_chain.invoke(questions[-1]))
PS:出于实验目的,我们只考虑了10个样本
将生成的内容格式化为HuggingFace数据集格式
from datasets import load_dataset, Datasetqagc_list = []for question, answer, context, ground_truth in zip(questions, answers, contexts, ground_truths_semantic):qagc_list.append({"question" : question,"answer" : answer,"contexts" : context,"ground_truth" : ground_truth})eval_dataset = Dataset.from_list(qagc_list)eval_dataset###########################RESPONSE###########################Dataset({features: ['question', 'answer', 'contexts', 'ground_truth'],num_rows: 10})
实施Ragas指标并评估我们创建的数据集。

from ragas.metrics import (answer_relevancy,faithfulness,context_recall,context_precision,)#from ragas import evaluateresult = evaluate(eval_dataset,metrics=[context_precision,faithfulness,answer_relevancy,context_recall,],llm=chat_model,embeddings=embed_model,raise_exceptions=False)
在这里,我曾尝试使用Groq来使用开源LLM。但出现了一个速率限制错误:
groq.RateLimitError: Error code: 429 - {'error': {'message': 'Rate limit reached for model `mixtral-8x7b-32768` in organization `org_01htsyxttnebyt0av6tmfn1fy6` on tokens per minute (TPM): Limit 4500, Used 3867, Requested ~1679. Please try again in 13.940333333s. Visit https://console.groq.com/docs/rate-limits for more information.', 'type': 'tokens', 'code': 'rate_limit_exceeded'}}
因此,将LLM重定向为使用OpenAI,这在RAGAS框架中默认使用。
设置OpenAI API密钥
import osfrom google.colab import userdataimport openaios.environ['OPENAI_API_KEY'] = userdata.get('OPENAI_API_KEY')openai.api_key = os.environ['OPENAI_API_KEY']
from ragas import evaluateresult = evaluate(eval_dataset,metrics=[context_precision,faithfulness,answer_relevancy,context_recall,],)result#########################RESPONSE##########################{'context_precision': 1.0000, 'faithfulness': 0.8857, 'answer_relevancy': 0.9172, 'context_recall': 1.0000}
#Extract the details into a dataframeresults_df = result.to_pandas()results_df

Naive Chunker的Ragas评估比较
import tqdmquestions = []ground_truths_semantic = []contexts = []answers = []for chunk in tqdm.tqdm(synthetic_data_chunks[10:20]):questions.append(question_chain.invoke({"context" : chunk.page_content}))contexts.append([chunk.page_content])ground_truths_semantic.append(ground_truth_chain.invoke({"question" : questions[-1], "context" : contexts[-1]}))answers.append(naive_rag_chain.invoke(questions[-1]))
制定Naive的分块评估数据集
qagc_list = []for question, answer, context, ground_truth in zip(questions, answers, contexts, ground_truths_semantic):qagc_list.append({"question" : question,"answer" : answer,"contexts" : context,"ground_truth" : ground_truth})naive_eval_dataset = Dataset.from_list(qagc_list)naive_eval_dataset############################RESPONSE########################Dataset({features: ['question', 'answer', 'contexts', 'ground_truth'],num_rows: 10})
使用RAGAS框架评估我们创建的数据集
naive_result = evaluate(naive_eval_dataset,metrics=[context_precision,faithfulness,answer_relevancy,context_recall,],)#naive_result############################RESPONSE#######################{'context_precision': 1.0000, 'faithfulness': 0.9500, 'answer_relevancy': 0.9182, 'context_recall': 1.0000}
naive_results_df = naive_result.to_pandas()naive_results_df###############################RESPONSE #######################{'context_precision': 1.0000, 'faithfulness': 0.9500, 'answer_relevancy': 0.9182, 'context_recall': 1.0000}
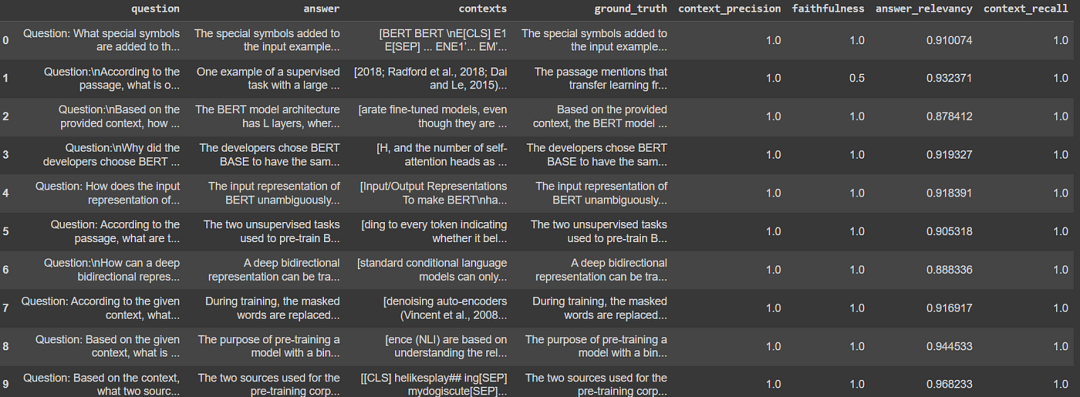
结论
我们可以看到,语义分块和Naive分块的结果几乎相同,只是Naive分块对答案的真实表示更好,与语义分块的0.88分相比,得分为0.95。
总之,语义分块能够对上下文相似的信息进行分组,从而能够创建独立且有意义的片段。这种方法通过为大型语言模型提供集中的输入,提高了它们的效率和有效性,最终提高了它们理解和处理自然语言数据的能力。
参考文献:
[1] https://console.groq.com/settings/limits?source=post_page-----f4733025d5f5--------------------------------
[2] https://docs.ragas.io/en/stable/concepts/metrics/index.html?source=post_page-----f4733025d5f5--------------------------------
[3] https://python.langchain.com/docs/modules/data_connection/document_transformers/semantic-chunker?source=post_page-----f4733025d5f5--------------------------------
这篇关于LLM之RAG实战(三十八)| RAG分块策略之语义分块的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




