本文主要是介绍RabbitMQ 教程译文(二) + 学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文地址
以下图片,除了特殊声明的,其他均来自官网教程
工作队列
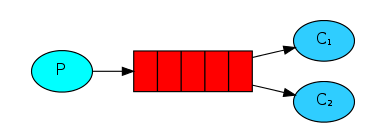
在第一篇教程中,我们完成了从一个队列中发送和接收信息的程序。在本篇教程中,我们会创建一个工作队列Work Queue,我们会通过这个队列向多个节点发送比较耗时的任务。
工作队列的核心思想就是避免立即处理比较耗时的操作,然后阻塞等待处理结果。我们会将任务封装成一个信息存储在队列中,然后延后处理任务。一个工作进程会在后台弹出队列中的任务,并完成该任务。当你运行多个工作进程的时候,任务就会分发给他们。
这个概念特别适合web应用,因为web应用不可能再很短的请求窗口中处理完成复杂的任务。
准备
在之前的教程中,我们发送一条“Hello World”信息。现在我们需要发送一条表示复杂任务的信息。我们没有一个真实环境下的复杂任务,比如调整图片大小、渲染PDF文件,所以我们通过*Thread.sleep()*方法表示任务的复杂程度。我们会在发送信息的字符串中加入若干个“点”,“点”的多少就表示任务的复杂度。每一个“点”就表示一秒钟的工作,比如“Hello…”表示一个需要花费三秒的任务。
我们会稍微修改下之前的“Send.java”代码,以便可以通过命令行发送特定的信息。这个程序将会把我们的任务放到队列中,所以我们命名它为“NewTask.java”。
String message = String.join(" ", argv);channel.basicPublish("", "hello", null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
我们原来的“Recv.java”也需要修改,以便可以根据信息中的“点”来模拟工作时间。这个程序会处理信息,所以我们叫它“Worker.java”。
DeliverCallback deliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [x] Received '" + message + "'");try {doWork(message);} finally {System.out.println(" [x] Done");}
};
boolean autoAck = true; // acknowledgment is covered below
channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, consumerTag -> { });
我们的模拟工作代码
private static void doWork(String task) throws InterruptedException {for (char ch: task.toCharArray()) {if (ch == '.') Thread.sleep(1000);}
}
循环调度
One of the advantages of using a Task Queue is the ability to easily parallelise work. If we are building up a backlog of work, we can just add more workers and that way, scale easily.
任务队列的一个优势是很容易完成并行工作。如果我们任务堆积的越来越多,那我们只需要增加工作节点就可以了,规模很好控制。
首先,我们一次运行两个工作节点,它们都会从队列中接收到信息,但是实际情况呢?
打开两个控制台,分别运行两个工作节点C1 C2,在第三个控制台运行NewTask,发送信息,观察C1 C2的控制台。我们发现信息是依次交替的发送给两个工作节点。
默认情况下,RabbiMQ会依次交替的发送给所有的消费者,平均情况下,每个消费者接收到的信息数量是一样的。这种发送信息的方式叫做 循环发送round-robin。
信息应答
处理一个任务会花费一定的时间。你可能想知道如果一个消费者在处理一个比较耗时的任务时死掉的话要怎么办?在我们现有代码的情况下,一旦RabbitMQ发送信息给消费者,它就会马上标记这条信息然后删除信息。在这种情况下,如果你kill一个正在处理消息的消费者,那么它正在处理的信息也会丢失。该消费者接收到的,还没有处理的信息也会丢失。
但是我们不希望丢失任何任务,我们希望当一个节点死掉的时候可以把任务发送给其他节点。
为了保证信息不回丢失,RabbitMQ提供了信息应答机制,一个ack(信息应答)就是消费者发送给RabbitMQ,通知其某个信息已经被接收或者处理,然后RabbitMQ就可以放心的删除信息了。
如果一个消费者没有个ack就挂掉了,那么RabbitMQ会认为某个信息是没有完全被处理的,所以会将该信息重新入队列。如果当前正好有其他消费者,那么就会立刻发送该条信息给消费者。这样就可以保证当消费者偶尔挂掉也不会丢失信息。
不会有任何信息超时;RabbitMQ会重新分发信息当消费者挂掉。如果处理信息需要花费很长时间也是没有关系的。
手动信息应答Manual message acknowledgments默认是开启的,前面的例子我们通过设置autoAck = true关闭了手动信息应答,现在我们设置这个标识为false,然后在我们完成任务的时候发送一个合适的应答信息。
channel.basicQos(1); // accept only one unack-ed message at a time (see below)DeliverCallback deliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [x] Received '" + message + "'");try {doWork(message);} finally {System.out.println(" [x] Done");channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);}
};
boolean autoAck = false;
channel.basicConsume(TASK_QUEUE_NAME, autoAck, deliverCallback, consumerTag -> { });
使用这段代码就可以保证当你杀掉消费者时也不会丢失掉任何信息,在消费者挂掉后,没有收到应答的信息会被重新分发。
应答信息发送使用的通道必须和接收信息使用的通道一致,否则会报通道协议相关的异常,详情见doc guide on confirmations
忘记应答
忘记发送应答信息是一种很容易发生的错误,但是后果却是严重的,虽然没有应答的信息将会重新发送,但是RabbitMQ会使用越来越多的内存来存储没有应答的信息。
为了定位这种问题,我们可以使用rabbitmqctl命令来打印未应答信息域messages_unacknowledged
信息持久化
我们已经知道,当消费者挂掉怎么保证信息不丢失。但是当RabbitMQ挂掉还是会丢失信息。
当RabbitMQ挂掉,它会丢失队列和信息,除非我们不让它这么做。有两个条件可以保证信息不丢失,它们就是队列和信息,只有保证它们持久化才可以保证信息不丢失。
首先,我们需要保证RabbitMQ不会丢失队列,为了保证队列不丢失,我们需要声明队列为持久的。
boolean durable = true;
channel.queueDeclare("hello", durable, false, false, null);
虽然上述代码是正确的,但是它在我们的代码下是无效的,这是因为我们已经声明了一个不持久的“hello”的队列,RabbitMQ不允许对已经存在的队列进行不同参数的重新定义,任何这样的操作RabbitMQ会返回错误信息。但是这里有一个快速的解决方案,重新声明一个不同名称的队列。
boolean durable = true;
channel.queueDeclare("task_queue", durable, false, false, null);
生产者和消费者中的队列声明都需要做相应修改。
至此,我们可以保证当RabbitMQ重启时不会丢失队列。现在我们需要保证我们的信息也是持久化的,只需要设置MessageProperties(实现了BasicProperties)的值为PERSISTENT_TEXT_PLAIN。
import com.rabbitmq.client.MessageProperties;channel.basicPublish("", "task_queue",MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());
关于信息持久化
向上述中的信息持久化操作并不保证信息一定不会丢失,虽然上面的设置已经告诉RabbitMQ要存储信息到硬盘,但是还存在很短的时间,RabbitMQ收到信息但是还没有存储到硬盘,所以上述的持久化不是一定的,但是它已经足够我们的简单任务队列了,如果你希望一个更有保证的持久化设置,那么你可以使用 publisher confirms.
公平分发
你可能注意到了现在的分发策略还没有向我们希望的那样工作。比如,某个场景下有两个消费者,当所有的奇数编号的信息都很复杂,偶数编号的信息都很简单,那么一个消费者就会非常忙,而另一个则非常轻松。然而RabbitMQ并不知道这些,它还会继续按照当前策略继续发送信息。
这种情况的发生是因为当信息进入队列时RabbitMQ就会分发信息。它并不会检查消费者还没有应答的信息数量。RabbitMQ只是盲目的将第n条信息发送给第n个消费者。
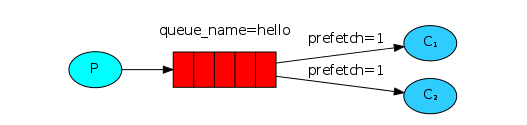
为了打破这种情况,我们使用设置了prefetchCount = 1的basicQos方法。这样就会通知RabbitMQ不要在同一时间给同一个消费者多条信息,也就是说,不要把信息发送给还没有处理完信息的消费者。这条信息会发送给空闲消费者。
int prefetchCount = 1;
channel.basicQos(prefetchCount);
注意队列长度
当所有消费者都处于忙碌状态,那么你的队列可能会被充满,所以你可能需要监控队列情况,可能增加消费者或者指定其他策略。
合体!!!
下面是“NewTask.java”和“Worker.java”的完整代码
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.MessageProperties;public class NewTask {private static final String TASK_QUEUE_NAME = "task_queue";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");try (Connection connection = factory.newConnection();Channel channel = connection.createChannel()) {channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);String message = String.join(" ", argv);channel.basicPublish("", TASK_QUEUE_NAME,MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes("UTF-8"));System.out.println(" [x] Sent '" + message + "'");}}}
import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.DeliverCallback;public class Worker {private static final String TASK_QUEUE_NAME = "task_queue";public static void main(String[] argv) throws Exception {ConnectionFactory factory = new ConnectionFactory();factory.setHost("localhost");final Connection connection = factory.newConnection();final Channel channel = connection.createChannel();channel.queueDeclare(TASK_QUEUE_NAME, true, false, false, null);System.out.println(" [*] Waiting for messages. To exit press CTRL+C");channel.basicQos(1);DeliverCallback deliverCallback = (consumerTag, delivery) -> {String message = new String(delivery.getBody(), "UTF-8");System.out.println(" [x] Received '" + message + "'");try {doWork(message);} finally {System.out.println(" [x] Done");channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);}};channel.basicConsume(TASK_QUEUE_NAME, false, deliverCallback, consumerTag -> { });}private static void doWork(String task) {for (char ch : task.toCharArray()) {if (ch == '.') {try {Thread.sleep(1000);} catch (InterruptedException _ignored) {Thread.currentThread().interrupt();}}}}
}
打完收工 ~~~
这篇关于RabbitMQ 教程译文(二) + 学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









