本文主要是介绍内核级python:编译器的词法和语法解析基本原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
python在收到代码内容后,首先要启动两个流程,分别为词法解析和语法解析。看过我编译原理课程的同学对这两个流程应该不陌生。词法解析其实就是把代码里面不同的元素分别归类,例如234,1.35,1e3等这类字符串统一用一个标志或数字来表示,通常它们的标志为NUMBER,对应字符串pi, age等这类变量名统一用标志来表示,例如使用NAME,于是整篇代码会一下子浓缩成一系列标志的排列,例如表达式 a = 100 + 10 就变成了 NAME = NUMBER + NUMBER。
接下来就要根据标志之间的排列组合来分析它们所表达的逻辑,这种分析过程往往把标志直接的逻辑联系使用树状结构表达出来,例如表达式"a+1"它对应的树状结构为:
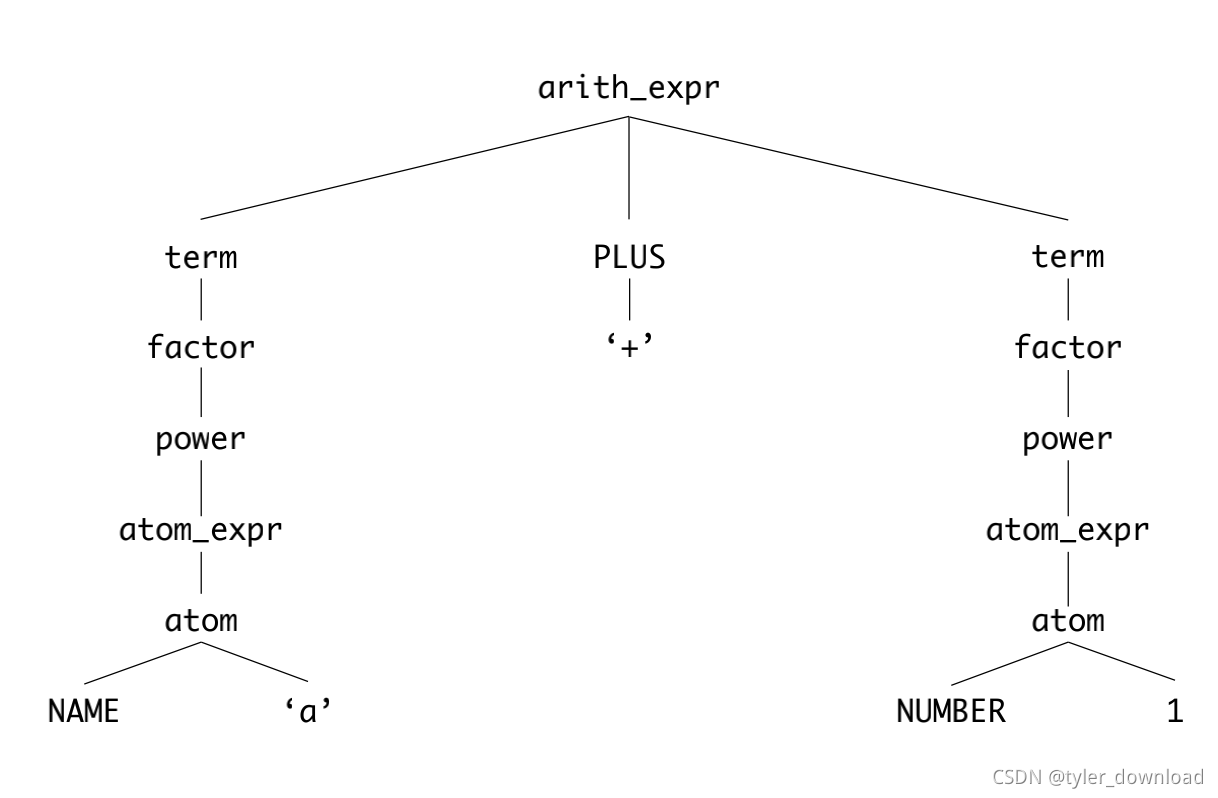
这个过程叫语法解析,想进一步了解编译原理算法的同学可以点击这里
语法解析本质上是通过预定规则解析符号组合所形成的逻辑,例如上面的语法解析树的构建来自于如下语法:
arith_expr : term (('+'|'-') term)*
tem: factor (('*' | '@' | '/'| '%'|'//' factor)*
...
arith_expr 表示由加号或减号连接起来的算术表达式,term表示由*或/连接起来的算术表达式,上面的表达式也称为巴斯特范式,最早使用在fortran语言编译器的设计上,上面的表示式会一直往下解析,直到遇到不能再解析的token为止,没有编译原理经验的同学对这里的描述可能会很困惑,可以查看上面的链接来获取相关知识。
我们看看python语法中有哪些表达式定义和token定义,执行python工程,然后像下图那样输入相应代码:
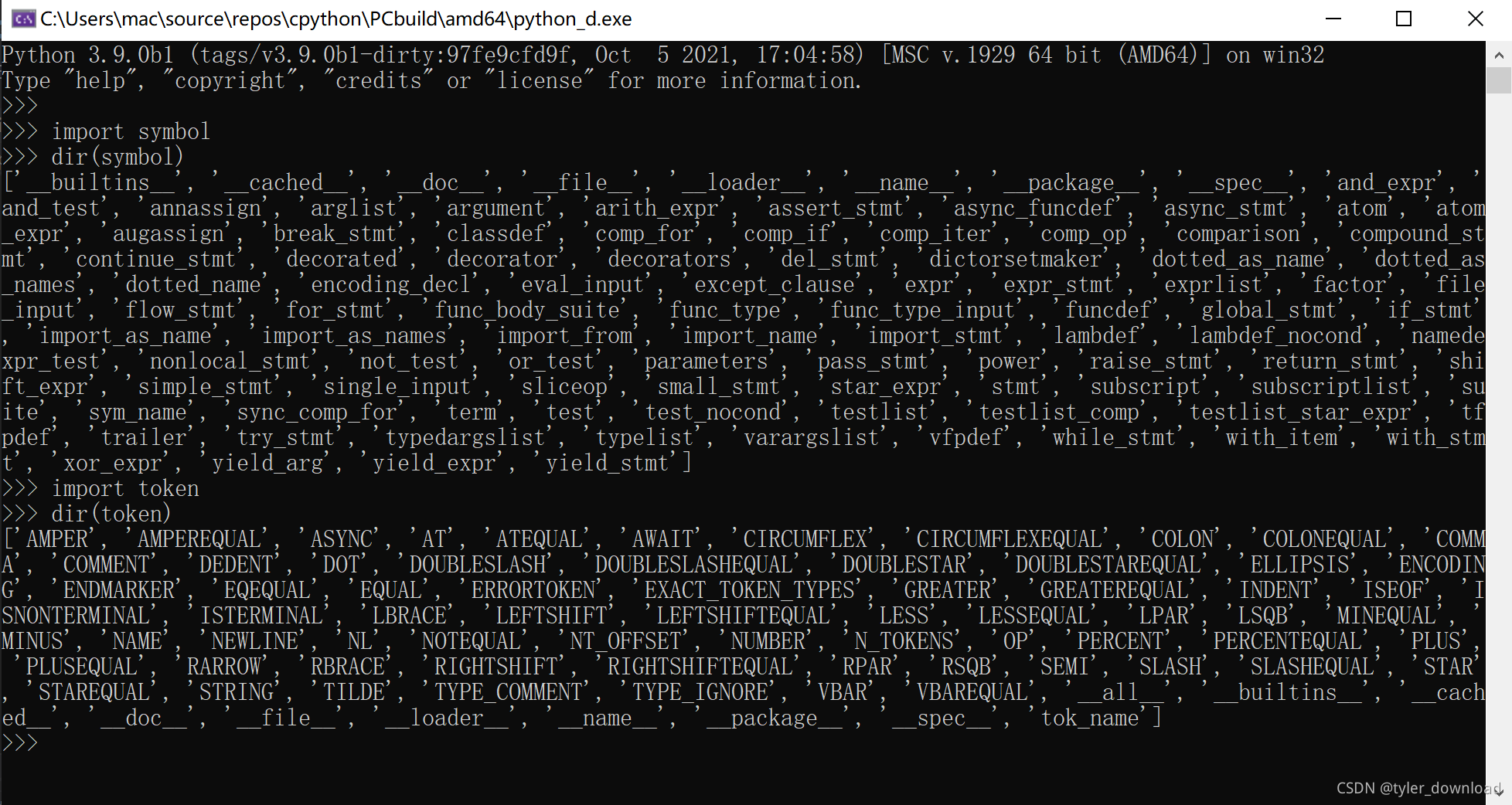
上图中通过代码分别导入symbol和token然后将他们打印出来。我们可以直接调用Python编译器提供的接口执行代码的语法解析过程:
···
import symbol
import token
import parser
from pprint import pprint
def lex(expression):
symbols = {v: k for k, v in symbol.dict.items() if isinstance(v, int)} #获取所有表达式符号
tokens = {v: k for k, v in token.dict.items() if isinstance(v, int)} #获取所有标识符
lexicon = {**symbols, **tokens}
st = parser.expr(expression) #解析表达式,返回解析过程中遇到的表达式符号对应的数字
st_list = parser.st2list(st) #将表达式符号对应数字替换成字符串
def replace(l: list):r = []for i in l:if isinstance(i, list):r.append(replace(i))else:if i in lexicon:r.append(lexicon[i])else:r.append(i)return r
return replace(st_list)
pprint(lex(‘a + 1’))
···
上面代码运行后输出结果如下:
['eval_input',['testlist',['test',['or_test',['and_test',['not_test',['comparison',['expr',['xor_expr',['and_expr',['shift_expr',['arith_expr',['term',['factor', ['power', ['atom_expr', ['atom', ['NAME', 'a']]]]]],['PLUS', '+'],['term',['factor',['power', ['atom_expr', ['atom', ['NUMBER', '1']]]]]]]]]]]]]]]]],['NEWLINE', ''],['ENDMARKER', '']]
像eval_input, testlist等都对应上下文无关语法表达式中的表达式符号,它属于编译原理的核心内容,编译器根据这些符号的递归关系来构建DFA,也就是有限状态自动机,然后将标识符输入自动机来构建前面的语法解析树。
编译原理的内容总是比较晦涩,没有涉及过这方面内容的同学在读起来肯定会头皮发麻。在编译原理领域有一本经典叫“龙书”,它的地位相当于佛学中的金刚经,如果你没有一定编译原理基础就直接读它的话,我估计你会吐血而亡。为了减少编译原理的晦涩属性,我们看看一个具体例子,这里我们给Python语法添加一个比较操作符~=,也就是约等于,例如1 == 1.01会返回False,但使用 1 ^= 1.01就能返回True。
这部分功能我在windows上反复尝试发现走不通,需要在linux上才可以,我们可以在Linux上下载同样的代码,或者把当前代码路径共享到linux虚拟机里,然后执行如下命令产生makefile文件:
./configure --with-pydebug
然后本地就会生成makefile文件,但是此时我们先不要编译,首先要做的是进入到Grammar路径,打开Grammar文件做如下修改:
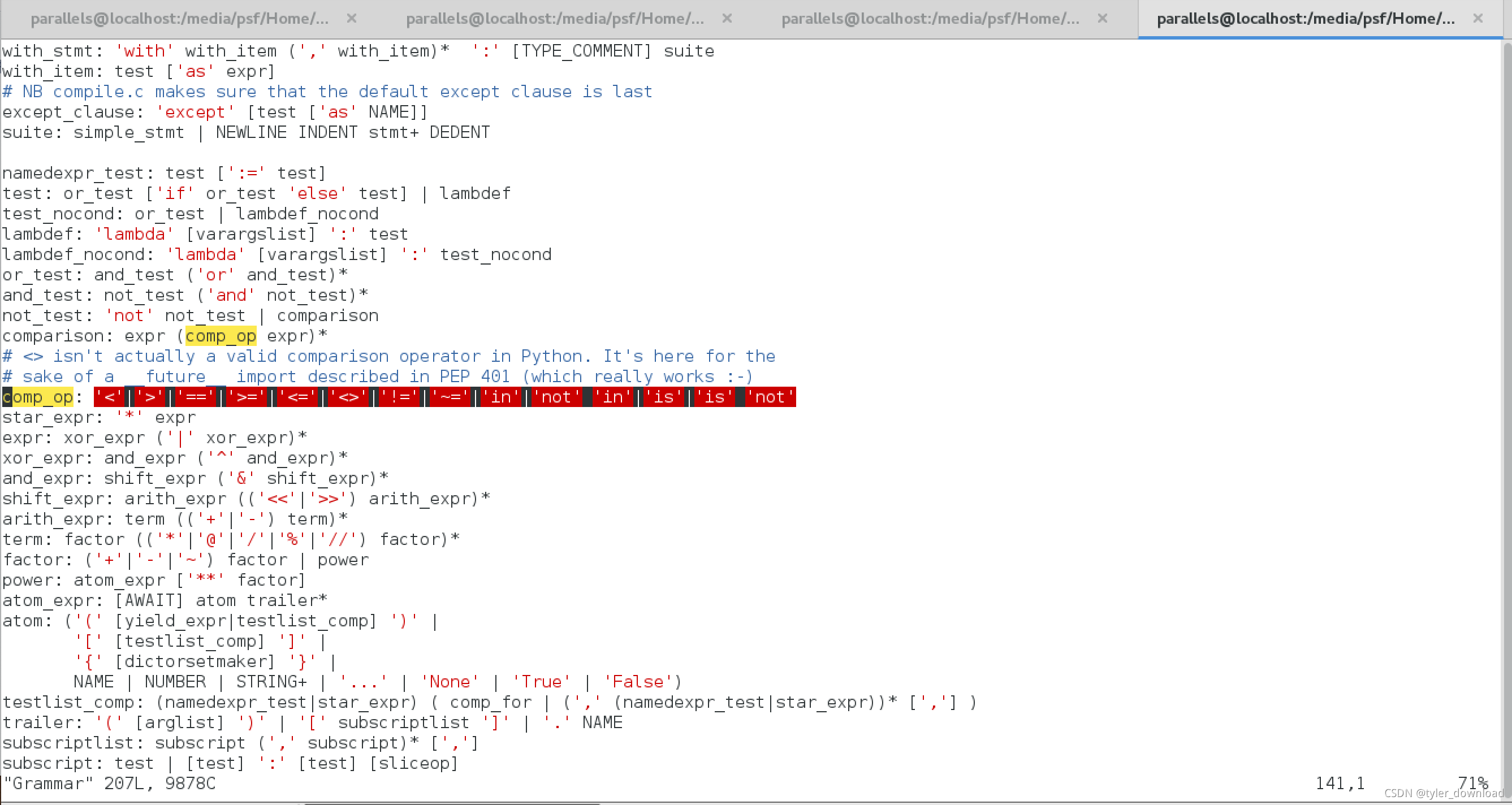
comp_op表示比较操作符,它用于比较两个表达式的结果的对应关系,>=, <= , <, >等符号都是比较表达式符号,这里我们增加了一个”约等于“比较符,也就是"~=",完成后在回到根目录执行:
make regen-all
完成后在Parser/Token.c中的PyToken_TwoChars函数会增加一段代码:
 修改这里后编译器就能识别符号“~=”,但是它还不知道遇到这个符号后应该做什么,因此我们需要修改语法部分,进入到Paser目录,打开Python.asdl文件,找到cmpop的定义进行进行如下修改:
修改这里后编译器就能识别符号“~=”,但是它还不知道遇到这个符号后应该做什么,因此我们需要修改语法部分,进入到Paser目录,打开Python.asdl文件,找到cmpop的定义进行进行如下修改:

这里的目的实际上是给操作符“~="定义一个标志符,编译器在识别到符号”~=“会给它赋予一个数值,然后代码遇到相应数值时就触发相应操作,实际上Eq, NotEq等其实都对应相应的数值,完成修改后再回到根目录执行:
make regen-ast
执行完后进入Include/目录,打开Python-ast.h就可以看到AlE对应的赋值:
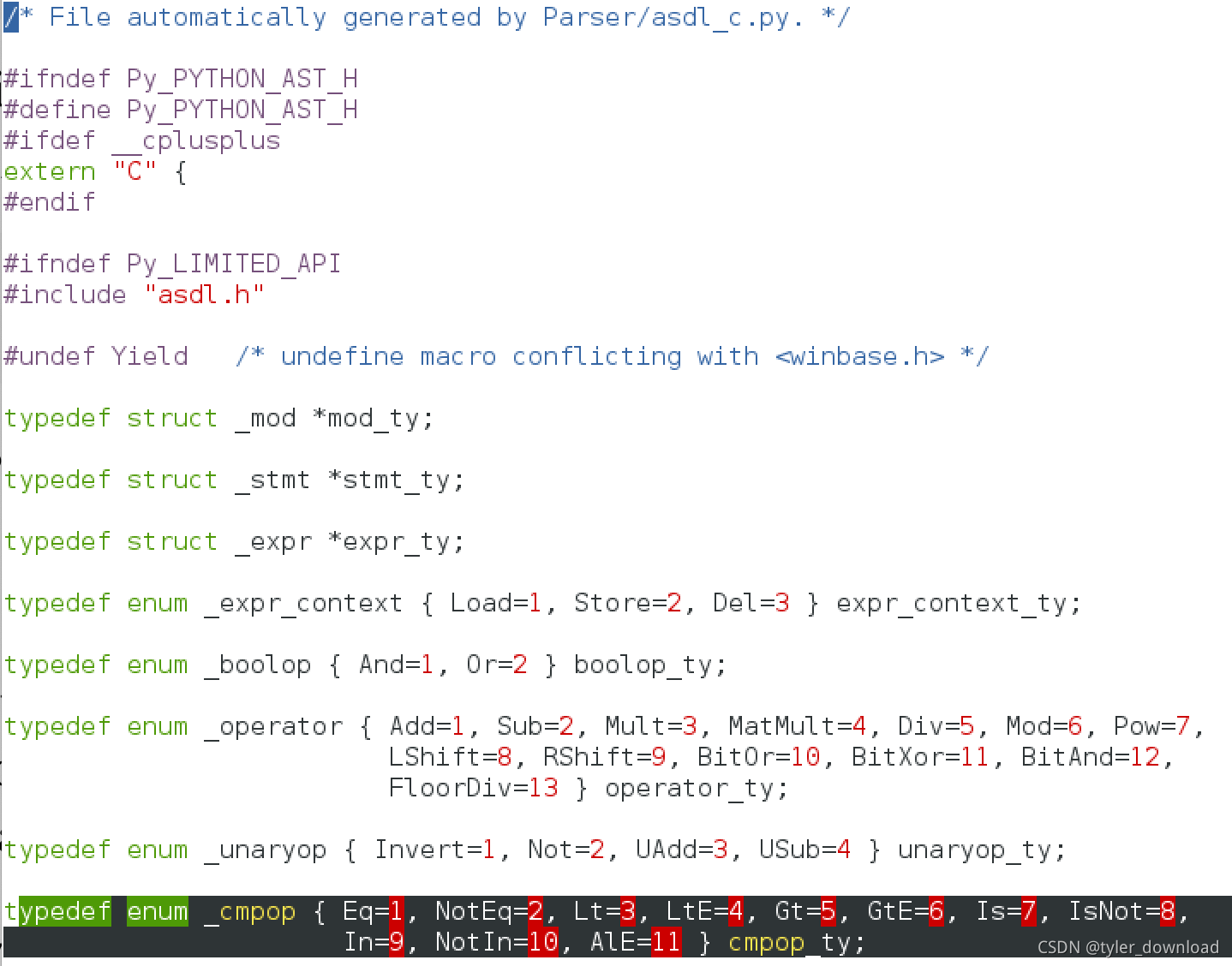
接着我们再次进入Python/目录,打开ast.c做如下修改,在第1199行对应ast_for_comp_op函数,这个函数用来告诉编译器如何识别比较操作符,增加如下代码: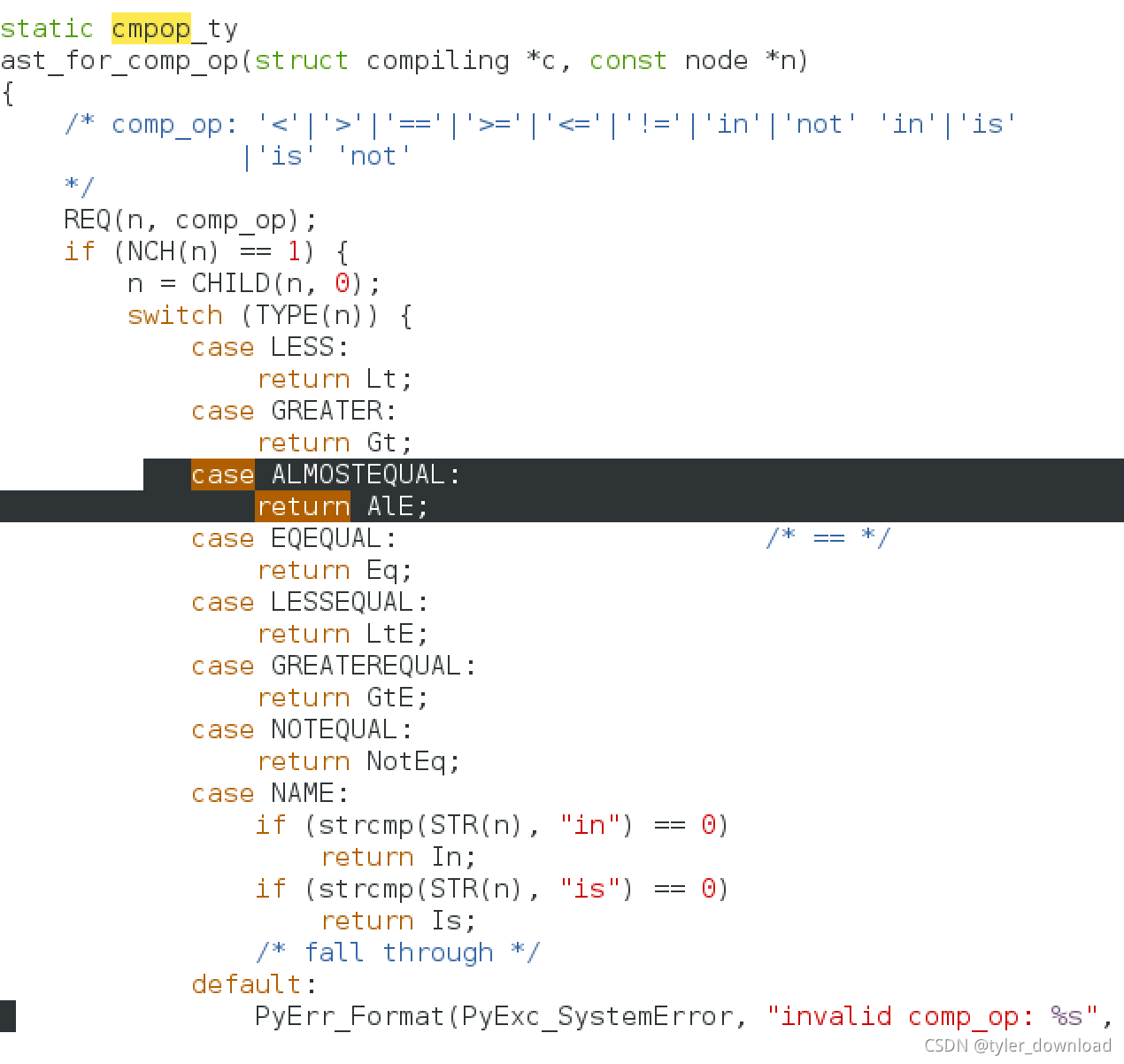
这里的逻辑实际上是让编译器遇到符号"~="时将其转换为数值定义,也就是标识符"AlE"对应的数值,后面我们再进行语法解析时,遇到该数值,我们就知道当前代码读取到了符号”~=“,然后我们就可以采取相应动作,到这里我们就可以将代码全部编译一遍,在根目录执行:
make -j2
过一会编译好后,会在本地目录生成python.exe可执行文件,我们启动它,同时必须附带-X oldparser参数,不然修改不起作用:
./python.exe -X oldparser
然后在命令行中输入 1~=2,点击回车,结果如下:
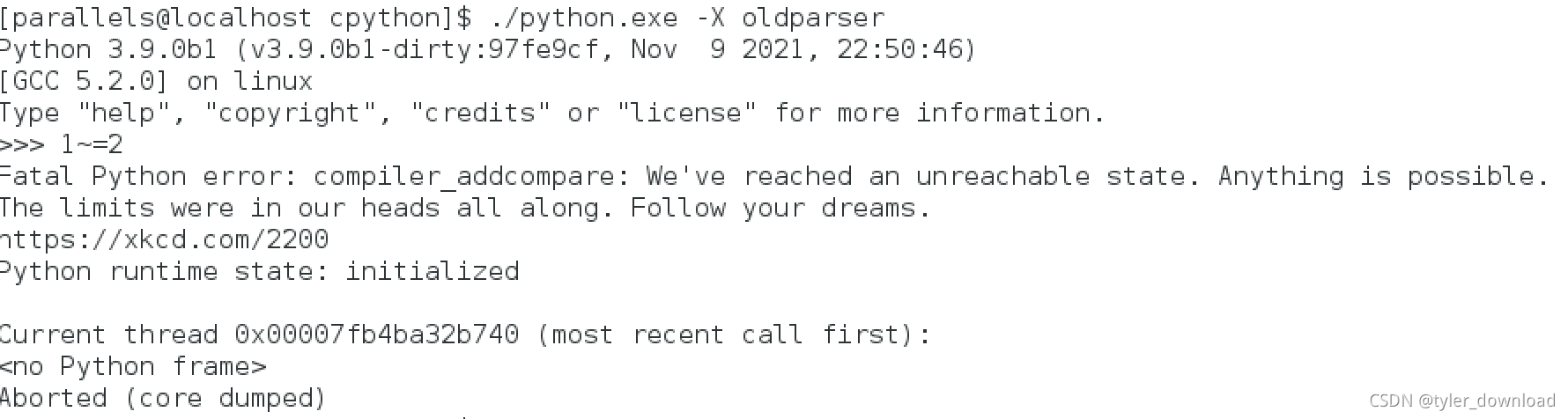
可以看到编译器奔溃了,其原因在于我们并没有告诉编译器遇到操作符"~=“时它应该执行什么逻辑,我们仅仅让它意识到”~=“是一个比较操作符而已,了解编译原理算法的同学会知道,编译器会根据语法定义构建有限状态自动机,然后每读取一个标志符,状态机就会进入下一个状态,现在我们让编译器能够读取标识符AlE,也就是对应”~=",但是我们没有定义这个遇到这个标识符后下一步的走向,所以状态机遇到这个标识符后,没有下一个状态可以跳转,后面我们再处理这个问题,我们可以输入以下代码看看情况:
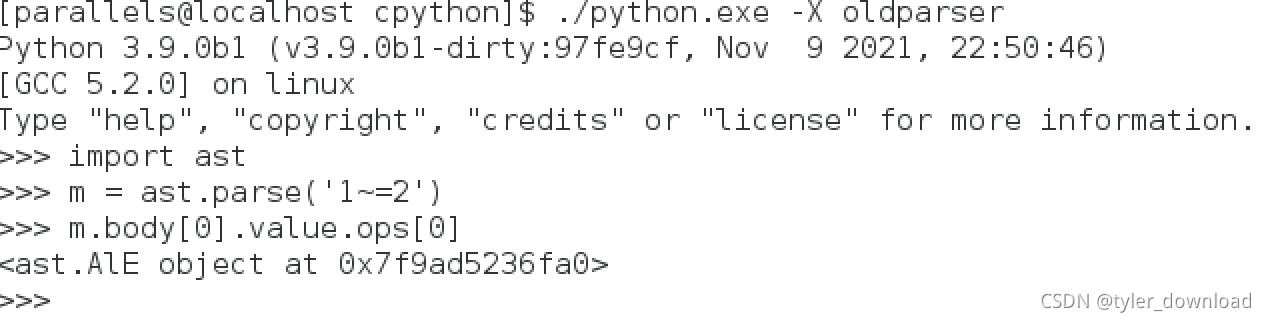
这里表明语法解析器已经能够识别符号"~=",只不过它不知道识别到这个符号后该怎么办而已,后面我们再添加处理该符号的相应逻辑,有关编译原理算法的更多信息点击这里
这篇关于内核级python:编译器的词法和语法解析基本原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





